IT/모바일
자연어 기술의 민주화(!)를 추구하는 허깅페이스(Hugging Face)의 오픈 소스 '트랜스포머 라이브러리'는 자연어 처리(NLP) 커뮤니티에서 인기가 많습니다. 여러 NLP 및 자연어 이해(NLU) 태스크에 매우 유용하고 강력한 것이 특징이죠.
라이브러리에는 100개 이상의 언어로 사전 학습된 다양한 모델이 포함되어 있습니다. 뭐니뭐니해도 트랜스포머 라이브러리의 많은 장점 중 하나는 파이토치 및 텐서플로와 모두 호환된다는 것입니다.
그냥 트랜스포머라고만 하면 그 개념이 조금 헷갈릴수도 있겠습니다. 그래서 잠깐 정리하자면, 허깅페이스의 트랜스포머 라이브러리는 다양한 트랜스포머 모델과 학습 스크립트를 제공하는 모듈이라고 생각하면 되겠습니다.
그러니까 '트랜스포머'는 신경망 아키텍처고, 그런 트랜스포머 아키텍처를 활용이 쉽게 여럿 모아 둔 것이 '허깅페이스의 트랜스포머 라이브러리'라고 생각하면 되겠습니다.
트랜스포머란?
구글의 연구원들이 2017년 논문에서 시퀀스 모델링을 위한 새로운 신경망 아키텍처를 제안했습니다. 트랜스포머(Transformer)라는 이름의 이 아키텍처는 기계 번역 작업의 품질과 훈련 비용 면에서 순환 신경망(RNN)을 능가했습니다.
동시에 효율적인 전이 학습 방법인 ULMFiT가 매우 크고, 다양한 말뭉치에서 LSTM 신경망을 훈련해 매우 적은 양의 레이블링된 데이터로도 최고 수준의 텍스트 분류 모델을 만들어냄을 입증했습니다. 이런 발전이 오늘날 가장 유명한 두 트랜스포머의 촉매가 됐습니다.
바로 GPT(Generative Pretrained Transformer)와 BERT(Bidirectional Encoder Representations from Transformers)입니다.
이 모델은 트랜스포머 아키텍처와 비지도 학습을 결합해 작업에 특화된 모델을 밑바닥부터 훈련할 필요를 없애고, 거의 모든 NLP 벤치마크에서 큰 차이로 기록을 경신했습니다.
GPT와 BERT가 릴리스된 후 다양한 트랜스포머 모델이 등장했는데, 그중 주목해야 할 모델의 등장 시기는 다음 그림과 같습니다.
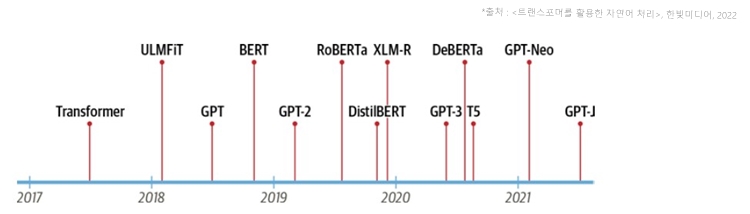
[그림 1] 트랜스포머 모델의 타임라인
트랜스포머 유니버스
트랜스포머 모델의 주요 유형은 인코더, 디코더, 인코더-디코더 세 가지입니다. 초기 트랜스포머 모델의 성공은 이후 폭발적인 모델들의 개발로 이어졌습니다. (가히 캄브리아기 대폭발급!!이라고 할 수 있었죠.)
연구자들은 사전 훈련용으로 다양한 크기와 특성의 데이터셋에서 모델을 개발하고 아키텍처를 수정해 성능을 높였습니다. 모델의 종류가 빠르게 늘고 있지만 여전히 크게는 앞서 언급한 세 유형으로 나눌 수 있습니다.
트랜스포머 가계도
세 개의 주요 아키텍처는 시간이 지나면서 자생적으로 진화했습니다. 다음 그림에 가장 유망한 모델과 그 후손을 표기해 봤습니다.
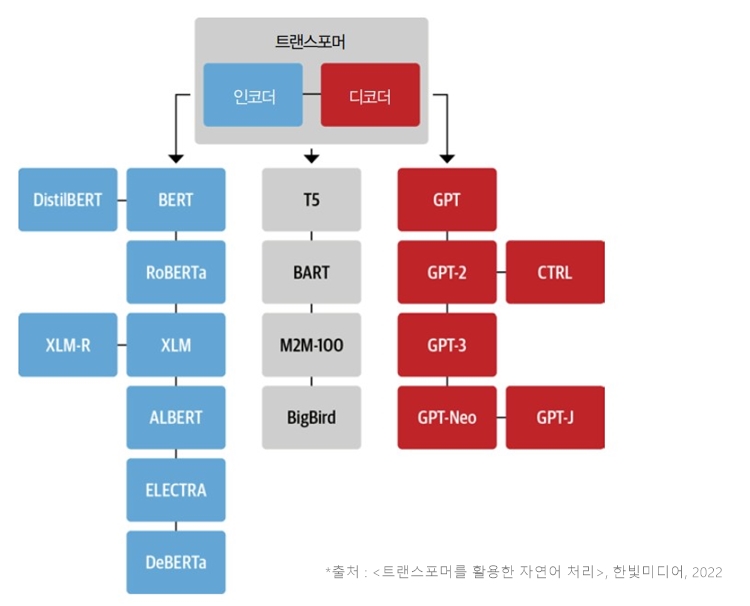
[그림 2] 가장 대표적인 트랜스포머 아키텍처
트랜스포머스에 있는 아키텍처는 50개가 넘는데 그중 중요한 몇 개만 그림에 표시했습니다.
인코더 유형
트랜스포머 아키텍처를 기반으로 한 첫 번째 인코더 유형의 모델은 BERT입니다. 이 모델이 공개될 당시에는 유명한 GLUE 벤치마크에서 최상의 모델을 모두 능가했습니다. 이 벤치마크는 난이도가 다양한 작업으로 자연어 이해(NLU)를 측정합니다.
그 후 성능을 더 향상시키기 위해 BERT의 사전 훈련 목표와 구조가 조정됐습니다. 인코더 유형의 모델은 여전히 연구와 산업 분야 NLU 작업에서 지배적입니다. 텍스트 분류, 개체명 인식, 질문 답변 등이 이에 속합니다.
BERT
BERT의 사전 훈련 목표 두 가지는 텍스트에서 마스킹된 토큰을 예측하는 것과 한 텍스트 구절이 다른 텍스트 구절 뒤에 나올 확률을 판단하는 것입니다. 전자의 작업을 마스크드 언어 모델링(MLM)이라 하고 후자를 다음 문장 예측(NSP)이라 합니다.
DistilBERT
BERT가 훌륭한 결과를 제공하지만, 모델 크기 때문에 지연시간이 짧아야 하는 환경에는 배포하기 어렵습니다. DistilBERT는 사전 훈련 과정에서 지식 정제(knowledge distillation)라는 기술을 사용해서 BERT보다 40% 더 적은 메모리를 사용하고 60% 더 빠르면서 BERT 성능의 97%를 달성합니다.
RoBERTa
BERT가 공개된 후 이어진 연구에서 사전 훈련 방법을 수정하면 성능이 더 향상된다는 사실이 밝혀졌습니다. RoBERTa는 더 많은 훈련 데이터로 더 큰 배치에서 더 오래 훈련하며 NSP 작업을 포함하지 않습니다. 이런 변경을 통해 원래 BERT 모델에 비해 성능이 크게 향상됐습니다.
XLM
GPT 유사 모델의 자기회귀 언어 모델링과 BERT의 MLM을 포함해 XLM(cross-lingual languagemodel)에서 다중 언어 모델을 만들기 위한 사전 훈련 방법이 연구됐습니다. XLM 사전 훈련 논문의 저자들은 MLM을 다중 언어 입력으로 확장한 TLM(translation language modeling)을 소개하기도 했죠.
이런 사전 훈련 작업을 실험한 저자들은 번역 작업을 포함해 여러 가지 다중 언어 NLU 벤치마크에서 최상의 결과를 이끌어 냈습니다.
XLM-RoBERTa
XLM와 RoBERTa의 뒤를 이어 XLM-RoBERTa나 XLM-R 모델이 훈련 데이터를 대규모로 확장해 다중 언어 사전 훈련을 한 단계 더 발전시켰습니다. 커먼 크롤(https://commoncrawl.org/) 말뭉치를 사용해 2.5 테라바이트의 텍스트 데이터를 만들었는데요. 그다음 이 데이터셋에서 MLM으로 인코더를 훈련했습니다.
이 데이터셋에는 상대 텍스트(즉, 번역)가 없는 데이터만 포함하기 때문에 XML의 TML 목표가 제외됐습니다. 이 모델은 특히 데이터가 부족한 언어에서 XML과 다중 언어 BERT 변종을 큰 차이로 앞질렀습니다.
ALBERT
이 모델은 인코더 구조를 더욱 효율적으로 만들기 위해 세 가지를 바꿨습니다.
첫째, 은닉 차원에서 토큰 임베딩 차원을 분리해 임베딩 차원을 줄입니다. 이로 인해 어휘사전이 큰 경우 파라미터가 절약됩니다. 둘째, 모든 층이 동일한 파라미터를 공유함으로써 실제 파라미터 개수를 크게 줄입니다. 셋째, NSP 목표를 문장 순서 예측으로 바꿉니다. 즉 모델은 두 문장이 함께 속해 있는지가 아니라 연속된 두 문장의 순서가 바뀌었는지를 예측합니다.
이런 변경을 통해 더 적은 파라미터로 더 큰 모델을 훈련하고 NLU 작업에서 뛰어난 성능을 달성하게 됩니다.
ELECTRA
표준적인 MLM 사전 훈련 목표는 각 훈련 스텝에서 마스킹된 토큰 표현만 업데이트되고 그 외 입력 토큰은 업데이트되지 않는다는 제약이 있습니다. 이 문제를 해결하기 위해 ELECTRA는 두 개의 모델을 사용합니다.
(대개 작은 규모의) 첫 번째 모델은 표준적인 마스크드 언어 모델처럼 동작해 마스킹된 토큰을 예측합니다. 판별자(discriminator)란 이름의 두 번째 모델은 첫 번째 모델의 출력에 있는 토큰 중 어떤 것이 원래 마스킹된 것인지 예측하는 작업을 수행합니다.
따라서 판별자는 모든 토큰에 이진 분류를 수행하는데, 이를 통해 훈련 효율을 30배 높입니다. 판별자는 후속 작업을 위해 표준 BERT 모델처럼 미세 튜닝됩니다.
DeBERTa
이 모델은 두 가지 구조 변경이 있습니다. 첫째, 각 토큰이 두 개의 벡터로 표현됩니다. 하나는 콘텐츠용이고 하나는 상대 위치를 위한 것입니다. 토큰 콘텐츠와 상대 위치를 분리하면 셀프 어텐션 층이 인접한 토큰 쌍의 의존성을 더 잘 모델링합니다. 한편 단어의 절대 위치는 특히 디코딩에 중요합니다. 이런 이유로 토큰 디코딩 헤드의 소프트맥스 층 직전에 절대 위치 임베딩을 추가합니다.
DeBERTa는 (앙상블로) SuperGLUE 벤치마크에서 사람의 성능을 추월한 최초의 모델입니다. 이 벤치마크는 NLU 성능을 측정하는 여러 하위 작업으로 구성되며 더 어려운 버전의 GLUE입니다.
주요 인코더 유형의 아키텍처를 살펴봤으니 이제 디코더 유형의 모델을 보겠습니다.
디코더 유형
OpenAI는 트랜스포머 디코더 모델의 발전을 주도했습니다. 이런 모델은 특히 문장에서 다음 단어를 예측하는 데 뛰어나므로 대부분 텍스트 생성 작업에 사용됩니다. 더 큰 데이터셋을 사용하고 언어 모델을 더 크게 만드는 식으로 발전이 가속됐습니다. 이 흥미로운 생성 모델의 진화를 살펴보겠습니다.
GPT
GPT는 NLP에서 두 가지 핵심 개념, 즉 새롭고 효율적인 트랜스포머 디코더 아키텍처와 전이 학습을 결합했습니다. 이런 설정에서 모델은 이전 단어를 기반으로 다음 단어를 예측하도록 훈련됩니다. 이 모델은 BookCorpus에서 훈련되고 분류와 같은 후속 작업에서 뛰어난 결과를 달성했습니다.
GPT-2
간단하고 확장이 용이한 사전 훈련 방식의 성공에 힘입어, 원본 모델과 훈련 세트를 확장해 만든 모델입니다. GPT-2 모델은 일관성 있는 긴 텍스트 시퀀스를 만듭니다. 남용 가능성이 우려되어 모델을 단계적으로 릴리스했습니다. 먼저 작은 모델로 시작해서 나중에 전체 모델을 공개했습니다.
CTRL
GPT-2 같은 모델은 입력 시퀀스(프롬프트라고 부르기도 합니다)의 뒤를 잇습니다. 하지만 생성된 시퀀스의 스타일은 거의 제어하지 못합니다. CTRL(Conditional Transformer Language) 모델은 시퀀스 시작 부분에 ‘제어 토큰’을 추가해 이 문제를 해결합니다. 이를 통해 생성 문장의 스타일을 제어해 다양한 문장을 생성합니다.
GPT-3
GPT를 GPT-2로 확장해 성공한 뒤, 다양한 규모에서 언어 모델의 동작을 자세히 분석해 계산량, 데이터셋 크기, 모델 크기, 언어 모델 성능의 관계를 관장하는 간단한 거듭제곱 규칙을 발견했습니다. 이런 통찰에서 착안해, GPT-2를 100배 늘려 파라미터가 1,750억 개인 GPT-3를 만들었습니다.
이 모델은 매우 사실적인 텍스트 구절을 생성할 뿐 아니라 퓨샷 학습(few-shot learning) 능력도 갖췄습니다. 텍스트를 코드로 변환하는 것 같이 모델이 새로운 작업에서 샘플 몇 개를 학습해 새로운 샘플을 처리할 수 있습니다. OpenAI는 이 모델을 오픈소스로 공개하지 않았지만 OpenAI API(https://oreil.ly/SEGRW)를 통해 인터페이스를 제공합니다.
GPT-Neo/GPT-J-6B
이 두 모델은 GPT-3 규모의 모델을 만들고 릴리스하기 위한 연구자들의 모임인 EleutherAI(https://eleuther.ai)에서 훈련한 GPT 유사 모델입니다. 현재 모델은 1,750억 개 파라미터가 있는 모델보다 더 작은 버전으로 13억 개, 27억 개, 60억 개 파라미터가 있습니다. OpenAI가 제공하는 작은 GPT-3에 견줄 만한 모델입니다.
이제 트랜스포머 가계도의 마지막 유형인 인코더-디코더 모델을 알아보겠습니다.
인코더-디코더 유형
하나의 인코더나 디코더 스택을 사용해 모델을 만드는 것이 일반적이지만, 트랜스포머 아키텍처에는 인코더-디코더 변종이 여럿 있으며 NLU와 NLG 분야에서 새로운 애플리케이션을 만듭니다.
T5
T5 모델은 모든 NLU와 NLG 작업을 텍스트-투-텍스트 작업으로 변환해 통합합니다. 모든 작업이 시퀀스-투-시퀀스 문제로 구성되므로 인코더-디코더 구조를 선택하는 것이 자연스럽습니다. 예를 들어 텍스트 분류 문제의 경우 텍스트가 인코더 입력으로 사용되고 디코더는 클래스 대신 일반 텍스트로 레이블을 생성합니다.
T5 아키텍처는 원본 트랜스포머 아키텍처를 사용합니다. 이 모델은 대규모로 크롤링된 C4 데이터셋을 사용하며 텍스트-투-텍스트 작업으로 변환된 SuperGLUE 작업과 마스크드 언어 모델링으로 사전 훈련됩니다. 파라미터가 110억 개인 가장 큰 모델은 여러 벤치마크에서 최상의 결과를 냈습니다.
BART
BART는 인코더-디코더 아키텍처 안에 BERT와 GPT의 사전 훈련 과정을 결합합니다. 입력 시퀀스는 간단한 마스킹에서 문장 섞기, 토큰 삭제, 문서 순환(document rotation)에 이르기까지 가능한 여러 가지 변환 중 하나를 거칩니다. 변경된 입력이 인코더를 통과하면 디코더는 원본 텍스트를 재구성합니다. 이는 모델을 더 유연하게 만들어 NLU와 NLG 작업에 모두 사용할 수 있고, 양쪽에서 최상의 성능을 달성합니다.
M2M-100
번역 모델은 대개 하나의 언어 쌍과 번역 방향에 맞춰 구축되므로 자연히 많은 언어로 확장되지 못합니다. 언어 쌍 사이에 공유되는 지식이 있다면 데이터가 부족한 언어의 번역에 활용할 수 있습니다. M2M-100은 100개 언어를 번역하는 최초의 번역 모델입니다. 희귀하거나 잘 알려지지 않은 언어에서 고품질의 번역을 수행합니다. 이 모델은 ([CLS] 특수 토큰과 비슷한) 접두어 토큰을 사용해 소스 언어와 타깃 언어를 나타냅니다.
BigBird
트랜스포머 모델은 최대 문맥 크기라는 제약점이 있습니다. 어텐션 메커니즘에 필요한 메모리가 시퀀스 길이의 제곱에 비례하기 때문입니다. BigBird는 선형적인 크기가 늘어나는 희소 어텐션을 사용해 이 문제를 해결합니다. 그래서 문맥 크기가 대부분의 BERT 모델에서 사용하는 512토큰에서 4,096으로 크게 늘어납니다. 특히 텍스트 요약과 같이 긴 의존성을 보존해야 할 때 유용합니다.
지금까지 다룬 모든 모델의 사전 훈련된 체크포인트를 허깅페이스 허브(https://oreil.ly/EIOrN)에서 제공합니다. 트랜스포머스를 사용해 자신의 문제에 맞게 미세 튜닝할 수도 있습니다.
이 글은 <트랜스포머를 활용한 자연어 처리> 도서 내용 일부를 발췌 편집한 글입니다. 허깅페이스 개발팀이 직접 알려주는 트랜스포머와 자연어 처리 기술에 대한 자세한 내용은 하기 링크의 도서에서 만나보실 수 있습니다.


최신 콘텐츠