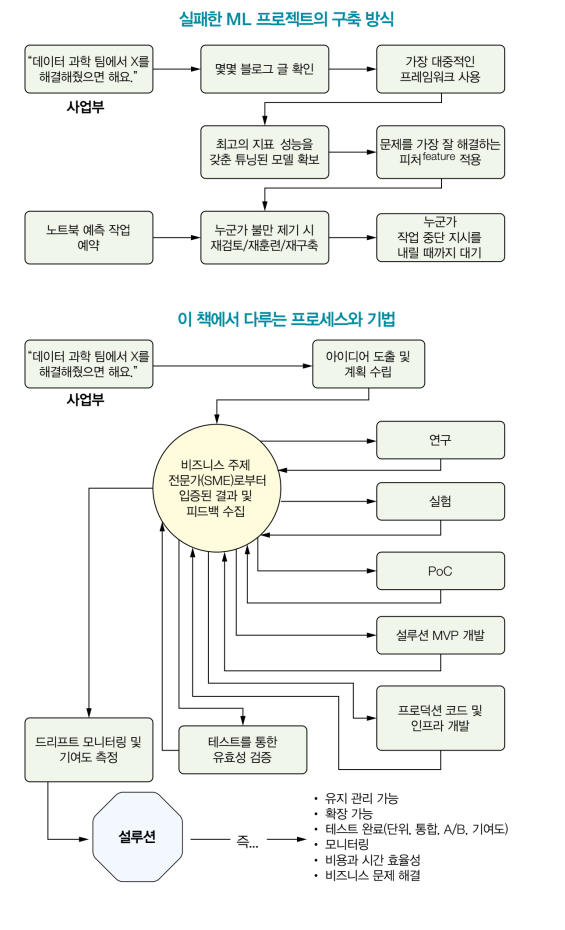
이 책은 성공적인 엔지니어링 기법에 관한 책이다. 책에서 소개하는 상당히 많은 부분은 머신러닝뿐만 아니라 모든 프로젝트에 관련되어 있다. 개인적인 느낌은 머신러닝을 예시로 든 엔지니어링 기법에 관한 책이 아닐까?
'엔지니어링활동'이란 엔지니어링산업 진흥법 제2조(정의) 1항(정의)을 보면 다음과 같이 정의한다.
1. “엔지니어링활동”이란 과학기술의 지식을 응용하여 수행하는 사업이나 시설물에 관한 다음 각 목의 활동을 말한다.
가. 연구, 기획, 타당성 조사, 설계, 분석, 계약, 구매, 조달, 시험, 감리, 시험운전, 평가, 검사, 안전성 검토, 관리, 매뉴얼 작성, 자문, 지도, 유지 또는 보수
법제처, 엔지니어링산업 진흥법 제2조 1항
책에서 설명하는 내용과 거의 정확히 맞다. 계약, 구매, 조달 부분만 빼고
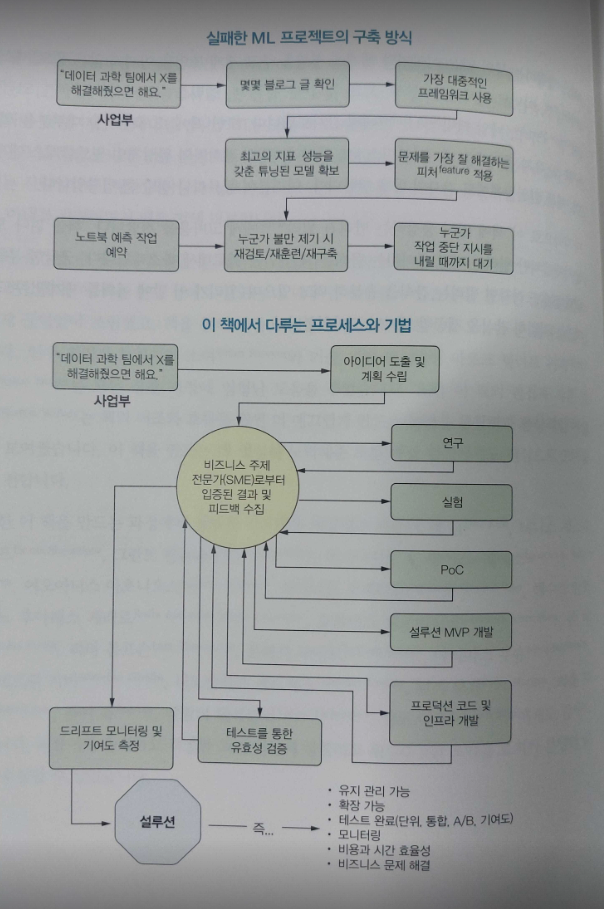
ML 프로젝트의 연구, 기획, 타당성 조사, 설계, 분석, 실험, 평가, 검사, 관리, 유지 관리에 관한 모든 내용을 다루고 있다. 프로젝트를 성공으로 이끄는 방법을 저자의 실패담이나 경험담을 비추어 쉽게 설명한다. 저자가 강조하는 것은 저자와 같은 실수를 피할 수 있도록 도와주는 지침서로 활용하라는 것이다.
최근 시장에서 가장 많이 요구되는 프로젝트는 단연코 ML 프로젝트이다.
몇년 전에 ML 프로젝트를 가까이서 볼 기회가 있었는데(참여는 하지 않고), 이 책을 꼭 추천드리고 싶다.
저자의 말처럼 발주한 ML 프로덕트가 종국에는 POC 형태로 가능성만 본 적이 많았다. 분명 이 책에 제시한 함정만 피하더라도 대부분이 성공하지 않았을까? 조심스레 예측해본다.
대상 독자는 머신러닝과 관련된 업무를 하는 사람은 모두 봐야한다고 생각한다. 머신러닝으로 무언가를 구축할 때 필요한 모든 것이 있다. 봐야될 시기는 다를 수 있지만, 되도록 빠른 시간내에 보기를 추천드린다. 입문자나 주니어는 의심을 하지 말고 꼭 읽기 바란다. 시니어는 읽어보면 저절로 아실 것이다.
성공하는 ML 프로젝트의 로드맵을 제시하는 경험자의 소중한 가이드북이다.
책의 구성은 전체 3개 파트와 부록으로 구성되어 있는데, 'PART 1의 머신러닝 엔지니어링 소개'는 총 8개의 장으로 ML 프로젝트를 성공적으로 수행하기에 앞서 ML 엔지니어링 활동에 필요한 개념과 구성요소를 확인하고 각 단계별 효과적은 접근방법을 설명한다. 'PART 2의 프로덕션 준비: 유지 관리 가능한 ML 만들기'는 총 5개의 장으로 테스트 가능하고 읽기 쉬운 코드를 작성하기 위한 방법을 시작으로 ML 프로젝트 진행 과정에 필요한 내용을 설명한다. 'PART 3의 프로덕션 머신러닝 코드 개발'은 ML 프로덕션의 배포와 재훈련, 모니터링이 가능하고, 쉽게 업데이트하는 방법을 주제로 섧명하면서 마무리한다.
마지막 부록에서는 빅오(계산복잡도)로 런타임 성능 확인과 개선 방안을 알아보고, 효과적인 개발 환경 설정 방법을 알려준다. (<- 부록까지 챙겨보자)
PART 1의 CHAPTER 1은 ML 프로젝트의 개발 로드맵과 ML 엔지니어링 핵심 원칙, ML 엔지니어링의 목표를 알아보고
CHAPTER 2에서는 데이터 과학자와 ML 엔지니어의 차이점 과 ML 프로젝트 작업에 애자일 방법론을 적용하는법, 데브옵스와 ML옵스를 비교 설명한다.
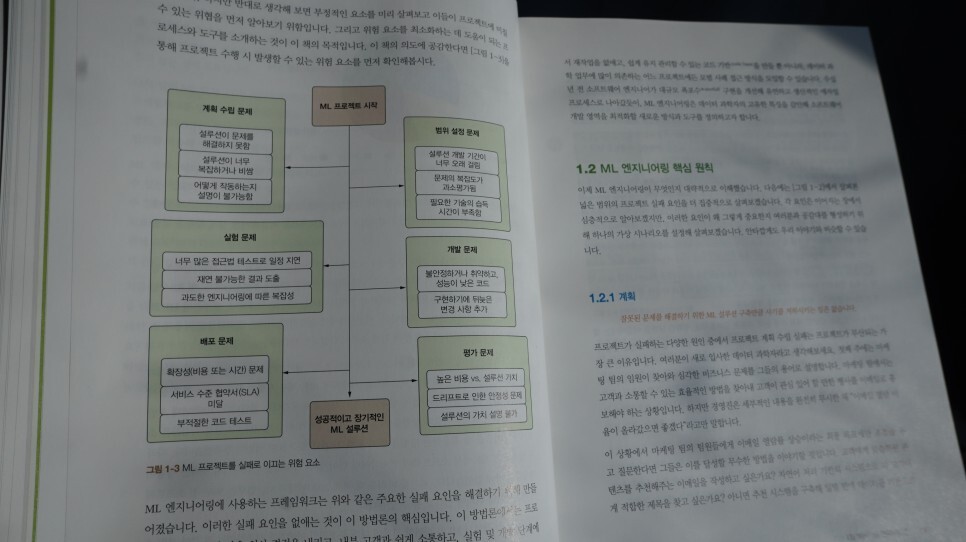
CHAPTER 3은 ML 프로젝트를 위한 효과적인 계획 수립 전략과 범위에 따른 평가 방법을 살펴보고
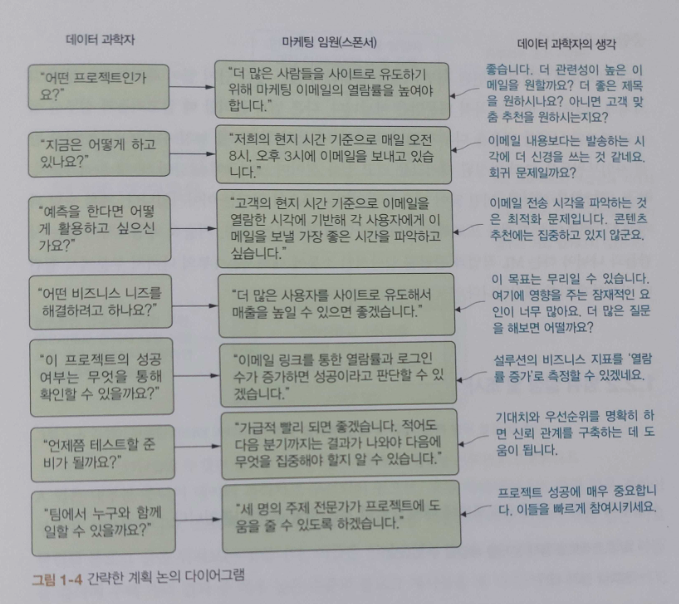
CHAPTER 4에서는 계획 수립를 구체화하기 위한 수단으로 프로젝트와 관련있는 조직과의 효과적인 의사소통과 프로젝트 규칙을 정하는 방법을 설명한다.
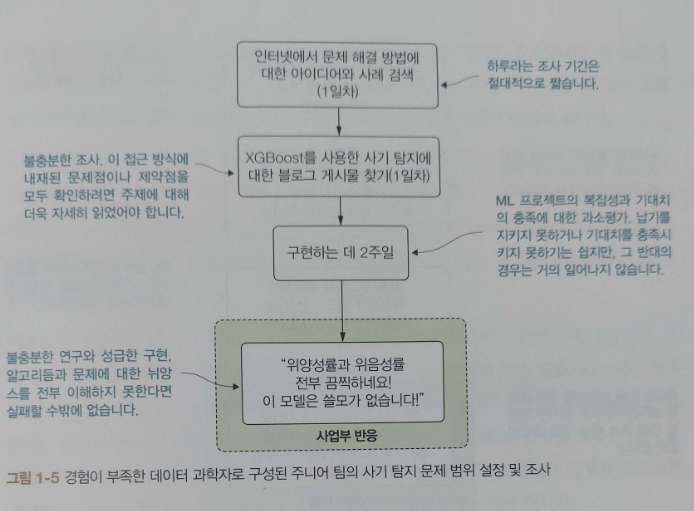
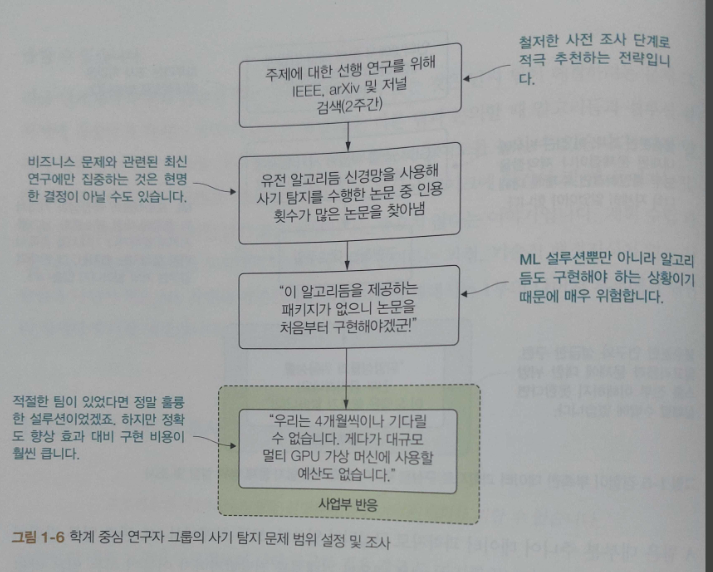
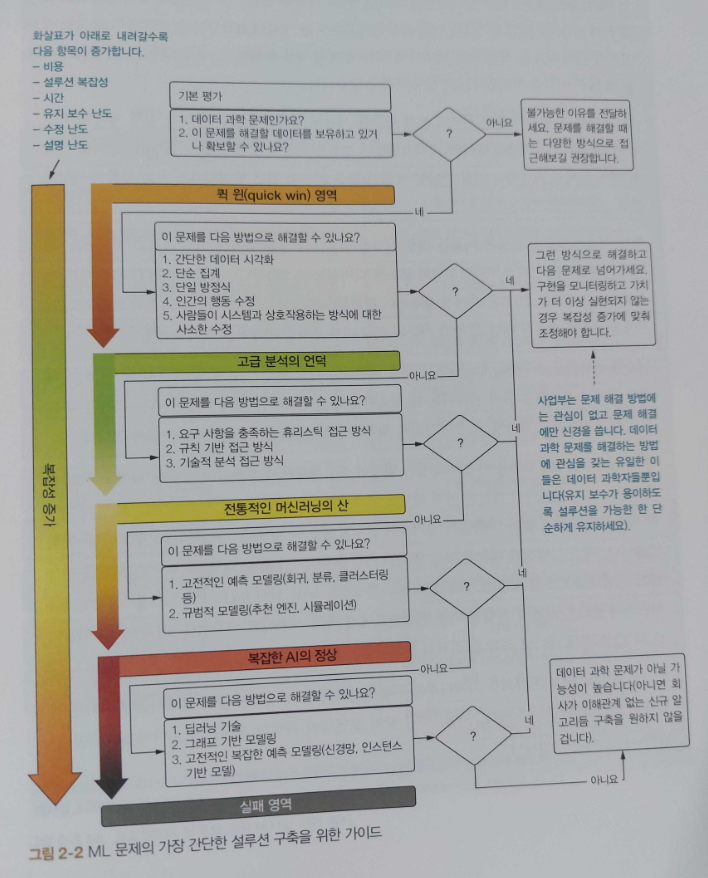
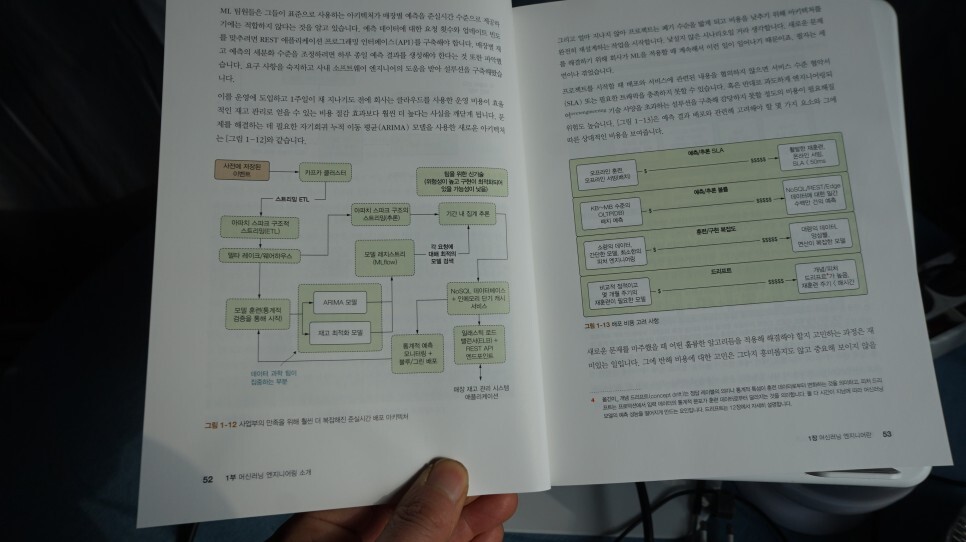
CHAPTER 5는 ML 프로젝트의 연구 단계 세부 사항을 알아 보고, POC등의 솔루션 실험 프로세스와 방법을 알아보고
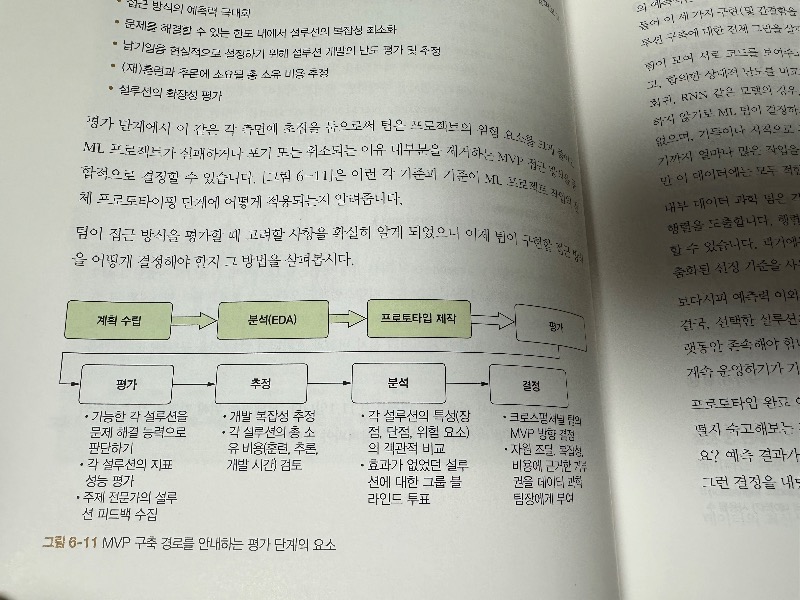
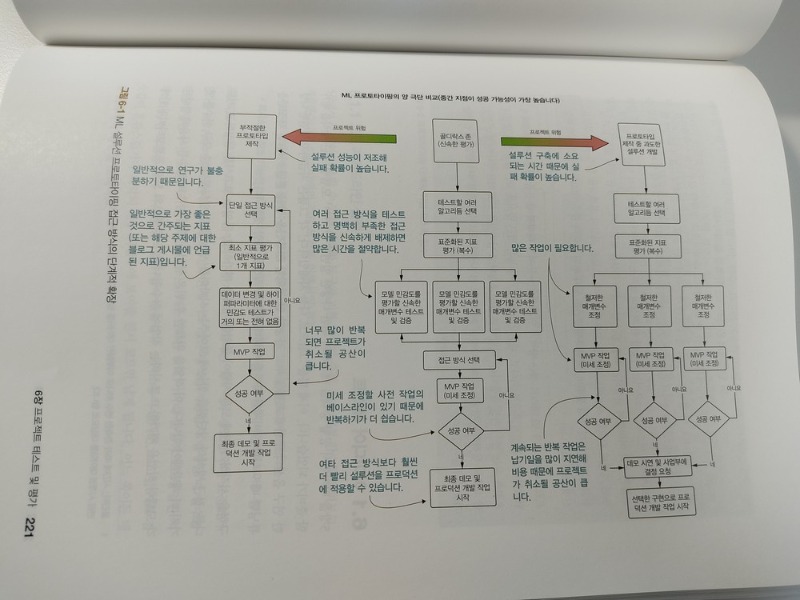
CHAPTER 6에서는 ML 프로젝트 테스트 방법과 프로토타입 평가 방법에 관해 살펴본다.
CHAPTER 7은 프로토타입를 MVP로 전환하기 위한 하이퍼파라미터 튜닝 방법, 자동화 방법과 최적화 성능 개선을 위한 실행방법에 관해 설명하고
CHAPTER 8에서는 확장 가능한 솔루션을 위한 ML 코드, 모델 버전관리, 로그 관리등의 도구와 방법을 살펴본다.
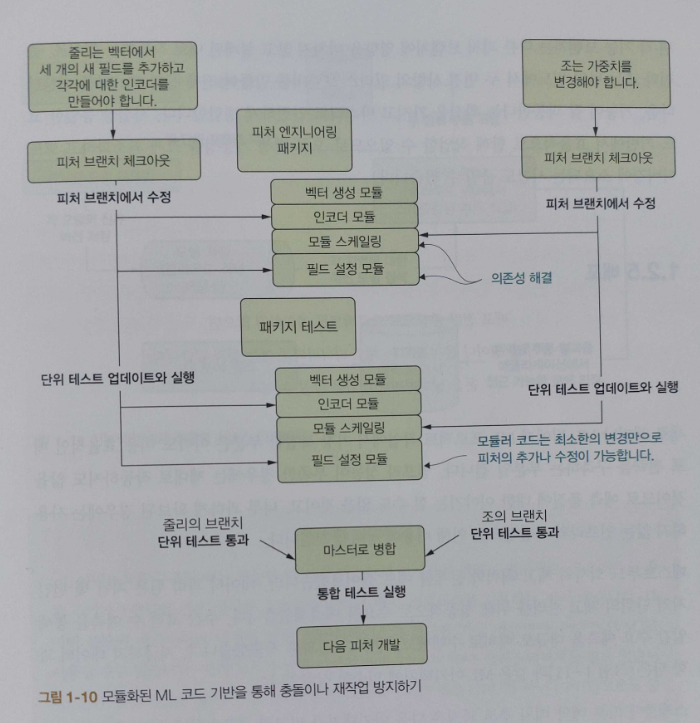
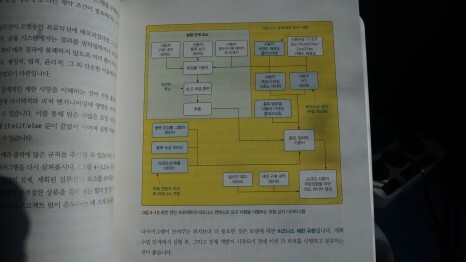
PART 2의 CHAPTER 9는 모놀리식 스크립트 코딩 패턴의 단점을 보완하고 ML 프로젝트에 필요한 추상화 방법, 모듈화, TDD를 활용하여 테스트 가능한 설계 구현 방법을 설명하고
CHAPTER 10에서는 ML 코드의 문제를 식별하고 다양한 해결 방법을 제시한다.
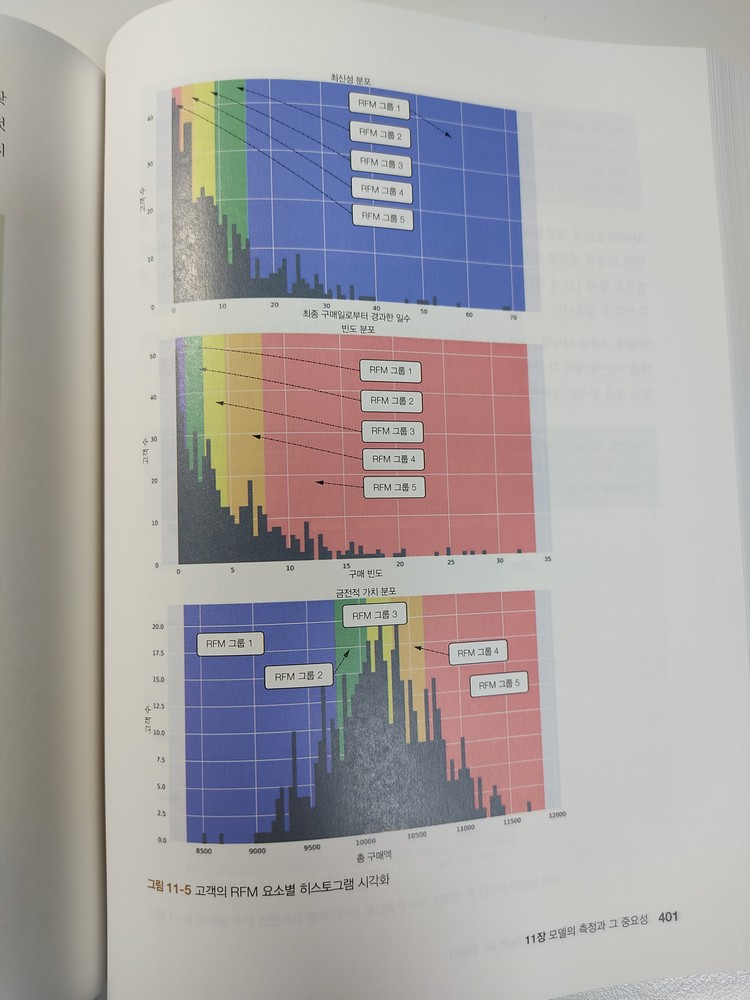
CHAPTER 11은 모델의 기여도 중요성과 측정 방법을 설명하고
CHAPTER 12에서는 다양한 드리프트(성능 저하)를 식별하고, 모니터링 방법과 대처 방안에 대해서 논의한다.
CHAPTER 13은 리팩토링과 단순한 코드의 이점에 대해서 설명하고, 신기술에 관해서 알아본다.
PART 3의 CHAPTER 14는 모델에 사용하기 전 효과적인 피처 데이터 검증 및 모니터링 방법과 ML 프로젝트를 위한 표준 코드 아키텍처 정의 방법에 관하 설명하고
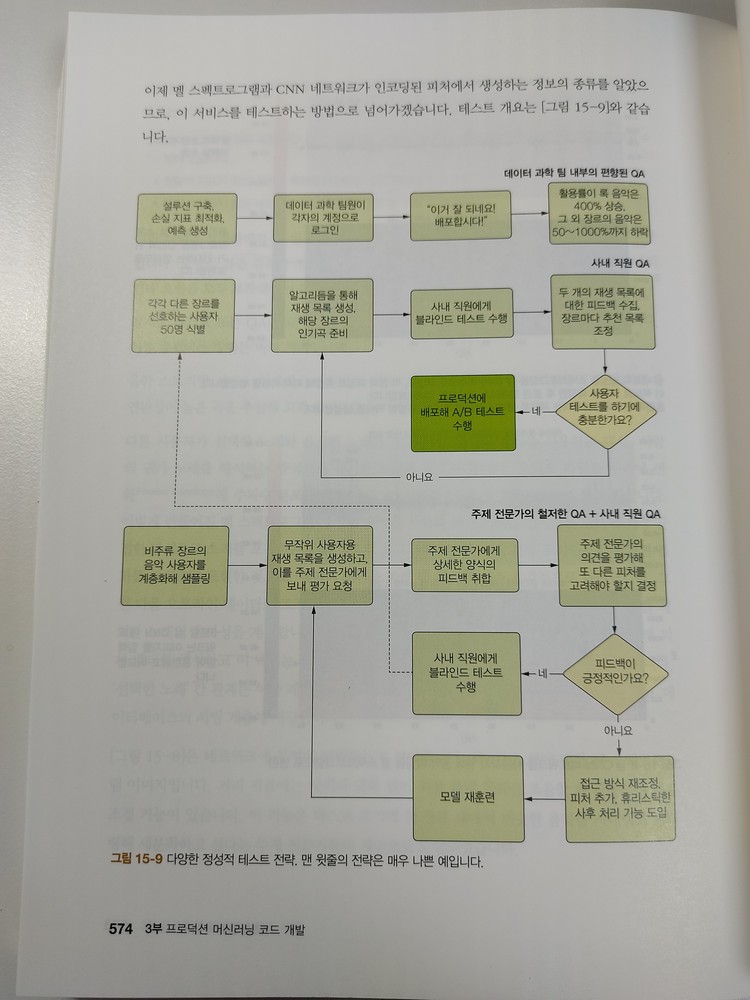
CHAPTER 15에서는 예측 실패에 대한 처리 방법과 품질 보증 방안, 설명 가능한 AI(XAI)에 관해 살펴본다.
마지막 CHAPTER 16은 모델 레지스트리를 사용하여 모델을 관리하고, 피처 스토어 및 효과적인 서빙 전략을 알아 본다.
각 장은 먼저 '이 장의 내용'에서 앞으로 설명하게 될 주제를 제시하고, 이어서 각 주제에 관하여 배경과 개념을 다양한 그림과 표, 예제(+코드 해설)로써 쉽게 설명한다. 마지막에는 '요약'으로 마무리한다.

녹색 계통의 책의 내용 디자인은 읽기에 편안했으며, 코드 블럭과 설명도 읽기 쉬웠다. 표의 사용을 줄이고 순서도나 그래프등의 그림으로 설명한 부분이 특히 이해하기가 쉬웠으며, NOTE_, WARNING_, 저자의 추가 설명 부분도 이해하는데 도움이 많이 되었다.
그리고 번역하시느라 수고하신 역자에게도 감사의 말씀을 드린다.
다만, 표지가 좀 약하지 않나 생각이 든다. 책장에서 자주 펴봐야할 것 같아서 ㅎㅎ
692페이지의 분량의 엄청난 텍스트임에도 불구하고, 전혀 지루하지 않았으며, 수집 개의 회사에서 수 많은 ML 프로젝트를 이끈 저자의 경험을 비추어볼 때 아직 할 말이 많이 남아 있는 것처럼 보였다.
그럼에도, 책에서 다루는 내용은 ML 프로젝트의 모든 것이라고 해도 부족함이 없을듯 하다.
다른 책에 비해, 모듈화와 리펙토링, 로깅등의 코드에 진심인 저자의 좋은 소프트웨어 엔지니어링 원칙으로 마무리한다. 읽어주셔서 감사합니다.
컴퓨터가 이해할 수 있는 코드는 누구나 작성할 수 있습니다.
하지만 좋은 프로그래머는 사람이 이해할 수 있는 코드를 작성합니다.
9장 ML 모듈화: 테스트 가능하고 읽기 쉬운 코드 작성, p321
"한빛미디어<나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."