머신 러닝 프로젝트를 진행 중인 상황에서 매우 도움이 되는 책입니다. 시작 단계에서 비즈니스 모델의 이해와 MVP 선정 등 지속적인 관리를 A/B TEST 등 실무에 필요한 내용이 많습니다.
실전에 필요한 MLOps, 머신러닝 모델 검증, 슬롯머신 알고리즘, 온라인 광고에서의 머신러닝
어디서든 환영받는 ‘실무형 머신러닝’ 비법
온라인 강의, 책, 대학 연구만으로는 실제 비즈니스에 머신러닝을 어떻게 적용할 것인지, 어떤 경우에 머신러닝 기법과 데이터 분석 방법을 적용해야 하는지 알기 어렵다. 해결해야 하는 문제를 정의하고 시스템을 설계하는 방법 역시 배우기 쉽지 않다. 가설 수립, 탐색적 분석 수행 방법 등 저자들이 경험하고 학습했던 노하우를 아낌없이 담아냈다. 2판에서는 지속적인 학습을 위한 MLOps와 슬롯머신 알고리즘을 활용한 강화 학습 등의 내용도 추가했다. 실무에서 통하는 머신러닝을 구현하고 싶다면 이 책으로 갈증을 해소할 수 있을 것이다.

PART1 머신러닝 실무 노하우
CHAPTER 1 머신러닝 프로젝트 처음 시작하기
1.1 머신러닝은 어떻게 사용되는가
1.2 머신러닝 프로젝트 과정
1.3 운용 시스템에서의 머신러닝 문제점 대처 방법
1.4 머신러닝 시스템을 성공적으로 운영하기 위한 조건
1.5 정리
CHAPTER 2 머신러닝으로 할 수 있는 일
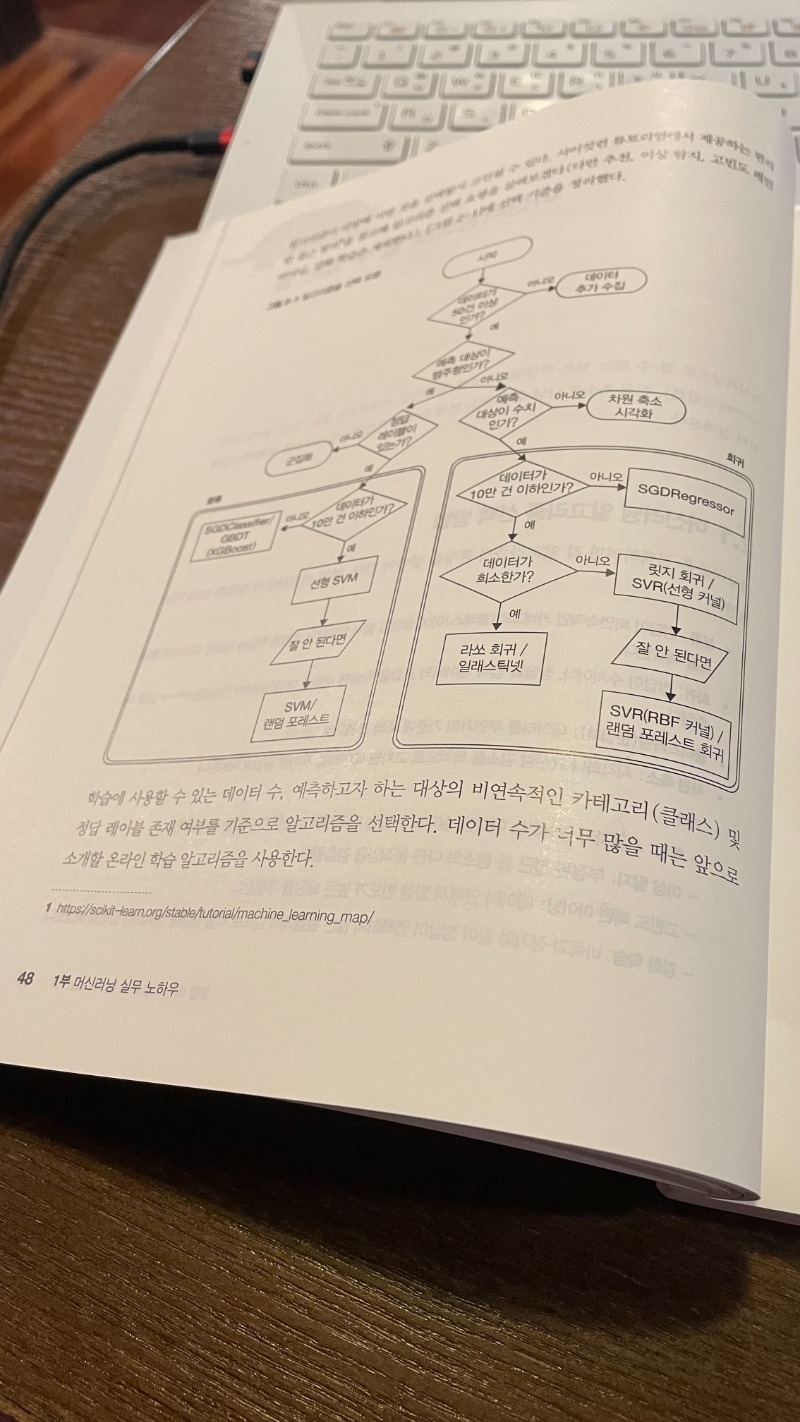
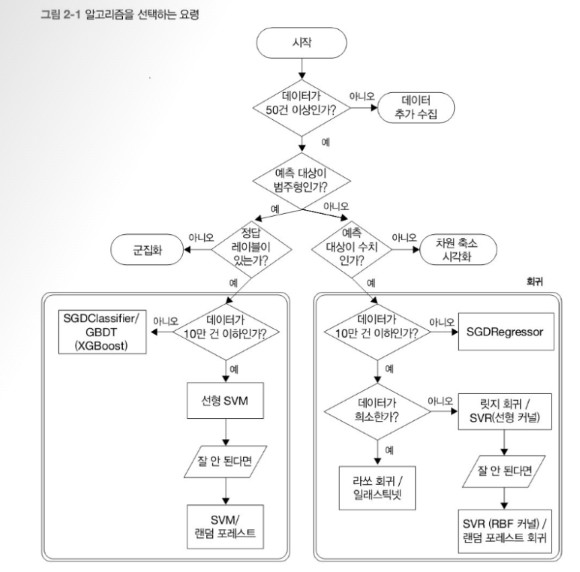
2.1 머신러닝 알고리즘 선택 방법
2.2 분류
2.3 회귀
2.4 클러스터링과 차원 축소
2.5 기타
2.6 정리
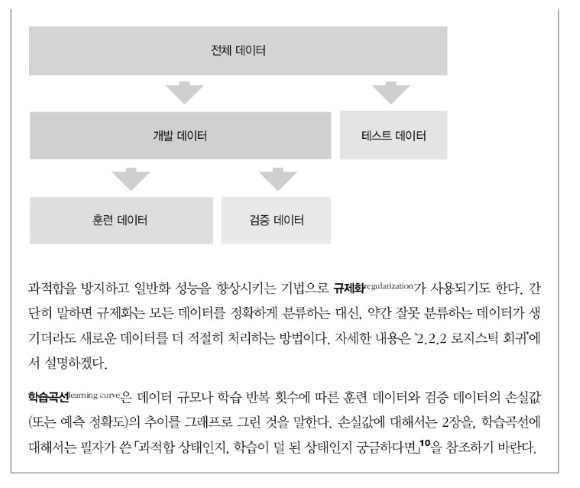
CHAPTER 3 학습 결과 평가하기
3.1 분류 평가
3.2 회귀 평가
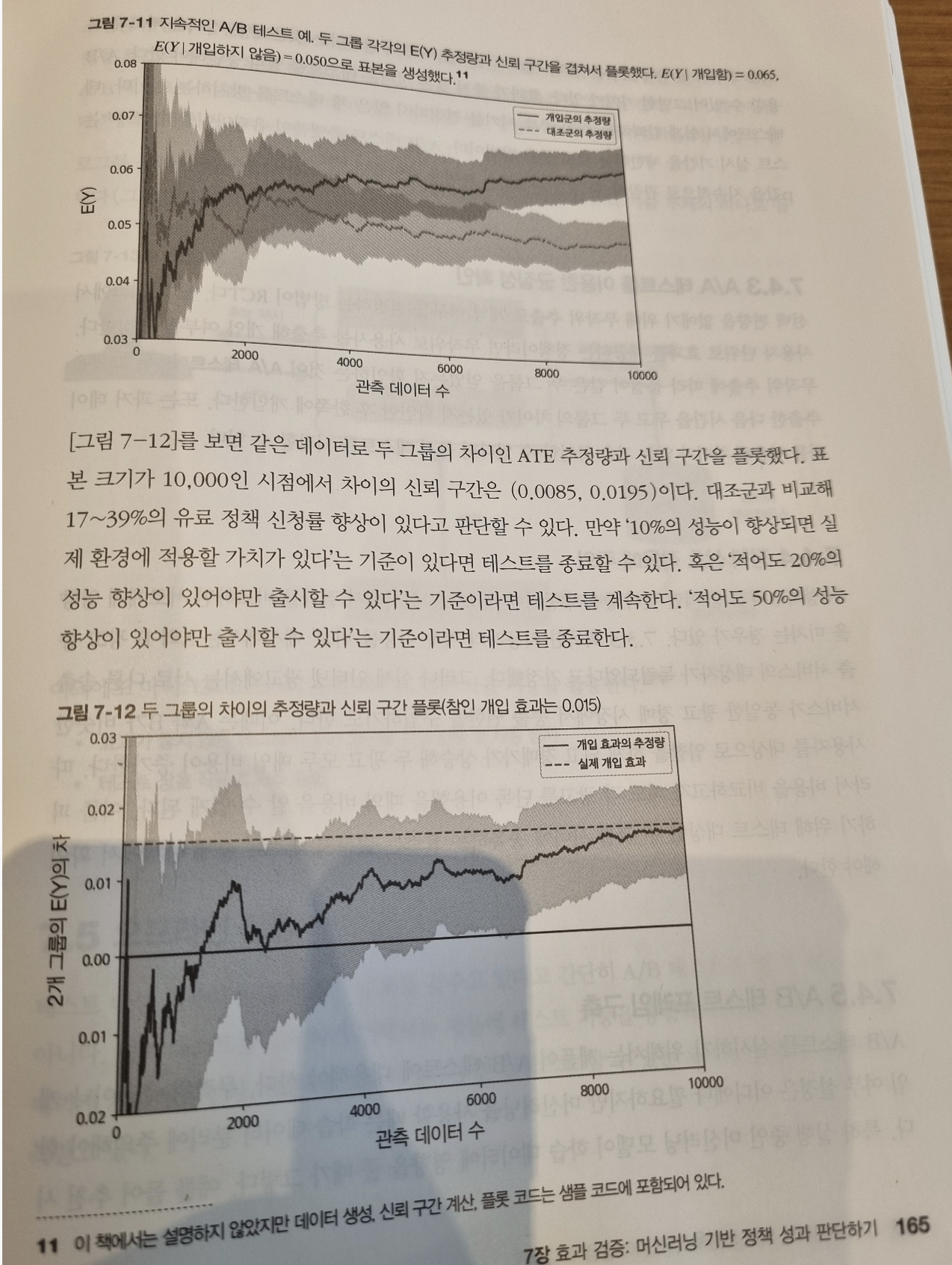
3.3 머신러닝을 통합한 시스템의 A/B 테스트
3.4 정리
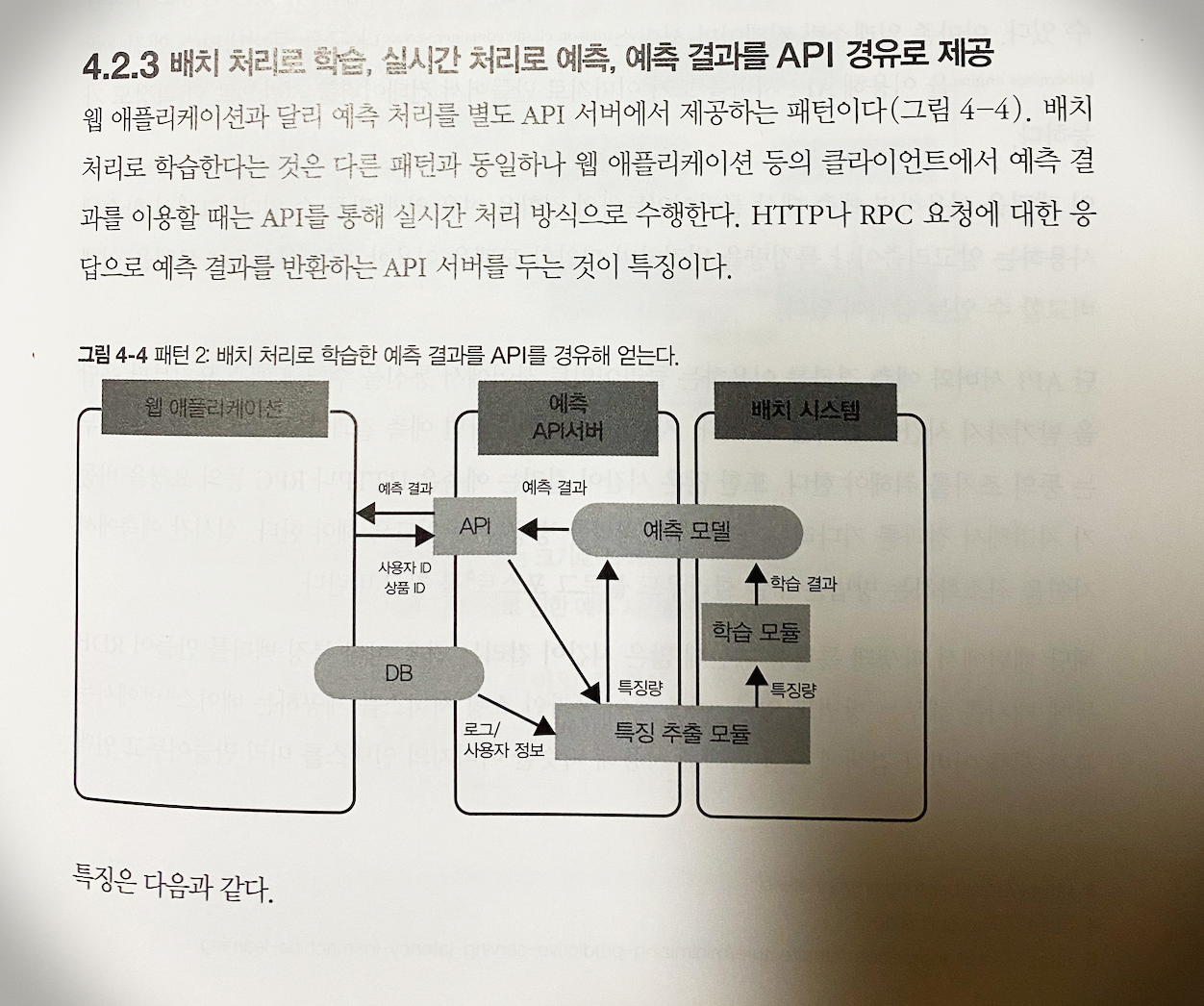
CHAPTER 4 기존 시스템에 머신러닝 통합하기
4.1 기존 시스템에 머신러닝을 통합하는 과정
4.2 시스템 설계
4.3 훈련 데이터를 얻기 위한 로그 설계
4.4 정리
CHAPTER 5 학습 리소스 수집하기
5.1 학습 리소스 수집 방법
5.2 공개된 데이터셋이나 모델 활용
5.3 개발자가 직접 훈련 데이터 작성
5.4 동료나 지인에게 데이터 입력 요청
5.5 크라우드소싱 활용
5.6 서비스에 통합해서 사용자가 입력
5.7 정리
CHAPTER 6 지속적인 머신러닝 활용을 위한 기반 구축하기
6.1 머신러닝 시스템만의 독특한 어려움
6.2 지속적인 학습과 MLOps
6.3 머신러닝 인프라 구축 단계
6.4 지속적인 예측 결과 서빙
6.5 정리
CHAPTER 7 효과 검증: 머신러닝 기반 정책 성과 판단하기
7.1 효과 검증
7.2 인과 효과 추정
7.3 가설 검정 프레임
7.4 A/B 테스트 설계 및 수행
7.5 오프라인 검증
7.6 A/B 테스트를 수행할 수 없을 경우
7.7 정리
7.8 쉬어가기: 무조건 성공하는 A/B 테스트, A/B 테스트 모집단 조작
CHAPTER 8 머신러닝 모델 해석하기
8.1 구글 콜랩에 설치된 라이브러리 버전 업데이트
8.2 학습용 파일 업로드 및 확인
8.3 선형 회귀 계수를 이용한 원인 해석
8.4 로지스틱 회귀 계수로 원인 해석
8.5 회귀 계수 p값 구하기
8.6 결정 트리를 시각화해 원인 해석
8.7 랜덤 포레스트의 Feature Importance 시각화
8.8 SHAP을 활용한 기여도 시각화
8.9 SHAP을 활용한 직원 만족도 시각화
8.10 정리
PART2 머신러닝 실무 프로젝트
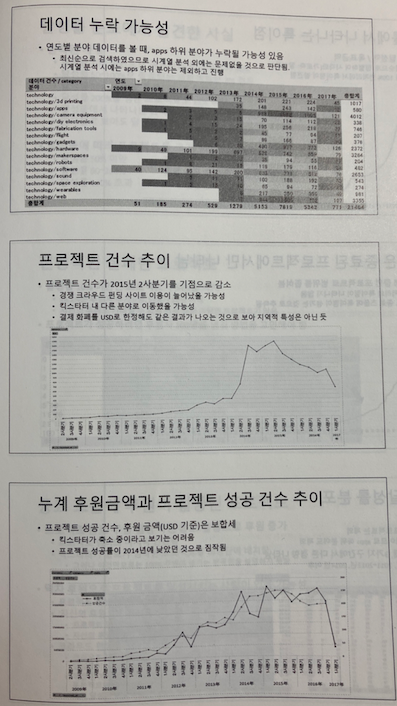
CHAPTER 9 킥스타터 분석하기: 머신러닝을 사용하지 않는 선택지
9.1 킥스타터 API 확인하기
9.2 킥스타터 크롤러 만들기
9.3 JSON 데이터를 CSV로 변환하기
9.4 엑셀로 데이터 살펴보기
9.5 피벗 테이블로 다양하게 파악하기
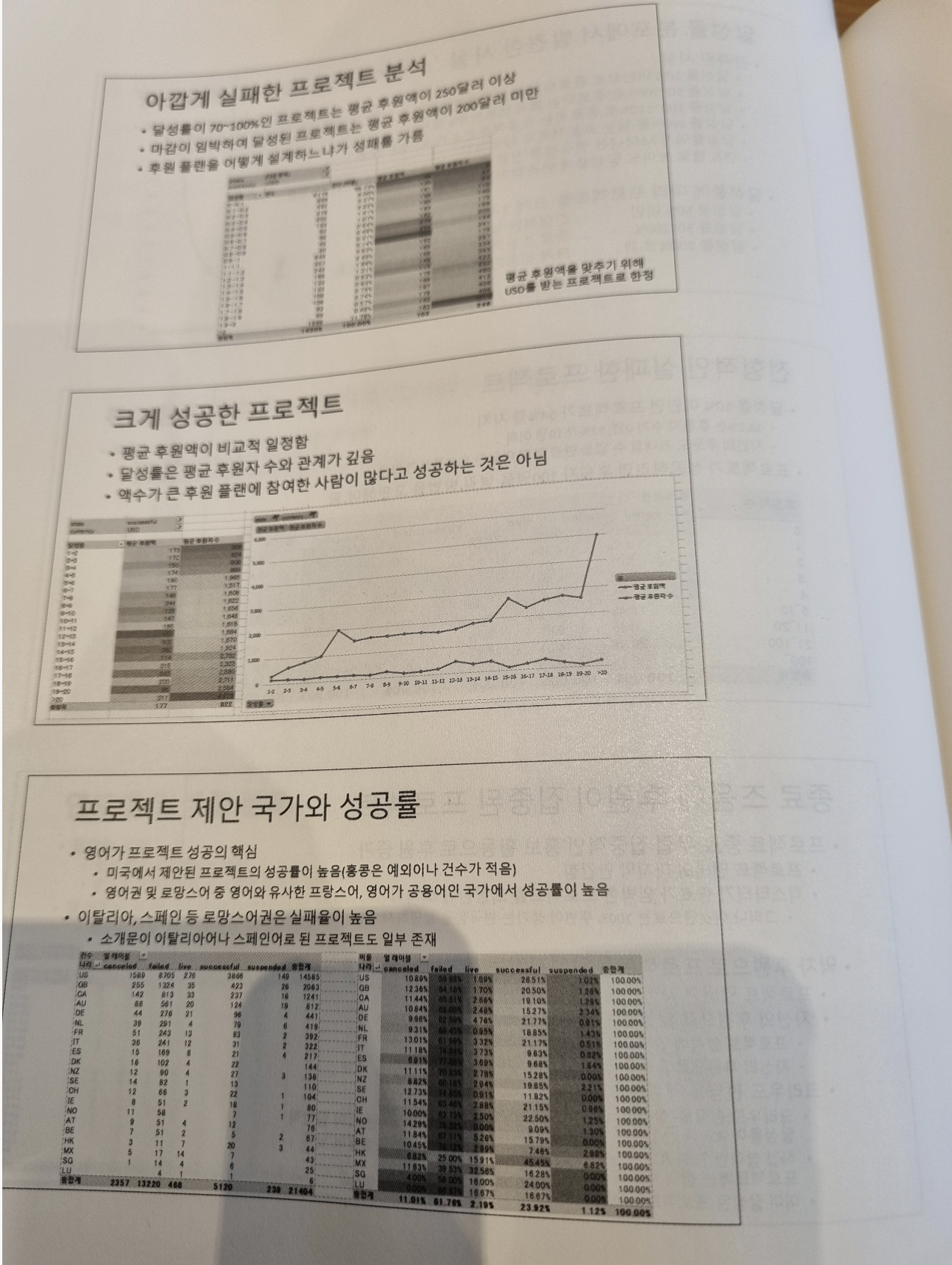
9.6 목표를 달성했지만 취소된 프로젝트 확인하기
9.7 국가별로 살펴보기
9.8 보고서 작성하기
9.9 이후 작업
9.10 정리
CHAPTER 10 업리프트 모델링을 이용한 마케팅 리소스 효율화
10.1 업리프트 모델링의 사분면
10.2 A/B 테스트 확장을 통한 업리프트 모델링
10.3 업리프트 모델링용 데이터셋 만들기
10.4 두 가지 예측 모델을 이용한 업리프트 모델링
10.5 AUUC로 업리프트 모델링 평가
10.6 실제 문제에 적용
10.7 업리프트 모델링을 서비스에 적용
10.8 정리
CHAPTER 11 슬롯머신 알고리즘을 활용한 강화 학습 입문
11.1 슬롯머신 알고리즘 용어 정리
11.2 확률분포에 관한 사고
11.3 사후 분포에 관한 사고
11.4 사후 분포의 신뢰 구간 상한을 이용한 구현 사례
11.5 UCB1
11.6 확률적 슬롯머신 알고리즘
11.7 다양한 슬롯머신 알고리즘 비교
11.8 부트스트랩 알고리즘을 이용한 콘텍스트 기반 슬롯머신 구현
11.9 현실 과제
11.10 A/B 테스트, 업리프트 모델링, 슬롯머신 알고리즘의 관계
11.11 정리
CHAPTER 12 온라인 광고에서의 머신러닝
12.1 온라인 광고 비즈니스
12.2 문제 정식화
12.3 예측의 역할 및 구현
12.4 광고 송출 로그의 특징
12.5 머신러닝 예측 모델 운영
12.6 정리
머신러닝을 실무에 활용하고 싶은데
어떻게 하면 좋을지 모르겠다면 바로 이 책!
머신러닝이 보급되면서 인과 효과 추론, 지속적인 학습, 머신러닝 기반 운영 등 새로운 문제에 직면하는 경우가 늘어났다. 머신러닝 시스템은 다양한 역할, 조직 체제 속에서 데이터라는 불확실한 대상이 만들어낸 결과를 통계와 운영을 포함해 다루어야만 한다. 실무에 필요한 가설 수립, 탐색적인 분석 수행 방법 등 필자들이 경험하며 학습한 머신러닝 지식을 2판에 아낌없이 추가했다. 머신러닝을 독학으로 익히느라 이런 주제를 접할 기회가 없던 독자들에게 이 책이 머신러닝을 활용하는 데 미력하나마 도움이 된다면 더할 나위 없이 기쁠 것이다.
★2판에 추가된 내용
- 6장 데이터 변경에 대응하고 장기적으로 머신러닝을 운용하기 위한 MLOps 환경 구축
- 7장 머신러닝에 기반한 시행 결과 판단
- 8장 수학적 관점(선형 회귀, 로지스틱 회귀, 결정 트리, 랜덤 포레스트, SHAP)에서 머신러닝 모델의 학습 결과를 해석
- 11장 온라인 광고 콘텍스트에서 자주 사용되는 슬롯머신 알고리즘을 이용한 강화 학습
- 12장 온라인 광고의 구성 방식, 운영 방식, 전환 효과 예측 등 각 단계에 적용할 수 있는 머신러닝의 원칙과 기법들을 설명
★이 책에서 다루는 내용
1부에서는 머신러닝 프로젝트를 수행하기 위해 알아야 할 기본 지식을 소개하고 9장부터 시작하는 2부는 앞서 설명한 내용을 포함한 실제 사례를 통해 실무에 도움이 되도록 내용을 구성했다. 각 장의 내용은 1부에서 소개한 내용을 포함하고 있으니 앞서 설명한 내용을 떠올리면 읽으면 도움이 될 것이다.
1장 머신러닝 프로젝트가 수행되는 과정
2장 머신러닝으로 할 수 있는 일과 다양한 머신러닝 알고리즘
3장 오프라인에서 예측 모델을 평가하는 방법
4장 컴퓨터 시스템에 머신러닝 구조를 통합하는 주요 패턴
5장 머신러닝 분류 태스크에서 정답 데이터 수집
6장 지속 학습을 위한 머신러닝 기반 MLOps
7장 통계 검정, 인과 효과 추론, A/B 테스트
8장 머신러닝을 통해 얻은 예측 결과를 설명하는 방법
9장 탐색적 분석 과정과 이를 기반으로 한 보고서 발행
10장 업리프트 모델링을 사용해 더욱 효과적인 마케팅 수행
11장 슬롯머신 알고리즘을 이용한 강화 학습
12장 실제 시스템에 적용된 머신러닝 최적화
★누구를 위한 책인가
다음 독자를 대상으로 머신러닝 데이터 분석 도구를 어떻게 비즈니스에 활용하는지, 불확실성이 높은 머신러닝 프로젝트는 어떻게 진행하는지 다룬다.
- 머신러닝 입문서를 떼고 실무에 활용하려는 개발자
- 대학에서 배운 머신러닝을 제품에 적용하려는 주니어 개발자
- 소프트웨어 개발자는 아니지만 머신러닝 시스템 및 기술적인 내용에 흥미가 있는 비즈니스 담당자
머신러닝 알고리즘은 이미 다른 책에서 많이 다루고 있으니 이 책에서는 머신러닝 프로젝트를 처음 시작하는 방법, 기존 시스템에 머신러닝을 통합하는 방법, 머신러닝에 사용할 데이터를 수집하는 방법 등 실무에 유용한 내용을 중점적으로 다룬다.
| 자료명 | 등록일 | 다운로드 |
|---|---|---|
| 2022-03-18 | 다운로드 |
오탈자 등록