IT/모바일
제공 : 한빛 네트워크
저자 : Ben Lorica
역자 : 한승균
원문 : Seven reasons why I like Spark
Spark는 빅 데이터 툴킷 분야에서 중요한 위치를 차지하게 될 것이다.
 이번 주에 UC 버클리에서 열린 Amp Camp는 Spark - 오픈 소스, 인-메모리 기반의 클러스터 컴퓨팅 프레임워크인 - 를 소개하는 데에 많은 부분을 할애했다. 지난 달에 Spark를 사용해본 후에, 나는 나의 빅 데이터 툴킷 중에서 Spark를 가장 중요하게 생각하기 시작했다. 여기, 그 이유가 있다:
이번 주에 UC 버클리에서 열린 Amp Camp는 Spark - 오픈 소스, 인-메모리 기반의 클러스터 컴퓨팅 프레임워크인 - 를 소개하는 데에 많은 부분을 할애했다. 지난 달에 Spark를 사용해본 후에, 나는 나의 빅 데이터 툴킷 중에서 Spark를 가장 중요하게 생각하기 시작했다. 여기, 그 이유가 있다:
하둡 통합: Spark는 HDFS에 저장되어 있는 파일을 사용할 수 있다. 이것은 하둡 생태계에 투자된 양을 생각해보면 매우 중요한 특징이다. Spark와 MapR을 함께 사용하는 것은 매우 쉽다.
Spark 대화형 쉘: Spark는 Scala로 개발되었으며, Spark만의 Scala 인터프리터를 사용한다. 이것을 사용하면 간단한 코드를 테스트 하는데 엄청나게 편리하다.
Spark 분석 스위트:
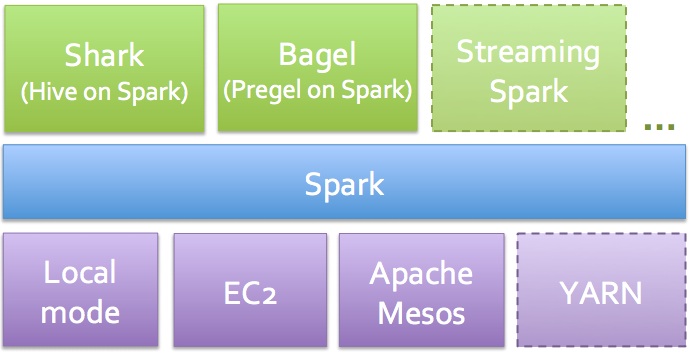
(그림은 Matei Zaharia로부터)
Spark는 대화형 질의 분석기(Shark), 대용량 그래프 처리 및 분석기(Bagel), 실시간 분석기(Spark Streaming) 등을 함께 제공한다. 여러가지 툴들을 혼재해서 사용하지 않고(예를 들어, Hive, Hadoop, Mahout, S4/Storm), 하나의 프로그래밍 패러다임만 배우면 된다. SQL 지지자들을 위한 보너스가 하나 더 있다면, Shark가 Hive보다 더 빠르다는 것이다. Spark를 클라우드에서 돌리고 싶다면, EC2 스크립트들을 사용할 수 있다.
회복 가능한 분산 데이터 셋(RDD"s):
RDD"s는 노드들의 클러스터에 걸쳐, 메모리에 캐싱되어 있는 분산 객체다. 이것은 Spark에서 사용하는 기본 데이터 객체로, 중요한 점은 결함 허용(fault tolerance) 능력이 기본적으로 제공된다는 것이다: RDD"s는 무언가 잘못되면 자동으로 그것을 재생성한다. 만약 무언가 테스트해야 한다면, Spark 대화형 쉘에서 대화식으로 RDD"s를 사용할 수도 있다.
분산 연산자들:
Map과 Reduce에서 벗어나면, RDD"s에서 사용할 수 있는 많은 연산자들이 존재한다. 이것들이 어떻게 동작하는지에 대해 익숙해지고 난 후, 나는 기본적인 기계 학습과 데이터 처리 알고리즘을 이 프레임워크에서 사용할 수 있도록 변환시키기 시작했다.
한번 배워두기만 하면... 반복적인 프로그램들
어떤 곳에서든 생산적이기 위해서는 그만큼 노력이 필요하다. Spark 역시 예외는 아니다. 나는 Scala를 전혀 몰랐기 때문에, 우선 이 새로운 언어에 익숙해져야 했다 (보아하니, 이들은 밑줄을 좋아하는 것 같다 - 여기, 여기, 그리고 여기를 좀 보라). Scala를 넘어서면 Shark(Spark의 "SQL"), 그리고 Java와 Python API도 사용할 수 있다.
Spark를 시작하기 위해서 예제들을 사용할 수 있지만, 나는 더 중요한 것은 이 내장된 분산 연산자들에 익숙해지는 것이라고 생각한다. 내가 RDD"s와 연산자들을 배우고 난 후에는, 몇 가지의 기계 학습과 데이터 처리 알고리즘을 구현하기 위해 반복적으로 프로그램을 만들었다. (Spark가 데이터를 메모리에 분산하고 캐싱하기 때문에, 거대한 데이터 셋에서도 꽤 빠른 기계 학습 프로그램을 만들 수 있다.)
벌써 제품들이 사용하고 있다
정말로 사람들이 Spark를 사용할까? 사용하는 회사 리스트가 아직 짧긴 하지만, 샌프란시스코의 Spark Meetup과 Amp Camp의 크기를 보면, 더 많은 회사들이 Spark를 사용할 것이라고 기대한다. (만약 당신이 샌프란시스코의 Bay Area에 살고 있다면, 우리가 Aribnb와 함께 새로운 분산 데이터 처리 Meetup을 시작했다. 그리고 여기에서 Spark에 대해서도 이야기할 것이다.)
업데이트 (8/23/2012): 내가 Spark를 좋아하는 중요한 이유가 하나 더 있다: 14,000라인의 코드. 이것은 다른 빅 데이터를 위한 소프트웨어들보다 훨씬 간단한 코드다.
Spark의 코드는 작고, 확장성이 있으며, 수정해볼 수도 있다.
아래의 그림은 Amp Camp에서 Matei의 마지막 발표에서 나왔다 (LOC = 코드 라인 수):

그림은 Matei Zaharia로부터)
저자 : Ben Lorica
역자 : 한승균
원문 : Seven reasons why I like Spark
Spark는 빅 데이터 툴킷 분야에서 중요한 위치를 차지하게 될 것이다.
이번 주에 UC 버클리에서 열린 Amp Camp는 Spark - 오픈 소스, 인-메모리 기반의 클러스터 컴퓨팅 프레임워크인 - 를 소개하는 데에 많은 부분을 할애했다. 지난 달에 Spark를 사용해본 후에, 나는 나의 빅 데이터 툴킷 중에서 Spark를 가장 중요하게 생각하기 시작했다. 여기, 그 이유가 있다:
하둡 통합: Spark는 HDFS에 저장되어 있는 파일을 사용할 수 있다. 이것은 하둡 생태계에 투자된 양을 생각해보면 매우 중요한 특징이다. Spark와 MapR을 함께 사용하는 것은 매우 쉽다.
Spark 대화형 쉘: Spark는 Scala로 개발되었으며, Spark만의 Scala 인터프리터를 사용한다. 이것을 사용하면 간단한 코드를 테스트 하는데 엄청나게 편리하다.
Spark 분석 스위트:
(그림은 Matei Zaharia로부터)
Spark는 대화형 질의 분석기(Shark), 대용량 그래프 처리 및 분석기(Bagel), 실시간 분석기(Spark Streaming) 등을 함께 제공한다. 여러가지 툴들을 혼재해서 사용하지 않고(예를 들어, Hive, Hadoop, Mahout, S4/Storm), 하나의 프로그래밍 패러다임만 배우면 된다. SQL 지지자들을 위한 보너스가 하나 더 있다면, Shark가 Hive보다 더 빠르다는 것이다. Spark를 클라우드에서 돌리고 싶다면, EC2 스크립트들을 사용할 수 있다.
회복 가능한 분산 데이터 셋(RDD"s):
RDD"s는 노드들의 클러스터에 걸쳐, 메모리에 캐싱되어 있는 분산 객체다. 이것은 Spark에서 사용하는 기본 데이터 객체로, 중요한 점은 결함 허용(fault tolerance) 능력이 기본적으로 제공된다는 것이다: RDD"s는 무언가 잘못되면 자동으로 그것을 재생성한다. 만약 무언가 테스트해야 한다면, Spark 대화형 쉘에서 대화식으로 RDD"s를 사용할 수도 있다.
분산 연산자들:
Map과 Reduce에서 벗어나면, RDD"s에서 사용할 수 있는 많은 연산자들이 존재한다. 이것들이 어떻게 동작하는지에 대해 익숙해지고 난 후, 나는 기본적인 기계 학습과 데이터 처리 알고리즘을 이 프레임워크에서 사용할 수 있도록 변환시키기 시작했다.
한번 배워두기만 하면... 반복적인 프로그램들
어떤 곳에서든 생산적이기 위해서는 그만큼 노력이 필요하다. Spark 역시 예외는 아니다. 나는 Scala를 전혀 몰랐기 때문에, 우선 이 새로운 언어에 익숙해져야 했다 (보아하니, 이들은 밑줄을 좋아하는 것 같다 - 여기, 여기, 그리고 여기를 좀 보라). Scala를 넘어서면 Shark(Spark의 "SQL"), 그리고 Java와 Python API도 사용할 수 있다.
Spark를 시작하기 위해서 예제들을 사용할 수 있지만, 나는 더 중요한 것은 이 내장된 분산 연산자들에 익숙해지는 것이라고 생각한다. 내가 RDD"s와 연산자들을 배우고 난 후에는, 몇 가지의 기계 학습과 데이터 처리 알고리즘을 구현하기 위해 반복적으로 프로그램을 만들었다. (Spark가 데이터를 메모리에 분산하고 캐싱하기 때문에, 거대한 데이터 셋에서도 꽤 빠른 기계 학습 프로그램을 만들 수 있다.)
벌써 제품들이 사용하고 있다
정말로 사람들이 Spark를 사용할까? 사용하는 회사 리스트가 아직 짧긴 하지만, 샌프란시스코의 Spark Meetup과 Amp Camp의 크기를 보면, 더 많은 회사들이 Spark를 사용할 것이라고 기대한다. (만약 당신이 샌프란시스코의 Bay Area에 살고 있다면, 우리가 Aribnb와 함께 새로운 분산 데이터 처리 Meetup을 시작했다. 그리고 여기에서 Spark에 대해서도 이야기할 것이다.)
업데이트 (8/23/2012): 내가 Spark를 좋아하는 중요한 이유가 하나 더 있다: 14,000라인의 코드. 이것은 다른 빅 데이터를 위한 소프트웨어들보다 훨씬 간단한 코드다.
Spark의 코드는 작고, 확장성이 있으며, 수정해볼 수도 있다.
아래의 그림은 Amp Camp에서 Matei의 마지막 발표에서 나왔다 (LOC = 코드 라인 수):
그림은 Matei Zaharia로부터)
TAG :
이전 글 : 대량 데이터와 설계상의 융합
다음 글 : 데이터 주짓수: 제품에서 활용되는 데이터의 미학

최신 콘텐츠