IT/모바일
제공 : 한빛 네트워크
저자 : Alistair Croll
역자 : 김상현
원문 : Big data is our generation’s civil rights issue, and we don’t know it
데이터는 그것이 어떻게 사용될 수 있는지 연관지어 생각해야 한다.
데이터가 사람들의 삶을 침범한 것이 아니라, 데이터를 어떻게 사용해야 하는가에 대한 통제의 부족이 사람들의 삶을 침범했다.
소위 빅 데이터라고 불려지는 것은 정보의 양을 의미하는 것이 아니다. 전혀 거대할 필요가 없다. 오히려, 이것은 데이터를 분석하는 기초 경제학의 재고(reconsideration)라고 할 수 있다.
수 십년 간 데이터베이스의 3가지 속성들 간에 날카로운 신경전이 존재해 왔다. 데이터를 빠르게 하고, 거대화 하고, 다양화 하는 것이 바로 그것이다. 중요한 점은 3가지를 동시에 소유할 수 없다는 것이다.
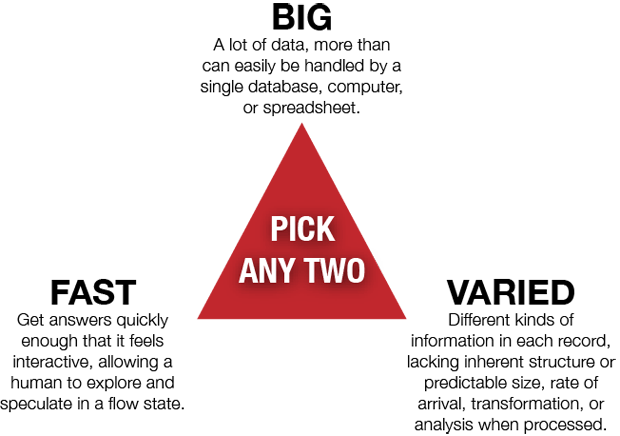
나는 처음에 이것을 "데이터가 가지고 있는 3가지 V" 라고 들었다. 크기(Volume), 다양성(Variety), 속도(velocity). 전통적으로 2가지를 소유하기는 쉽지만 3가지 모두를 소유하기에는 정말 많은 비용이 든다.
하둡과 같은 클라우드의 출현과 무어의 법칙의 기술적 진보는 지금 이 시대에는 데이터 분석에 많은 비용이 소요되지 않는다는 것을 의미한다. 그리고 어떤 것이 사실상 공짜가 되어 비용이 저렴해질 때에는 큰 변화가 생기게 된다. 증기기관의 출현 또는 디지털 음악의 출판, 또는 홈 프린팅만 보더라도 그 변화를 알 수 있다. 풍부함이 부족한 것을 대체하면서 새로운 비즈니스 모델을 만들게 된다.
오래 전에는 데이터가 부족한 모델로 여겨졌기 때문에 기업들은 무엇을 먼저 수집해야 할지 결정한 후에야 데이터를 수집했다. 고전적인 데이터웨어 하우스는 색상, 지역, 그리고 크기에 따른 판매 형태들을 추적해 왔다. 무엇을 저장하고 어떻게 저장할 것인가 결정하는 행동은 스키마를 설계하는 것으로 불려지게 되었고, 여러 가지 면에서 이런 행동은 누군가가 데이터에 대해 무엇인가를 결정하는 순간이 되었다. 이것은 즉각적인 맥락이다.
그것은 반복이 필요하다.
당신은 데이터의 스키마를 정의하는 순간에 대해 무엇인가를 결정한다.
새롭고 데이터가 풍부한 모델에서는 먼저 데이터를 수집하고 나중에 질문을 요구한다. 스키마는 수집이 끝난 후에 나타난다. 실제로 Splunk, Palantir와 같은 빅 데이터의 성공사례는 상을 받을 만 하다. 바로 데이터를 수집한 후에 내용을 만드는 능력 때문이다. 그래서 때로는 스키마가 존재하지 않는 쿼리(schema-less query)라고 불려지기도 한다. 이것은 우리가 데이터가 무엇인지 결정하기 전에 오랜 시간 동안 정보를 수집한다는 것을 의미한다.
그리고 이것은 위험한 방법이다.
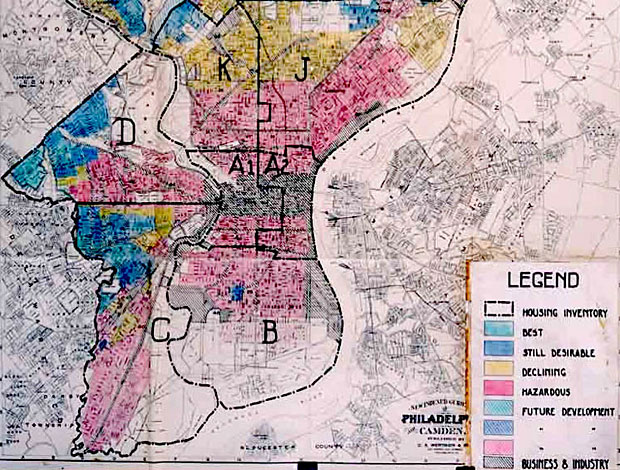
은행 관리자가 특정영역의 주민들(아래 빨간 지역)의 대출을 제한하려고 할 때 의회는 그것을 저지했다. 그들은 인종에 따라서 대출 정책을 차별화 하는 것이 불법이라는 법률을 제정했다.
"개인화"는 차별의 다른 말이다. 만약 당신에 대해 아는 것을 바탕으로 해서 당신에게 맞춘다면 우리는 차별하는 것이 아니다. 그것은 바로 더 나은 서비스이다.
한가지 예로, American Express는 고객이 높은 등급의 신용등급을 가지고 있을지라도 쇼핑장소에 따라서 신용한도를 조정하기 위해 구매 내역을 사용했다. 우리는 이 약삭빠른 행동을 맞춤형 신용카드 한도 제한에서부터 운전자 프로파일을 기반으로 한 자동차 보험에 이르기까지 모든 곳에서 볼 수 있다. 이런 점에서 빅 데이터는 인권에 관한 이슈이다. 하지만 일반적으로 사회는 처리할 수 있는 방법을 제대로 갖추지 못하고 있다.
우리는 이 약삭빠른 행동을 맞춤형 신용카드 한도 제한에서부터 운전자 프로파일을 기반으로 한 자동차 보험에 이르기까지 모든 곳에서 볼 수 있다. 이런 점에서 빅 데이터는 인권에 관한 이슈이다. 하지만 일반적으로 사회는 처리할 수 있는 방법을 제대로 갖추지 못하고 있다.
우리는 사람들에 대한 정보를 추측하는데 사람들의 기호를 잘 사용한다. OKcupid의 2010년 블로그 포스트 중에 "The Real Stuff White People Like"에서는 인종을 짐작하기 위해 정보를 얼마나 쉽게 사용할 수 있는지 보여주고 있다. 이건 정말로 눈을 번쩍 뜨게 해주는 일이다. (그리고 그 글을 쓴 사람들은 그들이 배운 것에 대해서는 포함하지 않았다. 그 중 어떤 부분은 약간의 논란이 있기도 했다.) 그들은 단순히 다른 사람들이 사용하지 않는 단어를 사용하는 하나의 그룹을 살펴봤을 뿐이었다. 그 결과로 특정 인종이나 성별에 따른 "trigger" 단어 목록을 만들 수 있었다
지금 이것은 거꾸로 실행된다. 만약 이런 것들과 같이 당신을 알았거나 블로그 포스트나 페이스북 또는 트위터에서 그것들에 대해서 언급한 당신을 보았다면 이것은 당신의 성별, 인종, 그리고 당신의 종교와 성적 기호까지도 알 수 있는 좋은 기회가 된다. 그리고 나는 당신에 대한 마켓팅 전락을 세울 수 있다. 이것이 인권에 대한 이슈를 야기하고 있다.
만약 당신이 듣는 음악에 관한 정보를 수집했다면, 당신은 내가 새로운 음악을 제안하거나 당신의 친구들과 공유하기 위해 그 정보를 사용할거라고 예측할지도 모른다. 그러나 그 대신 나는 당신의 인종적 배경에 대해 추측하는데 사용할 수 있다. 그리고 당신이 대출하는 것을 거부하는 데에 그 정보를 활용할 수 있다.
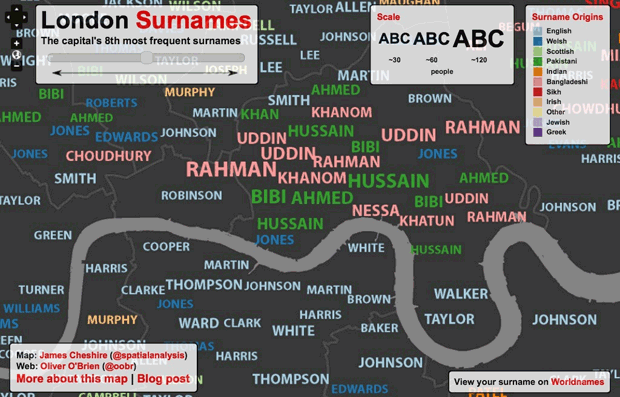
다른 예는 무엇이 있을까? 얼마전에 런던에서 사람들의 성 정보가 인종 경계 지도를 만드는데 얼마나 유용한지 토론한 런던의 빅 데이터 세미나를 보고 나서 쓴 Private Data In Public Ways를 살펴보자.
Malte Spitz가 말한 이 Ted토크는 오늘날 시민을 추적 일을 설명하는데 큰 역할을 하고 있다. 그리고 그는 오늘날 정부가 하는 방법처럼 Stasi(비밀경찰)이 핸드폰 통화기록을 봤다면 베를린 장벽이 무너졌을지에 대해 추측해보고 있다.
그러면 우리는 정보가 사용되는 방법을 어떻게 규제할수 있을까?
적절하게 처리할수 있는 유일한 방법은 어떤 데이터든 이것을 사용할 수 있는 방법과 연결하는 것이다. 예를 들어, 나의 음악적 성향은 은행을 결정하는 것이 아닌 노래를 추천하는 곳에 사용되어야 한다.
권한으로 묶여있어서 느리고 수수께끼 같고 부담스럽고 실행하기 어렵고 혁신하기 어려운 데이터는 암호화를 통해서 수행할 수 있다. 또는 스팸 메일을 규제하는 것과 같이 법 제정을 통해서 실행시킬 수 있다. 이것은 멋지긴 하지만 집행하기가 어렵다.
수량화된 사회에서 우리가 살아가고 사랑하고 일하고 즐기는 것을 향상시킬 수 있는 방법에 대한 예는 무수히 많다. 빅 데이터는 병이 발생하는 것을 찾는데 도움이 되고 학생들이 어떻게 배워야 하는지, 정치적인 당파성을 어떻게 드러내야 하는지를 알려줄 것이다. 그리고 통근자들에게 간단한 예를 선택해줌으로써 수많은 비용을 줄이는데 도움이 될 것이다. 폭발적인 인구증가와 기후변화, 에너지 공황과 같이 이 땅에 살기 위해 노력하는 것처럼 단순하게 무시할 수 없는 이익들이 있다.
그러나 정부는 정보에 의존하는 것에 견제를 통한 균형이 필요하다. 그리고 이러한 의존이 어떻게 개인 사생활을 침해하는지에 대한 균형과 사회와 우리가 생각해보지 못한 사회와 도덕적 이슈를 창조해야 한다. 유권자 대부분이 그것에 대해서 생각하고 있지는 않지만 그들의 구매 성향에는 영향을 미친다.
참 재미있는 일이다.
저자 : Alistair Croll
역자 : 김상현
원문 : Big data is our generation’s civil rights issue, and we don’t know it
데이터는 그것이 어떻게 사용될 수 있는지 연관지어 생각해야 한다.
데이터가 사람들의 삶을 침범한 것이 아니라, 데이터를 어떻게 사용해야 하는가에 대한 통제의 부족이 사람들의 삶을 침범했다.
소위 빅 데이터라고 불려지는 것은 정보의 양을 의미하는 것이 아니다. 전혀 거대할 필요가 없다. 오히려, 이것은 데이터를 분석하는 기초 경제학의 재고(reconsideration)라고 할 수 있다.
수 십년 간 데이터베이스의 3가지 속성들 간에 날카로운 신경전이 존재해 왔다. 데이터를 빠르게 하고, 거대화 하고, 다양화 하는 것이 바로 그것이다. 중요한 점은 3가지를 동시에 소유할 수 없다는 것이다.
나는 처음에 이것을 "데이터가 가지고 있는 3가지 V" 라고 들었다. 크기(Volume), 다양성(Variety), 속도(velocity). 전통적으로 2가지를 소유하기는 쉽지만 3가지 모두를 소유하기에는 정말 많은 비용이 든다.
하둡과 같은 클라우드의 출현과 무어의 법칙의 기술적 진보는 지금 이 시대에는 데이터 분석에 많은 비용이 소요되지 않는다는 것을 의미한다. 그리고 어떤 것이 사실상 공짜가 되어 비용이 저렴해질 때에는 큰 변화가 생기게 된다. 증기기관의 출현 또는 디지털 음악의 출판, 또는 홈 프린팅만 보더라도 그 변화를 알 수 있다. 풍부함이 부족한 것을 대체하면서 새로운 비즈니스 모델을 만들게 된다.
오래 전에는 데이터가 부족한 모델로 여겨졌기 때문에 기업들은 무엇을 먼저 수집해야 할지 결정한 후에야 데이터를 수집했다. 고전적인 데이터웨어 하우스는 색상, 지역, 그리고 크기에 따른 판매 형태들을 추적해 왔다. 무엇을 저장하고 어떻게 저장할 것인가 결정하는 행동은 스키마를 설계하는 것으로 불려지게 되었고, 여러 가지 면에서 이런 행동은 누군가가 데이터에 대해 무엇인가를 결정하는 순간이 되었다. 이것은 즉각적인 맥락이다.
그것은 반복이 필요하다.
당신은 데이터의 스키마를 정의하는 순간에 대해 무엇인가를 결정한다.
새롭고 데이터가 풍부한 모델에서는 먼저 데이터를 수집하고 나중에 질문을 요구한다. 스키마는 수집이 끝난 후에 나타난다. 실제로 Splunk, Palantir와 같은 빅 데이터의 성공사례는 상을 받을 만 하다. 바로 데이터를 수집한 후에 내용을 만드는 능력 때문이다. 그래서 때로는 스키마가 존재하지 않는 쿼리(schema-less query)라고 불려지기도 한다. 이것은 우리가 데이터가 무엇인지 결정하기 전에 오랜 시간 동안 정보를 수집한다는 것을 의미한다.
그리고 이것은 위험한 방법이다.
은행 관리자가 특정영역의 주민들(아래 빨간 지역)의 대출을 제한하려고 할 때 의회는 그것을 저지했다. 그들은 인종에 따라서 대출 정책을 차별화 하는 것이 불법이라는 법률을 제정했다.
"개인화"는 차별의 다른 말이다. 만약 당신에 대해 아는 것을 바탕으로 해서 당신에게 맞춘다면 우리는 차별하는 것이 아니다. 그것은 바로 더 나은 서비스이다.
한가지 예로, American Express는 고객이 높은 등급의 신용등급을 가지고 있을지라도 쇼핑장소에 따라서 신용한도를 조정하기 위해 구매 내역을 사용했다.
Johnson은 American Express가 자신의 신용한도를 낮춘 이유를 읽고는 입을 다물지 못했다고 말한다. "최근에 기관에서 카드를 사용한 사람들은 American Express와 안 좋은 상환기록을 가지고 있다."
우리는 이 약삭빠른 행동을 맞춤형 신용카드 한도 제한에서부터 운전자 프로파일을 기반으로 한 자동차 보험에 이르기까지 모든 곳에서 볼 수 있다. 이런 점에서 빅 데이터는 인권에 관한 이슈이다. 하지만 일반적으로 사회는 처리할 수 있는 방법을 제대로 갖추지 못하고 있다.
우리는 사람들에 대한 정보를 추측하는데 사람들의 기호를 잘 사용한다. OKcupid의 2010년 블로그 포스트 중에 "The Real Stuff White People Like"에서는 인종을 짐작하기 위해 정보를 얼마나 쉽게 사용할 수 있는지 보여주고 있다. 이건 정말로 눈을 번쩍 뜨게 해주는 일이다. (그리고 그 글을 쓴 사람들은 그들이 배운 것에 대해서는 포함하지 않았다. 그 중 어떤 부분은 약간의 논란이 있기도 했다.) 그들은 단순히 다른 사람들이 사용하지 않는 단어를 사용하는 하나의 그룹을 살펴봤을 뿐이었다. 그 결과로 특정 인종이나 성별에 따른 "trigger" 단어 목록을 만들 수 있었다
지금 이것은 거꾸로 실행된다. 만약 이런 것들과 같이 당신을 알았거나 블로그 포스트나 페이스북 또는 트위터에서 그것들에 대해서 언급한 당신을 보았다면 이것은 당신의 성별, 인종, 그리고 당신의 종교와 성적 기호까지도 알 수 있는 좋은 기회가 된다. 그리고 나는 당신에 대한 마켓팅 전락을 세울 수 있다. 이것이 인권에 대한 이슈를 야기하고 있다.
만약 당신이 듣는 음악에 관한 정보를 수집했다면, 당신은 내가 새로운 음악을 제안하거나 당신의 친구들과 공유하기 위해 그 정보를 사용할거라고 예측할지도 모른다. 그러나 그 대신 나는 당신의 인종적 배경에 대해 추측하는데 사용할 수 있다. 그리고 당신이 대출하는 것을 거부하는 데에 그 정보를 활용할 수 있다.
다른 예는 무엇이 있을까? 얼마전에 런던에서 사람들의 성 정보가 인종 경계 지도를 만드는데 얼마나 유용한지 토론한 런던의 빅 데이터 세미나를 보고 나서 쓴 Private Data In Public Ways를 살펴보자.
Malte Spitz가 말한 이 Ted토크는 오늘날 시민을 추적 일을 설명하는데 큰 역할을 하고 있다. 그리고 그는 오늘날 정부가 하는 방법처럼 Stasi(비밀경찰)이 핸드폰 통화기록을 봤다면 베를린 장벽이 무너졌을지에 대해 추측해보고 있다.
그러면 우리는 정보가 사용되는 방법을 어떻게 규제할수 있을까?
적절하게 처리할수 있는 유일한 방법은 어떤 데이터든 이것을 사용할 수 있는 방법과 연결하는 것이다. 예를 들어, 나의 음악적 성향은 은행을 결정하는 것이 아닌 노래를 추천하는 곳에 사용되어야 한다.
권한으로 묶여있어서 느리고 수수께끼 같고 부담스럽고 실행하기 어렵고 혁신하기 어려운 데이터는 암호화를 통해서 수행할 수 있다. 또는 스팸 메일을 규제하는 것과 같이 법 제정을 통해서 실행시킬 수 있다. 이것은 멋지긴 하지만 집행하기가 어렵다.
수량화된 사회에서 우리가 살아가고 사랑하고 일하고 즐기는 것을 향상시킬 수 있는 방법에 대한 예는 무수히 많다. 빅 데이터는 병이 발생하는 것을 찾는데 도움이 되고 학생들이 어떻게 배워야 하는지, 정치적인 당파성을 어떻게 드러내야 하는지를 알려줄 것이다. 그리고 통근자들에게 간단한 예를 선택해줌으로써 수많은 비용을 줄이는데 도움이 될 것이다. 폭발적인 인구증가와 기후변화, 에너지 공황과 같이 이 땅에 살기 위해 노력하는 것처럼 단순하게 무시할 수 없는 이익들이 있다.
그러나 정부는 정보에 의존하는 것에 견제를 통한 균형이 필요하다. 그리고 이러한 의존이 어떻게 개인 사생활을 침해하는지에 대한 균형과 사회와 우리가 생각해보지 못한 사회와 도덕적 이슈를 창조해야 한다. 유권자 대부분이 그것에 대해서 생각하고 있지는 않지만 그들의 구매 성향에는 영향을 미친다.
참 재미있는 일이다.
TAG :

최신 콘텐츠