![]() 제이 알아마르, 마르턴 흐루턴도르스트
제이 알아마르, 마르턴 흐루턴도르스트
5일 전
![]() 2.3K
2.3K
[인공 지능]은 지능적인 기계, 특히 지능적인 컴퓨터 프로그램을 만드는 과학과 공학입니다.
인공 지능 분야는 컴퓨터를 활용해 인간 지능이 어떻게 작동하는지 이해하려고 연구합니다.
하지만 AI 가 생물학적으로 관찰되는 방법에만 국한되지 않습니다.
_존 매카시, 2007
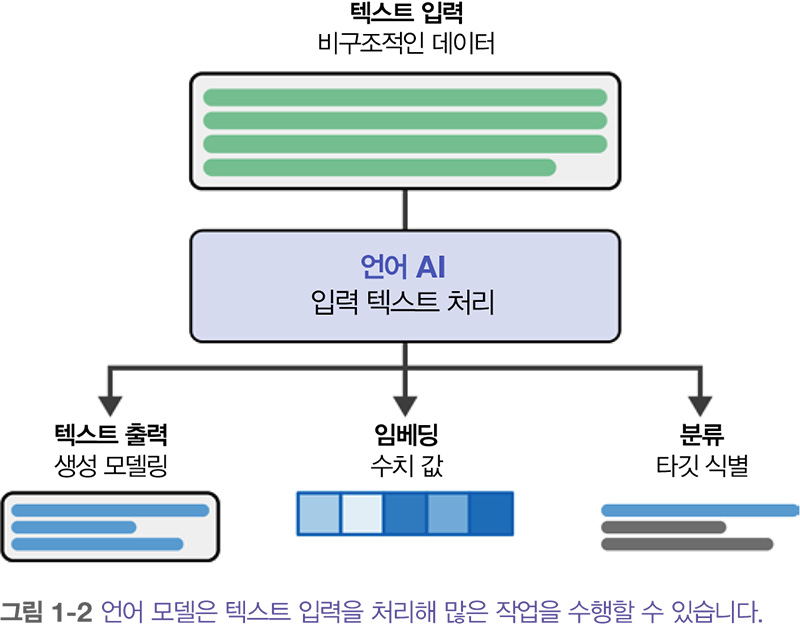
인공 지능(AI)이란 용어는 음성 인식, 언어 번역, 시각 인식 등 인간 지능에 가까운 작업을 수행하는 컴퓨터 시스템을 설명하는 데 사용됩니다. 즉, 사람의 지능이 아니라 소프트웨어 지능을 말합니다. AI가 발전함에 따라 이 용어는 다양한 시스템을 설명하는 데 사용되었고, 그중 일부는 실제로는 지능적인 동작이 없는 경우도 있습니다. 예를 들어, 컴퓨터 게임의 NPC는 대부분 if-else 로직에 불과하지만 종종 AI로 언급됩니다.
언어 AI Language AI 는 인간 언어를 이해, 처리, 생성할 수 있는 기술을 개발하는 데 초점을 맞춘 AI의 하위 분야입니다. 종종 자연어 처리(NLP)와 혼용되어 사용되는데, 머신러닝 방법이 언어 처리 문제에서 계속해서 성과를 내고 있기 때문입니다.
책 『핸즈온 LLM』에서는 책 전반에 걸쳐 언어 모델 분야에서 중요한 역할을 했던 모델에 초점을 맞추고 있습니다. 이는 LLM만 살펴보는 것 이상을 의미합니다. 하지만 다음과 같은 질문이 생깁니다. 대규모 언어 모델이란 무엇일까요? 이 질문에 대한 답을 얻기 위해 먼저 언어 AI의 역사를 살펴 보겠습니다.
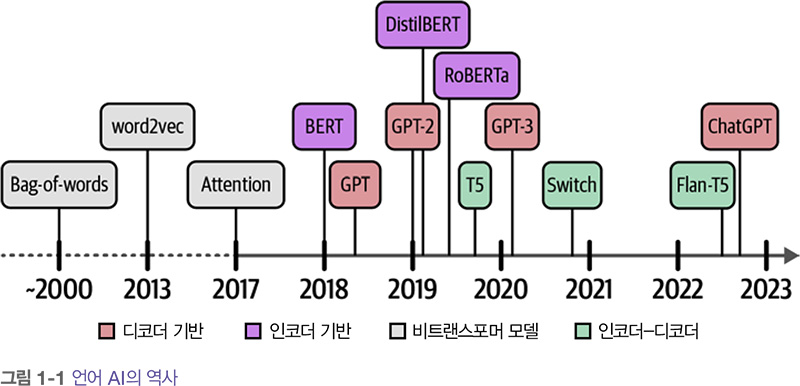
언어 AI의 역사에는 언어를 표현하고 생성하기 위한 많은 알고리즘과 모델이 출현했습니다. 하지만 언어는 컴퓨터에게 어려운 개념입니다. 텍스트는 태생적으로 비구조적이고 (개별 문자인) 0과 1로 표현될 때 의미를 잃습니다. 결과적으로 언어 AI의 역사에는 컴퓨터가 쉽게 사용할 수 있도록 언어를 구조적으로 표현하려는 노력이 계속되어 왔습니다.
언어 모델의 역사는 비구조적인 텍스트를 표현하는 한 방법인 BoW bag-of-words 라는 기법으로 시작합니다. 1950년대에 처음 언급되었지만 2000년대가 되어서야 인기를 얻었죠.
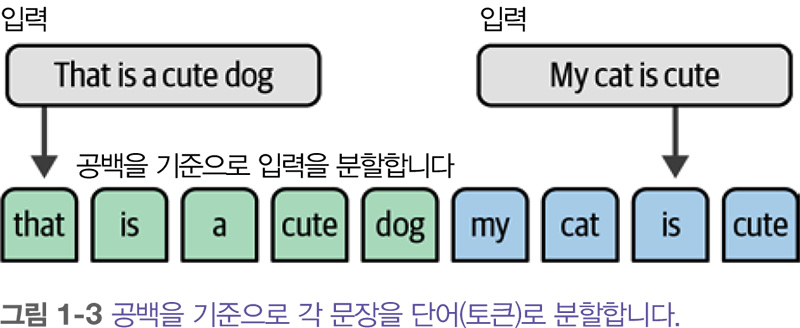
BoW의 작동 방식은 다음과 같습니다. 수치 표현을 만들려는 두 개의 문장이 있다고 가정해 보죠. BoW 모델의 첫 번째 단계는 문장을 개별 단어나 부분단어 subword (토큰)로 분할하는 과정인 토큰화 tokenization 입니다. 가장 널리 사용되는 토큰화 방법은 공백을 기준으로 개별 단어로 분할하는 것입니다.
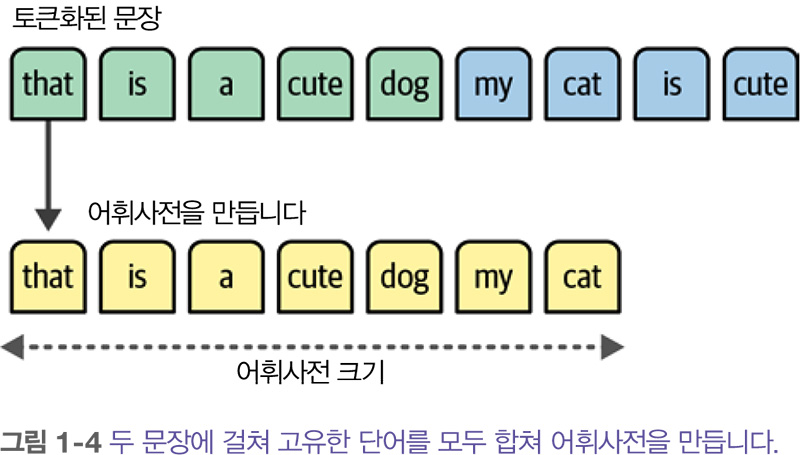
하지만 개별 단어 사이에 공백이 없는 중국어 같은 언어에는 이 같은 방법이 불리합니다. 이럴 때에는 토큰화 다음에 각 문장의 고유한 단어를 모두 합쳐서 어휘사전을 만듭니다. 이를 사용해 문장을 표현할 수 있습니다.
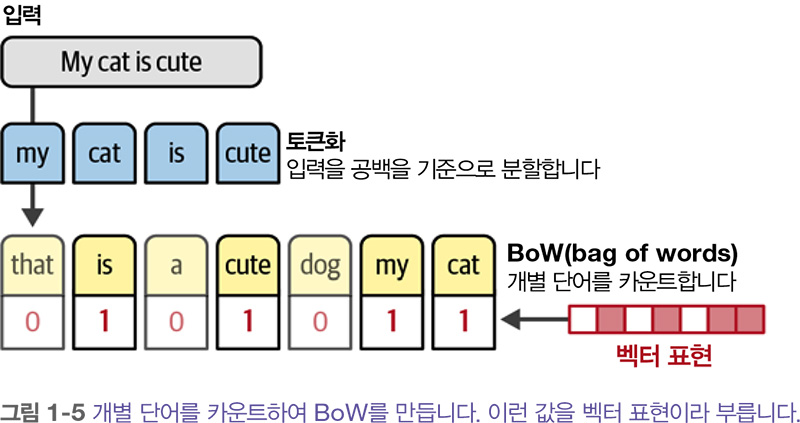
어휘사전을 사용하여 각 문장에 단어가 얼마나 많이 등장하는지 헤아립니다. 그래서 이 방법을 단어 가방 bag of words 이라고 합니다. 결국 BoW는 위의 그림과 같이 벡터 또는 벡터 표현이라 부르는 수치의 형태로 텍스트를 표현하는 것이 목표입니다. 이 책에서는 이런 모델을 표현 모델 representation model 이라 부르겠습니다.
BoW가 고전적인 방법이긴 하지만, 완전히 쓸모가 없는 것은 아닙니다. 『핸즈온 LLM』5장에서 최신 언어 모델을 보완하는 데 사용하는 방법을 통해 좀 더 자세히 알아봅니다.
BoW의 접근 방식은 우아하지만 단점이 있습니다. BoW는 단어의 의미나 문맥을 반영하지 못하는 한계가 있다는 것이죠. 이를 개선한 것이 word2vec입니다.
2013년에 개발된 word2vec은 임베딩으로 텍스트의 의미를 포착하는 데 성공한 첫 번째 시도였습니다. 임베딩은 데이터의 의미를 포착하기 위한 벡터 표현입니다. 이렇게 하기 위해 word2vec은 위키백과와 같은 방대한 텍스트 데이터에서 훈련하여 단어의 의미를 나타내는 표현을 학습합니다.
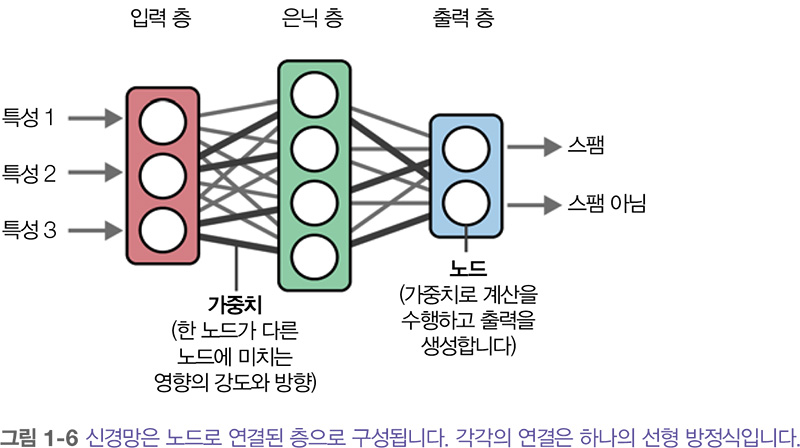
word2vec은 신경망을 사용해 의미 표현을 생성합니다. 이 신경망은 여러 층이 서로 연결되어 구성되며, 각 층은 정보를 처리하는 여러 노드로 이루어져 있습니다. 아래에 나타나 있듯이 신경망은 여러 개의 층으로 구성될 수 있으며, 한 층의 노드와 다음 층의 노드를 잇는 연결에는 입력값에 따라 특정한 가중치가 부여됩니다. 이런 가중치를 종종 모델의 파라미터 parameter 라고 부릅니다.
word2vec은 신경망을 사용해 주어진 문장에서 다음에 어떤 단어가 등장하는지를 살펴봄으 로써 단어 임베딩을 생성합니다. 먼저 어휘사전에 있는 모든 단어에 대해서 랜덤하게 초기화된 일련의 값(예를 들면 50개의 값)을 단어 임베딩으로 할당합니다.
그다음 아래 그림에 나타나 있듯이 훈련 스텝마다 훈련 데이터에서 단어 쌍을 가져와서 모델이 문장 안에서 단어 쌍이 이웃에 나타날 가능성이 있는지 예측하게 합니다.

훈련 과정 동안 word2vec은 단어 사이 관계를 학습하고 이 정보를 임베딩에 저장합니다. 두단어가 이웃에 나타날 가능성이 높다면 두 단어의 임베딩은 서로 매우 가까워집니다. 그 반대도 마찬가지입니다.
이렇게 만들어진 임베딩은 단어의 의미를 포착합니다. 하지만 정확히 무슨 뜻일까요? 이 현상을 설명하기 위해 아주 단순화하여 ‘apple’, ‘baby’ 같은 단어의 임베딩이 있다고 가정해 보죠. 임베딩은 단어의 속성을 표현함으로써 의미를 포착합니다. 예를 들어 단어 ‘baby’는 ‘newborn’과 ‘human’ 속성에서 높은 점수를 가질 수 있지만 ‘apple’은 이런 속성에서 낮은 값을 가질 수 있습니다.
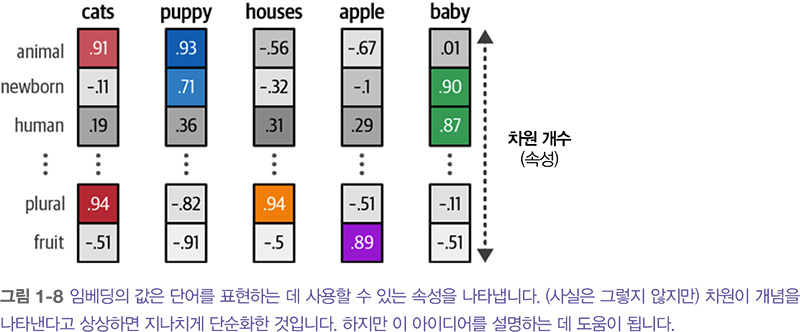
임베딩은 단어의 의미를 표현하기 위해 여러 속성을 가질 수 있습니다. 임베딩의 크기가 고정이기 때문에 임베딩의 속성은 단어의 정신적 표상 mental representation 을 만들도록 선택됩니다. 실제로 이런 속성은 매우 모호하여 하나의 객체나 사람이 식별할 수 있는 개념과 좀처럼 연관되지 않습니다. 하지만 이런 속성을 합치면 컴퓨터에게 의미가 있으며 사람의 언어를 컴퓨터 언어로 바꾸는 좋은 방법이 됩니다.

임베딩은 단어 사이에 있는 의미의 유사성을 측정할 수 있기 때문에 매우 유용합니다. 다양한 거리 측정 방법을 사용해 한 단어가 다른 단어와 얼마나 가까운지 판단할 수 있습니다.위의 그림처럼 임베딩을 2차원 표현으로 압축하면 비슷한 의미의 단어가 가깝게 나타나는 경향을 볼 수 있습니다.
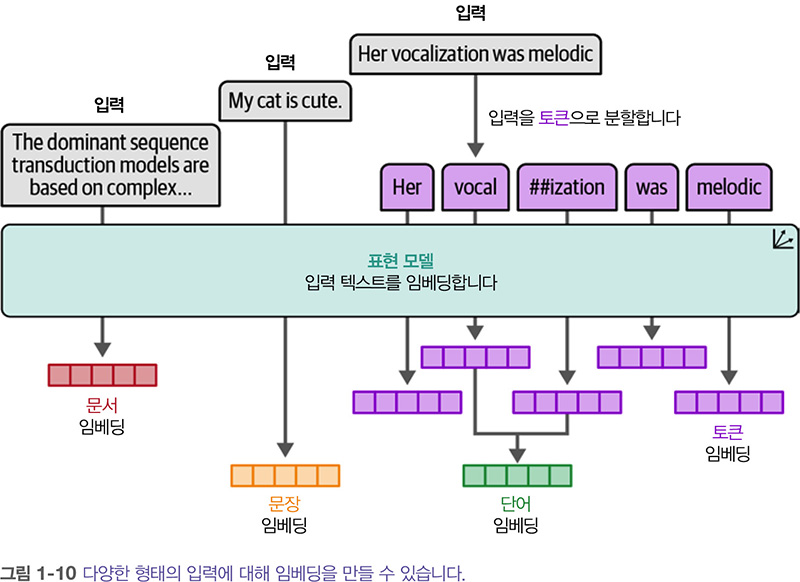
임베딩의 종류는 많습니다. 위의 그림에서 알 수 있듯이 단어 임베딩과 문장 임베딩은 다른 수준 (단어 vs 문장)의 추상화에 사용됩니다. 예를 들어 BoW는 전체 문서를 표현하므로 문서 수준에서 임베딩을 만듭니다. 반면에 word2vec은 단어에 대한 임베딩만 생성합니다. 임베딩은 분류, 클러스터링, 시맨틱 검색, RAG 등 다양한 분야에 활용되며 핵심적인 역할을 합니다.
word2vec의 훈련 과정은 정적이고 다운로드 가능한 단어 표현을 만듭니다. 예를 들어, 단어 ‘bank’는 문맥에 상관없이 항상 임베딩이 동일합니다. 하지만 ‘bank’가 은행이나 강둑을 의미할 수 있습니다. 즉 임베딩은 문맥에 따라 달라져야 합니다.
이런 텍스트를 인코딩하는 단계는 순환 신경망 recurrent neural network (RNN)으로 달성되었습니다. RNN은 연속적인 입력으로 시퀀스를 모델링할 수 있는 신경망의 한 종류입니다. 이렇게 하기 위해 RNN을 두 개의 작업에 사용합니다. 입력 문장을 인코딩 또는 표현하고, 출력 문장을 디코딩 또는 생성하는 작업입니다.
이 개념을 설명하기 위해 ‘I love llamas’란 문장을 네덜란드어 ‘Ik hou van lama's’로 번역하는 방법을 살펴보겠습니다.
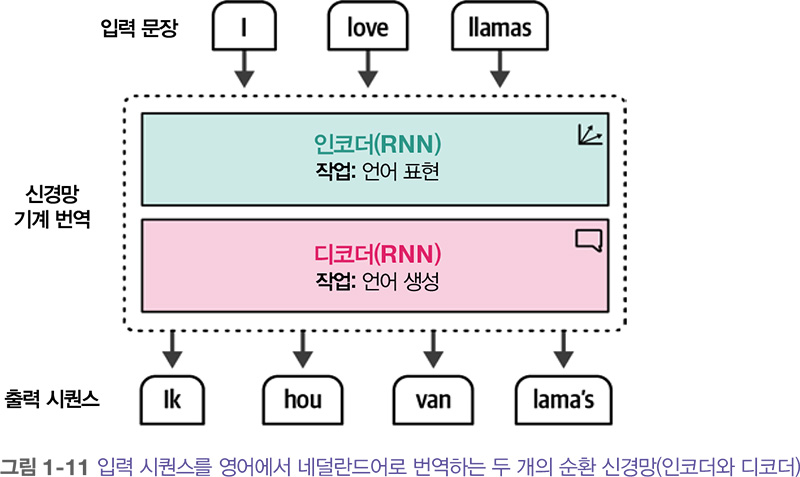
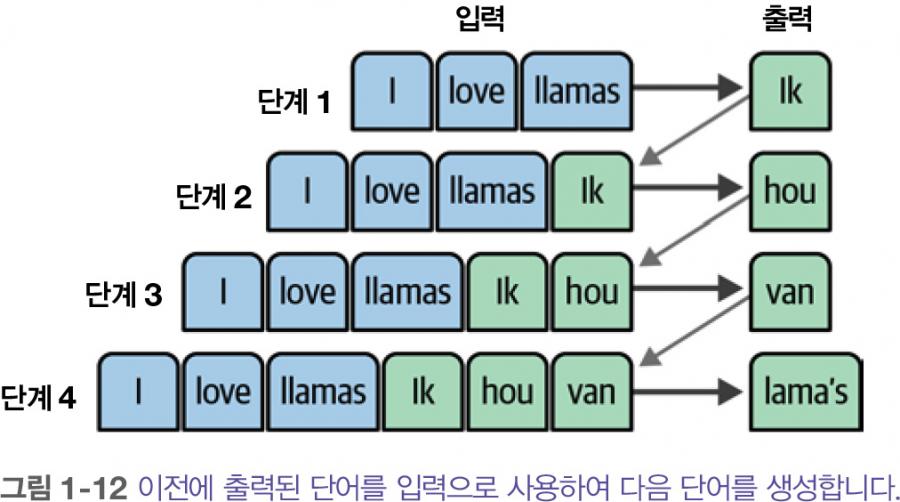
이 구조에서 각 단계는 자기회귀적 autoregressive 입니다. 즉, 이전에 생성한 모든 단어를 사용해 다음 단어를 생성합니다.
인코딩 단계의 목표는 입력을 가능한 한 잘 표현하여 디코더의 입력으로 사용되는 임베딩의 형태로 문맥을 생성하는 것입니다. 이 표현을 생성하기 위해 단어에 대한 입력으로 임베딩을 사용합니다. 즉 초기 표현으로 word2vec을 사용할 수 있죠. 입력은 물론 출력도 한 번에 하나씩 순차적으로 처리됩니다.
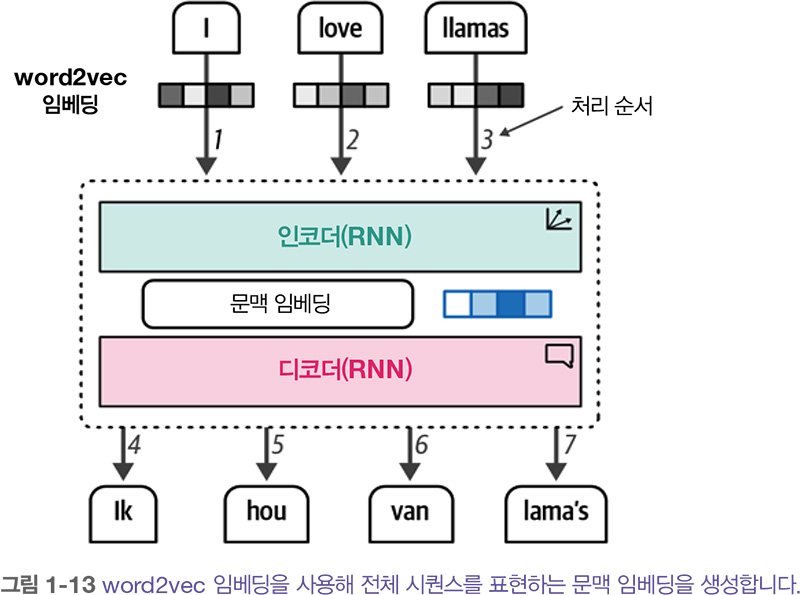
하지만 문맥 임베딩은 하나의 임베딩으로 전체 입력을 표현하기 때문에 긴 문장을 처리하기 어렵습니다. 2014년 이 구조를 크게 개선한 어텐션 attention 이라 불리는 방법이 소개되었습니다. 아래 그림에 나타난 어텐션을 사용하면 입력 시퀀스에서 서로 관련 있는 부분에 모델이 초점을 맞추고 해당 신호를 증폭할 수 있습니다. 어텐션은 주어진 문장에서 어떤 단어가 가장 중요한지 선택적으로 결정합니다.
예를 들어, 출력 단어 ‘lama's’는 ‘llamas’에 해당하는 네덜란드어입니다. 따라서 두 단어 사이의 어텐션이 높습니다. 마찬가지로 단어 ‘lama's’와 ‘I’는 관련이 없기 때문에 어텐션이 낮습니 다.
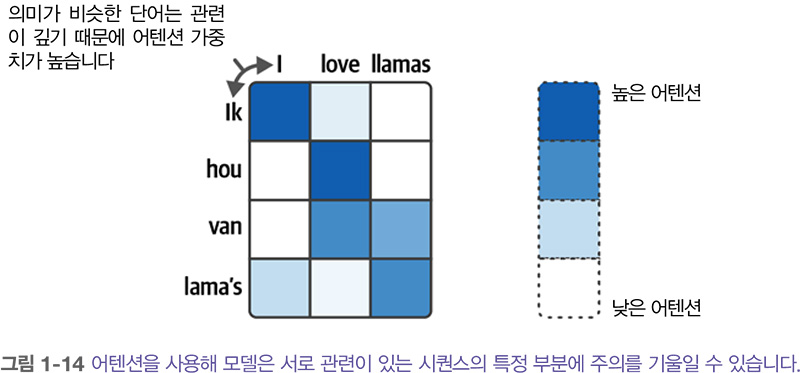
어텐션 메커니즘을 디코더 단계에 추가함으로써 RNN이 입력 시퀀스의 각 단어에 대해 출력 가능성에 관련된 신호를 생성할 수 있습니다. 문맥 임베딩을 디코더에 전달하는 대신 모든 입력 단어의 은닉 상태가 전달됩니다.
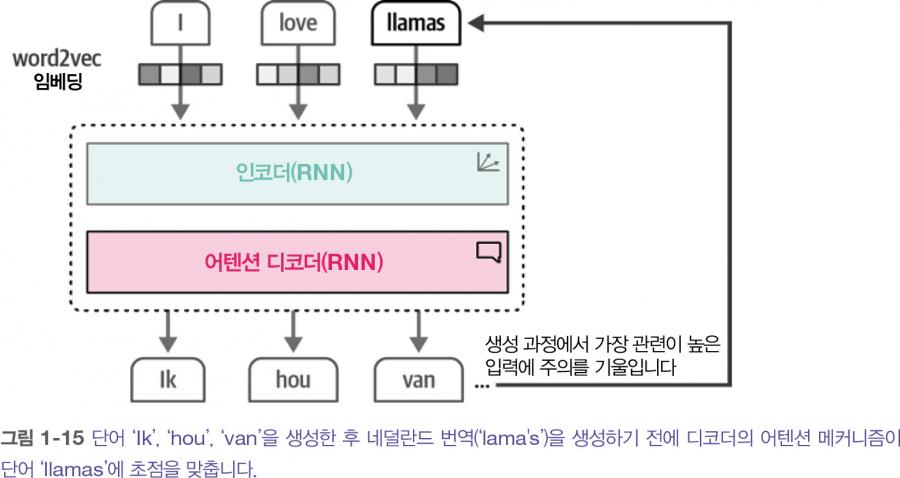
결과적으로 ‘Ik hou van lama's’를 생성하는 동안 RNN이 번역을 수행하기 위해 가장 주의를 기울일 단어를 추적합니다. word2vec과 비교하면 이 구조는 텍스트의 순차적 특징과 전체 문장에 주의를 기울임으로써 텍스트의 문맥을 표현할 수 있습니다. 하지만 이런 순차적 특징은 모델 훈련을 병렬화하는 데 방해가 됩니다.
어텐션의 진정한 힘과, 대규모 언어 모델의 놀라운 능력을 만들어 낸 동력은 2017년에 발표된 유명한 <Attention is all you need> 논문에서 소개되었습니다. 논문의 저자들은 어텐션 메커니즘만 사용하고 순환 신경망을 제거한 트랜스포머 Transformer 라는 신경망 구조를 제안했습니 다. 순환 신경망과 비교하면 트랜스포머는 병렬로 훈련할 수 있어 훈련 속도를 크게 높일 수 있습니다.
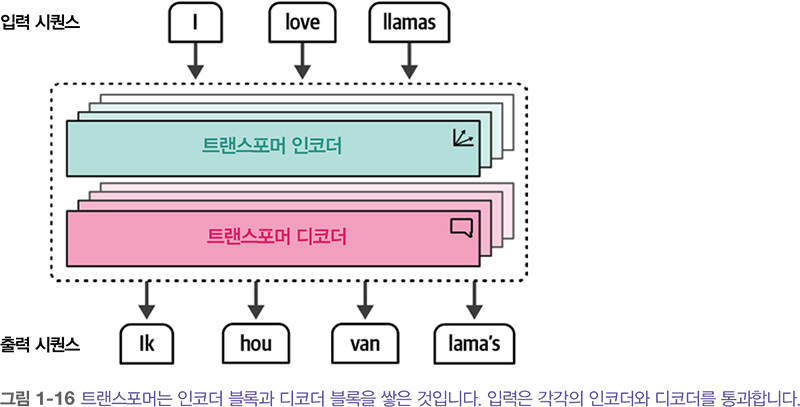
트랜스포머에서 인코더와 디코더는 차곡차곡 쌓여 있습니다. 트랜스포머도 자기회귀적이어서 이전에 생성된 모든 단어를 사용해서 새로운 단어를 생성합니다.
인코더와 디코더 블록은 어텐션 기능이 포함된 RNN을 활용하는 대신 어텐션을 중심으로 구동 됩니다. 트랜스포머의 인코더 블록은 아래에서 보듯이 셀프 어텐션 self-attention 과 피드포워드 신경망 feedforward neural network 두 부분으로 구성됩니다.
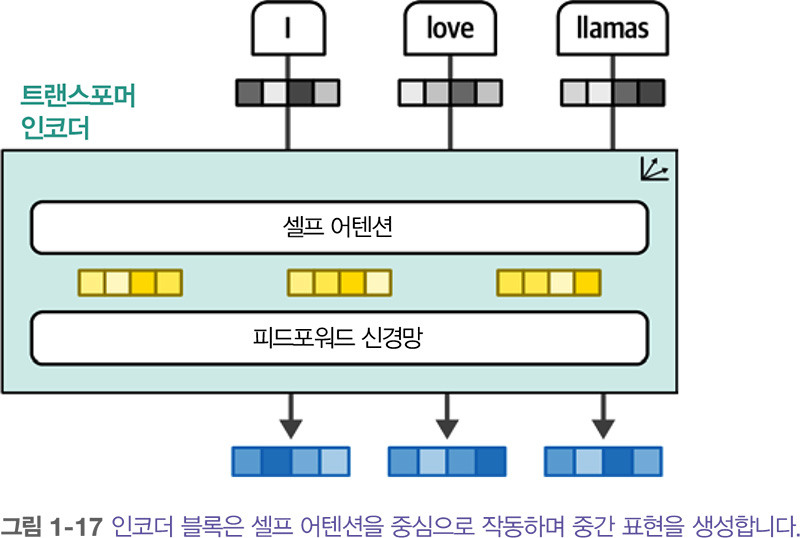
이전 어텐션 방법과 비교하면 셀프 어텐션은 한 시퀀스 안의 다른 위치에 주의를 기울입니다. 따라서 아래 그림처럼 입력 시퀀스를 더 쉽고 정확하게 표현할 수 있습니다. 한 번에 하나의 토큰을 처리하지 않고 전체 시퀀스를 한 번에 처리할 수 있습니다.

인코더와 달리 디코더는 (입력에서 관련된 부분을 찾기 위해) 인코더의 출력에 주의를 기울이는 별도의 층이 추가됩니다. 이 과정은 앞서 소개한 RNN의 어텐션 디코더와 비슷합니다.
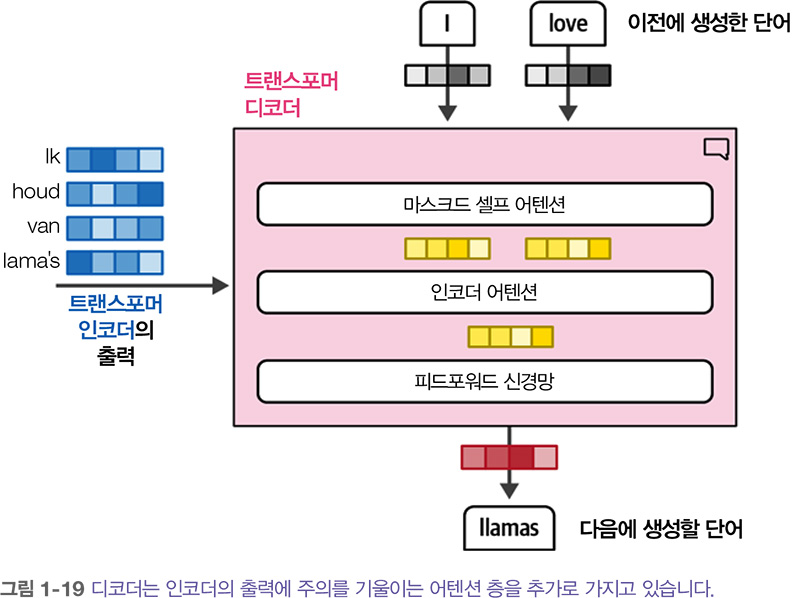
아래 그림에서 보듯이 디코더의 셀프 어텐션 층은 미래의 위치를 마스킹 masking 합니다. 따라서 출력을 생성할 때 정보 누출을 방지하기 위해 앞선 위치에만 주의를 기울일 수 있습니다.
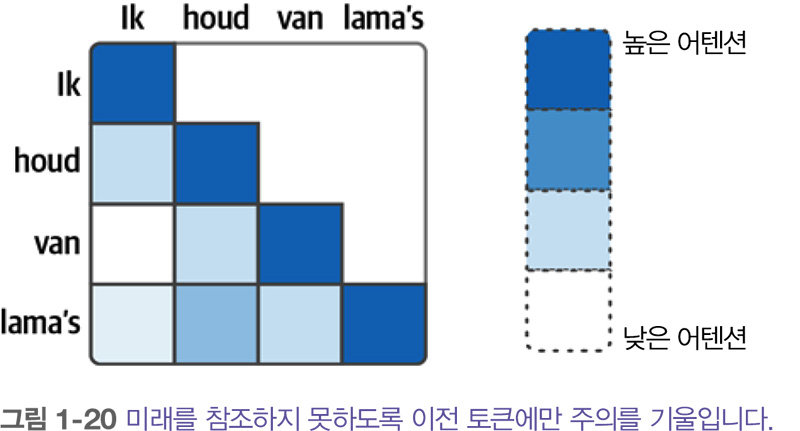
이런 구성 요소가 합쳐져서 트랜스포머 구조가 만들어집니다. 이 구조는 나중에 소개할 BERT와 GPT-1 같이 언어 AI 분야에 영향을 끼친 많은 모델의 기반을 이룹니다. 책 『핸즈온 LLM』에서 다루는 대부분 모델 또한 트랜스포머 기반 모델입니다.
6. 표현 모델: 인코더 기반 모델
원본 트랜스포머 모델은 인코더-디코더 구조라서 번역 작업에는 잘 맞지만 텍스트 분류와 같은 작업에는 쉽게 사용할 수 없습니다.
2018년에 BERT Bidirectional Encoder Representations from Transformers 라는 새로운 구조가 소개되었습니다. 이는 다양한 작업에 활용되며 차후 몇 년간 언어 AI의 기반이 되었습니다. BERT는 언어를 표현하는 데 초점을 맞춘 인코더 기반 구조입니다. 인코더 기반 구조란 인코더만 사용하고 디코더는 사용하지 않는다는 의미입니다.
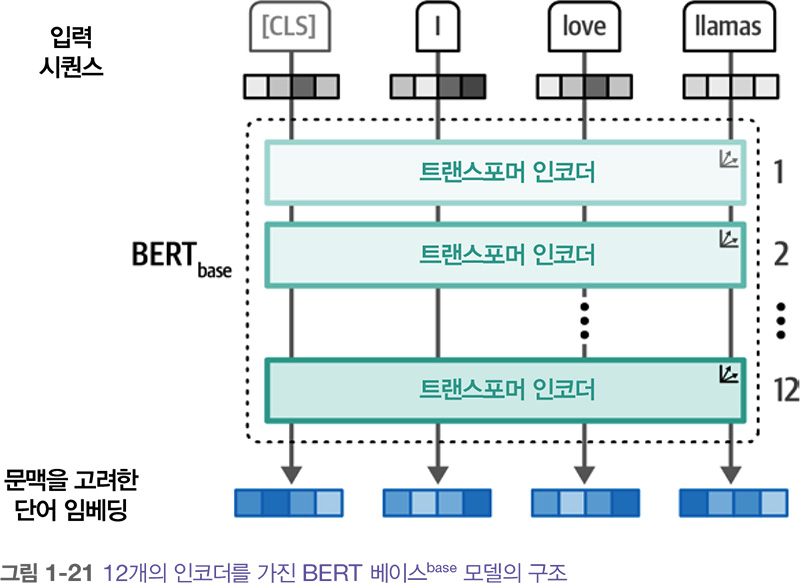
인코더 블록은 이전에 보았던 것과 같습니다. 셀프 어텐션 다음에 피드포워드 신경망이 나옵니 다. 입력에는 추가적으로 [CLS] 토큰 또는 분류 토큰이 포함됩니다. 이 토큰을 전체 입력에 대한 표현으로 사용합니다. 종종 분류와 같은 특정 작업에서 모델을 미세 튜닝 fine-tuning 하기 위해 [CLS] 토큰을 입력의 임베딩으로 사용합니다.
이런 인코더 스택 stack 을 훈련하는 것은 어려운 작업일 수 있습니다. BERT는 마스크드 언어 모델링 masked language modeling 이라는 기법을 적용했습니다. 이 방법은 모델이 예측할 입력의 일부분을 마스킹합니다. 이런 예측 작업은 어렵지만 BERT가 더 정확한 입력에 대한 (중간) 표현을 만들 수 있도록 돕습니다.
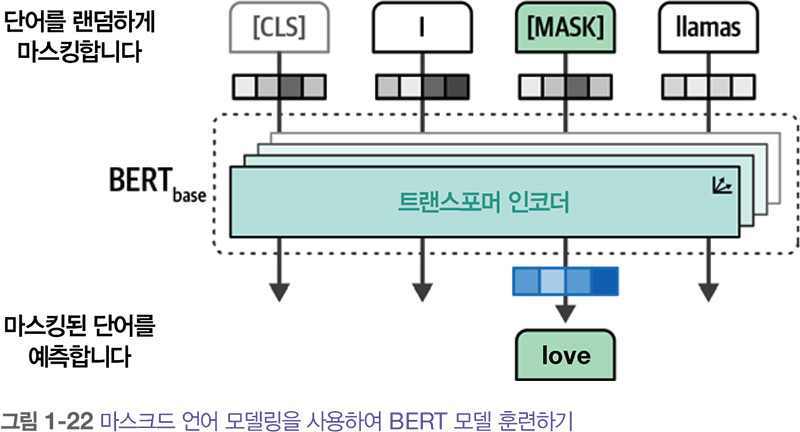
이런 구조와 훈련 방법 덕분에 BERT와 이와 유사한 구조가 언어의 문맥을 표현하는 데 놀라운 성능을 냅니다. BERT와 같은 모델은 일반적으로 전이 학습 transfer learning 에 사용됩니다. 먼저 언어 모델링을 위해 모델을 사전 훈련 pretraining 하고 그다음 구체적인 작업을 위해 미세 튜닝합니다.
예를 들어, 위키백과 전체로 BERT 모델을 훈련하여 텍스트의 의미와 맥락을 이해하는 방법을 학습합니다. 그다음 그림에서 보듯이 사전 훈련된 모델을 사용해 텍스트 분류와 같은 특정 작업을 위해 미세 튜닝할 수 있습니다.
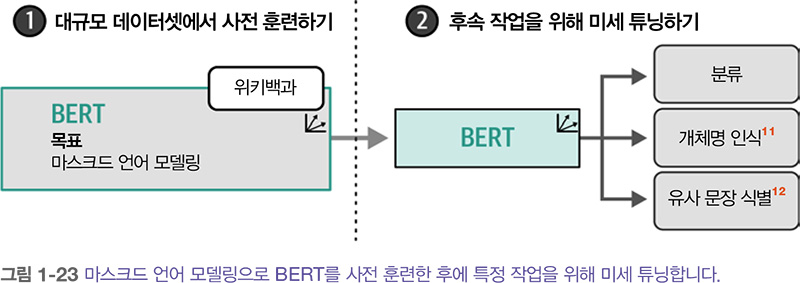
사전 훈련된 모델의 강점은 대부분의 학습이 이미 완료되어 있어, 이후 특정 작업에 맞춰 약간의 미세 조정만으로도 좋은 성능을 낼 수 있다는 점입니다. 이 과정은 비교적 적은 컴퓨팅 자원과 데이터로도 가능합니다. 예를 들어, BERT 같은 모델은 다양한 계층에서 임베딩을 생성하기 때문에, 굳이 미세 조정하지 않고도 특성 추출기로 활용할 수 있습니다.
이러한 인코더 기반 모델은 분류, 클러스터링, 시맨틱 검색 등 다양한 자연어 처리 작업에서 오랫동안 널리 사용되어 왔으며, 여전히 중요한 역할을 하고 있습니다.
7. 생성 모델: 디코더 기반 모델
BERT의 인코더 기반 구조와 비슷하게 2018년 생성 작업을 위한 디코더 기반 구조가 제안되었습니다. 생성 능력 때문에 이 구조를 GPT Generative Pre-trained Transformer 라고 불렀습니다(후속 버전과 구별하기 위해 이 모델을 GPT-1이라 합니다). 인코더를 쌓은 BERT와 비슷하게 디코더 블록을 쌓아 구성합니다.
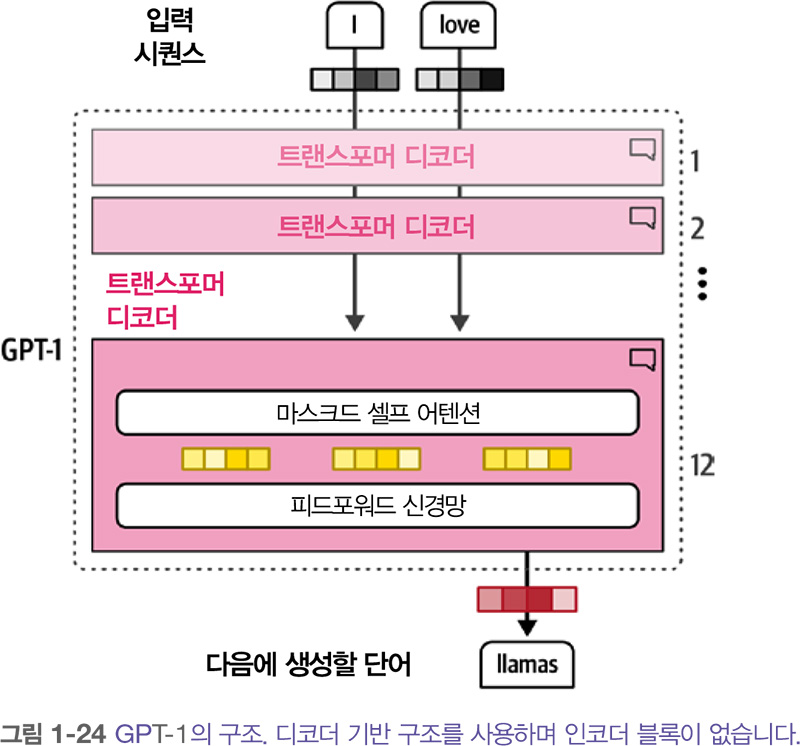
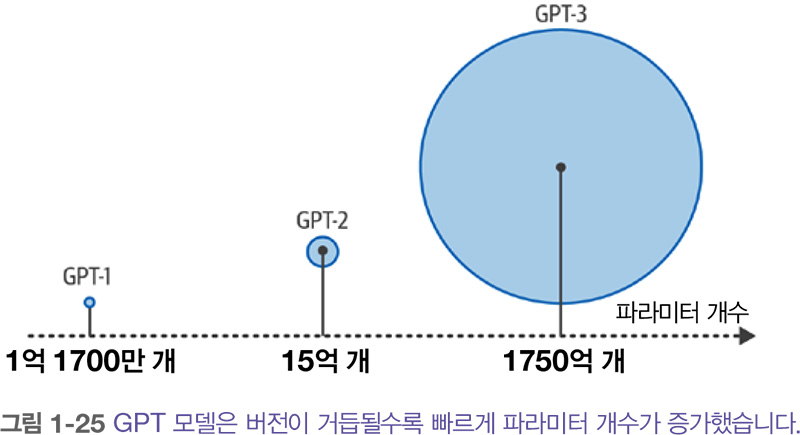
GPT-1은 7,000권의 책과 대규모 웹 페이지 데이터셋인 커먼 크롤 Common Crawl 로 구성된 말뭉치에서 훈련되었습니다. 이 모델은 1억 1700만 개 파라미터로 구성됩니다. 각 파라미터는 어떤 수치 값이며 이를 통해 모델의 언어 이해를 나타냅니다.
모든 것이 동일하다면 많은 파라미터가 언어 모델의 능력과 성능에 영향을 미칠 거라 기대합니다. 그래서 점점 더 큰 모델이 꾸준히 출시되었습니다. GPT-2는 15억 개의 파라미터를 가지고 15 GPT-3는 1750억 개의 파라미터를 가집니다.
이런 디코더 기반 생성 모델, 특히 대규모 모델을 대규모 언어 모델 large language models (LLM)이라고 부릅니다. 나중에 이 장에서 보겠지만 LLM은 (디코더 기반의) 생성 모델만이 아니라 (인 코더 기반의) 표현 모델도 지칭합니다.
시퀀스-투-시퀀스 sequence-to-sequence 모델로서 생성 LLM은 어떤 텍스트를 받아 이를 자동으로 완성합니다. 유용한 기능이지만 이 모델의 진정한 힘은 챗봇으로 훈련되었을 때 빛을 발했습니다. 텍스트를 완성하는 대신 질문에 대답하도록 훈련하면 어떨까요? 이런 모델을 미세 튜닝하여 지시를 따르는 인스트럭트 모델 instruct model 또는 채팅 모델 chat model 을 만들 수 있습니다.
이렇게 만든 모델은 사용자 쿼리(프롬프트)를 입력 받고, 이 프롬프트를 따르는 응답을 출력할 수 있습니다. 따라서 종종 생성 모델을 완성 모델이라고도 합니다.

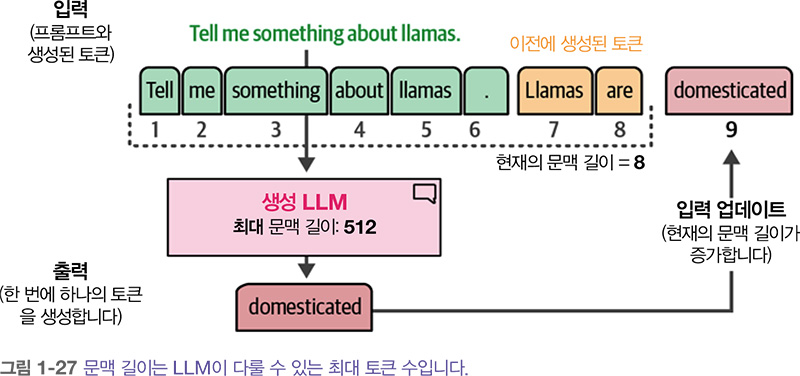
완성 모델에서 중요한 부분은 문맥 길이 또는 문맥 윈도입니다. 아래 그림에서처럼 문맥 길이는 모델이 처리할 수 있는 최대 토큰 수를 나타냅니다. 문맥 길이가 크면 LLM에 문서를 통채로 전달할 수 있습니다. 이런 모델은 자기회귀 성질을 가지고 있기 때문에 새로운 토큰이 생성됨에 따라 현재의 문맥 길이가 늘어납니다.
8. 생성 AI의 해
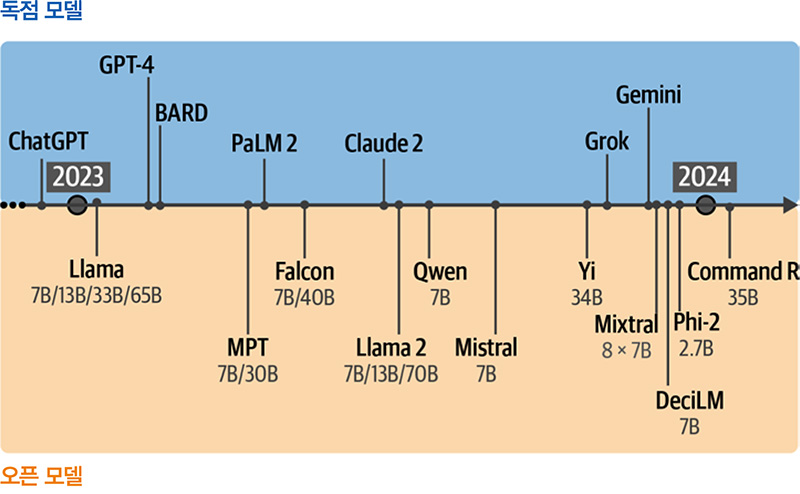
LLM은 인공지능 분야에 엄청난 영향을 미쳤으며 사람들은 2023년을 ‘생성 AI의 해’라고 부릅니다. ChatGPT (GPT-3.5 )가 출시되어 다양한 분야에 적용되었고 매일 언론에 등장했습니다. ChatGPT라고 하면 모델이 아니라 제품을 의미합니다. ChatGPT가 처음 출시되었을 때는 GPT-3.5 LLM을 사용했으며, GPT-4.1과 같이 더 성능이 뛰어난 후속 모델로 구동됩니다.
생성 AI의 해에 영향을 끼친 모델은 GPT-3.5뿐만이 아니었습니다. 오픈 소스 LLM과 독점적인 LLM이 놀라운 속도로 사용자들에게 공개되었습니다. 이런 오픈 소스 베이스 모델을 종종 파운데이션 모델 foundation model 이라고 하며 명령 수행과 같은 특정 작업을 위해 미세 튜닝할 수 있습니다.
인기가 많은 트랜스포머 구조 외에도 Mamba와 RWKV같은 새로운 아키텍처가 등장했습니다. 이런 새로운 구조는 트랜스포머에 필적하는 성능을 달성하는 것은 물론 큰 문맥 윈도 또는 빠른 추론과 같은 장점을 추가로 가지고 있습니다.
이런 발전은 이 분야가 진화하고 있다는 것을 보여주며 2023년을 AI에 있어서 정말 바쁜 한해로 만들었습니다. 언어 AI 안팎의 많은 발전을 따라잡는 데 정말 많은 노력이 필요했습니다.
따라서 최신 LLM만을 보는 것보다 임베딩 모델, 인코더 기반 모델, 심지어 BoW 같은 모델이 LLM의 성능을 높이는 데 어떻게 활용되는지 살펴보는 것이 좋습니다.
위 콘텐츠는 『핸즈온 LLM』에서 내용을 발췌하여 작성하였습니다.

![]() 0
0




댓글