구글 엔지니어가 알려주는 안전하고 신뢰성 높은 시스템의 설계부터 테스팅, 복구, 위기 관리까지
시스템이 근본적으로 안전하지 않다면 신뢰할 수 있을까? 보안과 신뢰성은 제품 품질, 성능 및 가용성에 중요한 역할을 하기 때문에 확장되는 시스템의 설계와 운영에 매우 중요하다. 이 책은 안전하고 확장이 가능하며 신뢰할 수 있는 시스템을 설계하는 데 도움을 주는 구글의 구체적인 모범 사례를 자세히 공유한다. 또한, 보안과 안정성에 특화된 실무자의 시스템 설계, 구현 및 유지 보수에 대한 통찰력도 함께 제공한다. 구글러들의 경험으로 얻은 통찰과 SRE 지침을 익혀, 안전하고 신뢰성이 높은 시스템을 구축하길 바란다.
저자소개
저자
헤더 애드킨스
18년간 구글에 몸담고 있는 베테랑이자 구글 보안 팀의 초기 멤버다. 정보 보안 분야의 시니어 디렉터를 맡고 있는 헤더는 구글의 네트워크, 시스템, 애플리케이션의 안전성 및 보안을 유지하는 책임을 담당하는 글로벌 팀을 구축했다. 시스템과 네트워크 관리에 현실적인 보안을 중점적으로 폭넓은 경험을 갖추고 있으며 세계에서 가장 거대한 인프라스트럭처를 구축하고 안전하게 유지하는 업무를 담당했다. 이제는 구글의 컴퓨팅 인프라스트럭처의 방어 전략에 대부분의 시간을 할애하고 있으며 업계와 더불어 가장 어려운 보안 과제에 도전하고 있다.
저자
벳시 바이어
구글 뉴욕 오피스에 근무하며 사이트 신뢰성 엔지니어링에 특화된 테크니컬 라이터(technical writer) 이다. 벳시는 『사이트 신뢰성 엔지니어링』(제이펍, 2018 ) 및 『The Site Reliability Workbook』(O’Reilly, 2018)의 공동 저자이기도 하다. 현재 업무를 담당하기 전에는 국제 외교와 영문학을 전공했으며 스탠퍼드(Stanford)와 툴레인(Tulane) 대학교에서 학위를 마쳤다.
저자
폴 블랭킨십
구글의 보안 및 개인 정보 엔지니어링 그룹에서 테크니컬 라이팅 팀을 관리하고 있으며 구글의 내부 보안 및 개인정보 보호 정책의 개발에 참여했다. 테크니컬 라이터로서의 업무 외에도 샌프란시스코 베이 지역에서 뮤지션으로 활발히 활동 중이다.
저자
피오트르 레반도프스키
시니어 스태프 사이트 신뢰성 엔지니어(Senior Staff Site Reliability Engineer)이며 지난 9년간 구글 인프라스트럭처의 보안을 개선하는데 힘썼다. 피오트르는 보안 분야의 실질적인 기술 리드로서 SRE와 보안 조직이 서로 조화롭게 협업하도록 만드는 책임을 담당하고 있다. 그 전에는 구글의 핵심 보안 인프라스트럭처의 안정성을 담당하는 팀을 이끌었다. 구글에 합류하기 전에는 스타트업을 창업했고 CERT Polska에서 근무했으며 폴란드의 바르샤바 기술대학교에서 컴퓨터 과학을 전공했다.
저자
애나 오프레아
보안, SRE 및 구글의 기술 인프라스트럭처를 위한 계획과 전략의 수립을 담당하고 있다. 소프트웨어 개발자, 기술 컨설턴트 및 네트워크 관리자 등을 경험하면서 자연스럽게 현재 업무를 맡게 되었다. 독일, 프랑스, 루마니아에서 공부와 경력을 쌓은 덕분에 어떤 난관이 생겨도 여러 가지 다른 문화적 접근 방식으로 해결한다.
저자
애덤 스터블필드
구글의 저명한(distinguished) 엔지니어이자 지역 보안 기술 리더이다. 지난 8년간 구글의 핵심 보안 인프라스트럭처의 상당 부분을 구축하는 데 힘을 보탰다. 애덤은 존스 홉킨스 대학교에서 컴퓨터 과학 분야 박사 학위를 취득했다.
역자
장현희
캐나다 켈로나 소재의 QHR Technologies에서 시니어 소프트웨어 엔지니어로 근무 중이다. 21년째 개발자의 길을 걷고 있으며 총 25종의 개발 관련서를 집필하거나 번역했다. 국내 개발자들에게 조금이라도 도움이 되는 번역서를 만들기 위해 최선을 다하고 있으며, 책이라는 매체를 통해 멀리서나마 국내 개발자들과의 소통을 지속하고자 노력하고 있다. 최근에는 『사이트 신뢰성 엔지니어링』(제이펍, 2018), 『클라우드 네이티브 자바』(책만, 2018), 『러스트 프로그래밍 공식 가이드(제이펍, 2019), 『엔터프라이즈 데이터 플랫폼 구축』(책만, 2020) 등을 번역했다.
목차
[Part I 들어가며]
CHAPTER 1 보안과 신뢰성 사이의 교집합
1.1 비밀번호와 전기드릴
1.2 신뢰성과 보안의 비교: 설계 고려사항
1.3 기밀성, 무결성, 가용성
1.4 신뢰성과 보안: 공통점
1.5 마치며
CHAPTER 2 적을 알자
2.1 공격자의 동기
2.2 공격자 프로필
2.3 공격의 방식
2.4 위험 평가 시 고려사항
2.5 마치며
[Part II 시스템 설계]
CHAPTER 3 사례 연구: 안전한 프록시
3.1 프로덕션 환경의 안전한 프록시
3.2 구글 도구 프록시
3.3 마치며
CHAPTER 4 설계 절충
4.1 설계 목표와 요구사항
4.2 요구사항의 균형잡기
4.3 갈등의 관리와 목표의 조정
4.4 초기의 속도와 지속적인 속도의 비교
4.5 마치며
CHAPTER 5 최소 권한 설계
5.1 개념과 용어
5.2 위험에 따라 접근 분류하기
5.3 권장 사례
5.4 실제 사례: 설정 분산
5.5 인증과 승인을 위한 정책 프레임워크
5.6 더 알아보기: 고급 제어
5.7 절충과 긴장
5.8 마치며
CHAPTER 6 이해 가능성을 위한 설계
6.1 이해 가능성이 중요한 이유
6.2 이해가 가능한 시스템의 설계
6.3 시스템 아키텍처
6.4 시스템 설계
6.5 마치며
CHAPTER 7 범위의 변화를 위한 설계
7.1 보안과 관련된 변화의 종류
7.2 변화의 설계
7.3 보다 쉬운 변화를 위한 아키텍처 결정사항
7.4 변화의 종류: 서로 다른 속도, 서로 다른 일정
7.5 분란: 계획이 변경될 때
7.6 예시: 범위의 증가 - 하트블리드
7.7 마치며
CHAPTER 8 회복성을 위한 설계
8.1 회복성을 위한 설계 원리
8.2 심층방어
8.3 성능 저하의 제어
8.4 영향 반경의 제어
8.5 더 알아보기: 장애 도메인과 이중화
8.6 더 알아보기: 지속적 검증
8.7 실용적인 조언: 어떻게 시작할 것인가
8.8 마치며
CHAPTER 9 복구를 위한 설계
9.1 어떤 상태로부터 복구하는가?
9.2 복구를 위한 설계 원리
9.3 긴급 접근
9.4 예상치 못한 장점
9.5 마치며
CHAPTER 10 서비스 거부 공격의 완화
10.1 공격과 방어를 위한 전략
10.2 방어를 위한 설계
10.3 공격의 완화
10.4 자체 유발 공격에 대응하기
10.5 마치며
[Part 3 시스템의 구현]
CHAPTER 11 사례 연구: 공개적으로 신뢰할 수 있는 CA의 설계와 구현 그리고 유지 보수
11.1 공개적으로 신뢰할 수 있는 인증 기관에 대한 배경
11.2 공개적으로 신뢰할 수 있는 CA가 필요했던 이유
11.3 자체 구축과 솔루션 구입 방식의 비교
11.4 설계, 구현 및 운영에 대한 고려
11.5 마치며
CHAPTER 12 코드 작성
12.1 보안과 신뢰성을 강제하는 프레임워크
12.2 보편적인 보안 취약점
12.3 프레임워크의 평가와 구현
12.4 간결함은 안전하며 신뢰할 수 있는 코드로 이어진다
12.5 기본적인 보안과 신뢰성
12.6 마치며
CHAPTER 13 코트 테스트
13.1 단위 테스트
13.2 통합 테스트
13.3 더 알아보기: 동적 프로그램 분석
13.4 더 알아보기: 퍼즈 테스트
13.5 더 알아보기: 정적 프로그램 분석
13.6 마치며
CHAPTER 14 코드 배포
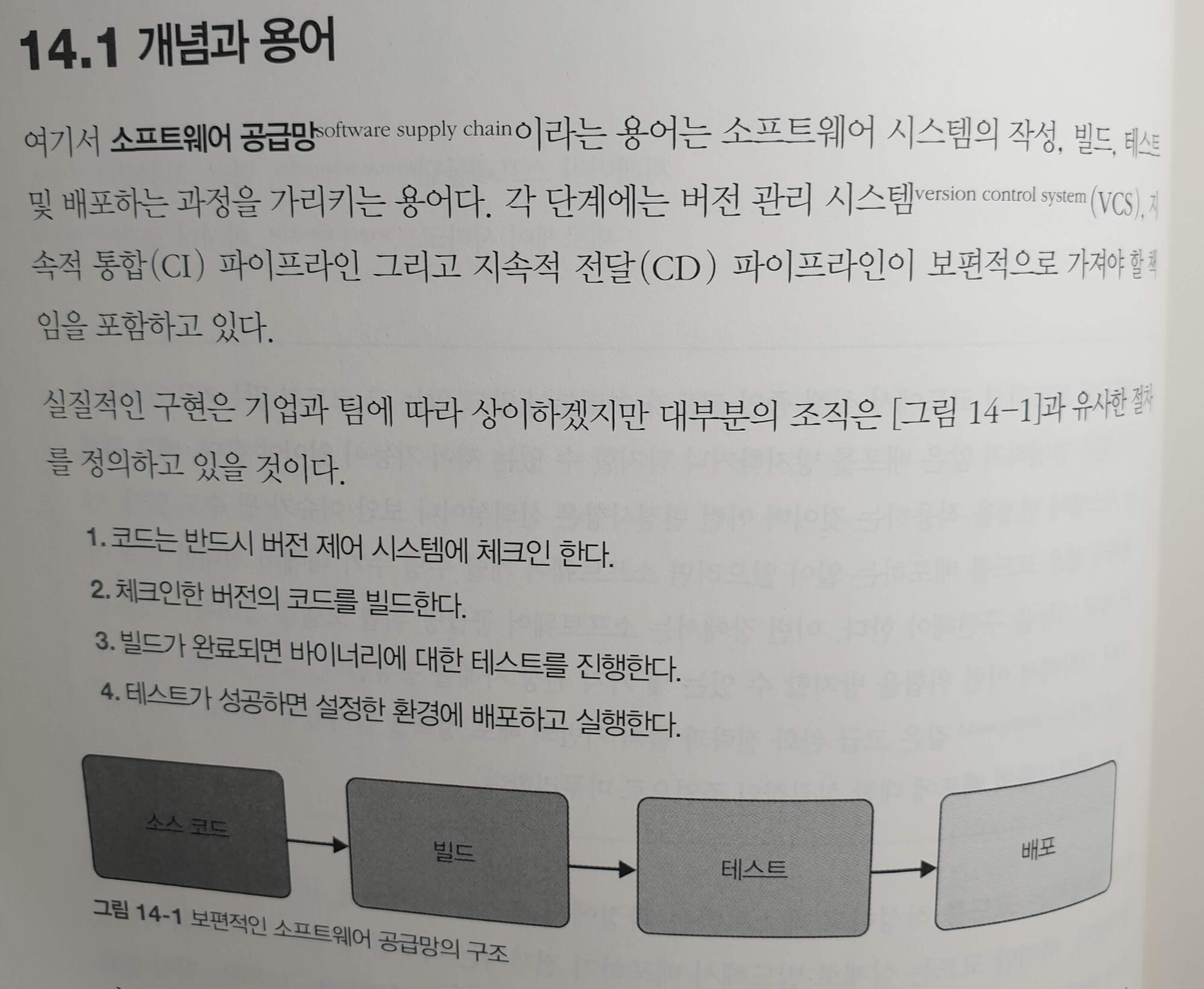
14.1 개념과 용어
14.2 위협 모델
14.3 권장 사례
14.4 위협 모델에 적용하기
14.5 더 알아보기: 고급 완화 전략
14.6 현실적인 조언
14.7 다시 한번 위협 모델에 적용하기
14.8 마치며
CHAPTER 15 시스템 조사
15.1 디버깅부터 조사까지
15.2 적절하고 유용한 로그의 수집
15.3 견고하고 안전한 디버깅 접근
15.4 마치며
[Part 4 시스템 유지 보수]
CHAPTER 16 재해 계획
16.1 ‘재해’의 정의
16.2 동적 재해 대응 전략
16.3 재해 위험 분석
16.4 사고 대응 팀의 셋업
16.5 장애가 발생하기 전에 시스템과 사람에 대한 준비사항
16.6 더 알아보기: 시스템과 대응 계획의 테스트
16.7 구글의 사례
16.8 마치며
CHAPTER 17 위기 관리
17.1 위기일까 아닐까?
17.2 사고 조치 지휘하기
17.3 사고 대응의 지속적 제어
17.4 의사소통
17.5 종합
17.6 마치며
CHAPTER 18 복구와 사후처리
18.1 복구 전략
18.2 복구 타임라인
18.3 복구 계획
18.4 복구 시작
18.5 복구 이후
18.6 예시
18.7 마치며
[Part 5 조직과 문화]
CHAPTER 19 사례 연구: 크롬 보안 팀
19.1 배경과 팀의 발전
19.2 보안은 팀의 책임이다
19.3 사용자가 안전하게 웹을 탐색하도록 돕는다
19.4 속도가 중요하다
19.5 심층방어를 위한 설계
19.6 투명성의 유지와 커뮤니티와의 교류
19.7 마치며
CHAPTER 20 역할과 책임의 이해
20.1 보안과 신뢰성에 대한 책임을 지는 사람은 누구인가?
20.2 보안을 조직에 통합하기
20.3 마치며
CHAPTER 21 보안과 신뢰성 문화 구축
21.1 건전한 보안과 신뢰성 문화의 정의
21.2 좋은 사례는 문화를 바꾼다
21.3 경영진 설득하기
21.4 마치며
출판사리뷰
구글 SRE 엔지니어들이 알려주는 시스템 설계와 구축 노하우
구글이 지금까지 수많은 서비스를 개발하고 운영해 오면서 터득한 보안과 신뢰성 관련 경험과 지식을 모두 이 책에 담겨있다. 보안과 신뢰성은 서로 상충하는 부분도 있지만 궁극적으로는 안전하며 안심하고 사용할 수 있는 소프트웨어와 서비스를 제공하기 위해서는 반드시 고려해야 할 필수적인 요소다. 이 책의 저자들은 왜 보안과 신뢰성이 중요한지, 보안과 신뢰성에 어떤 형태로 구멍이 생기고 이를 어떻게 예방하거나 대처할지 실용적이면서도 현실적인 조언을 제공한다. 이 책에 담긴 저자 6명의 조언을 참고해 안전하고 신뢰성 있는 시스템을 설계하여 모든 산업에서 인정받는 엔지니어로 거듭나길 바란다.
주요 내용
설계 전략
코딩, 테스트 및 디버깅을 위한 권장 사항
사고 대비, 대응 및 복구하기 위한 전략
조직 전체가 서로 효과적으로 협업할 수 있도록 지원하는 문화적 모범 사례
추천사
인터넷 서비스를 운영하거나 보안을 담당하고 있다면 구글을 비롯한 다른 회사들이 그 일을 쉽게 하고 있다고 생각해서는 안 된다. 이 책의 저자들과 오랜 시간 일하면서, 그들이 사용자 데이터를 보호하기 위해 극단적인 조치를 하는 것을 볼 때마다 매번 놀라웠다. 유사한 분야에 종사하거나, 서비스와 데이터를 보호하기 위해, 현대의 대규모 서비스에서는 어떤 작업을 하는지 궁금하다면 이 책을 읽어보길 바란다. 이 책은 실용적인 조언과 절충에 대한 가장 솔직한 논의를 담은 책일 것이다.
요즘 IT 업계에서 유행하는 "SRE(Site Reliability Engineering) : 사이트 신뢰성 엔지니어링" 에 대한 개념 정리 및 시스템 적용 사례를 찾는 다면 이 책을 보라.
[책 추천 이유]
구글에서 신뢰성을 보장하기 위한 SRE 사례를 바탕으로 IT 전략 수립 및 프로세스 및 계획을 세워 큰 그림을 그릴 수 있는 방향성을 제시해준다.
[내가 찾고자 했던 질문들]
1. SRE(Site Reliability Engineering) : 사이트 신뢰성 엔지니어링 의 개념은 어떻게 되는가?
- IT운영을 할때 스마트한 방식이 있을까? 이부분을 공학적으로 녹인 부분은 SRE 라고 할수 있겠다. 이 책에서는 운영시 발생할 수 있는 "보안" 적인 부분을 많이 강조하고 있으며, 운영시 발생할 수 있는 여러 문제점들을 해결할 수 있는 방법을 제시하고 있다.
2. SRE 어떻게 스마트하게 할것인가?
- 시스템 설계 / 구현 / 유지보수 / 위기관리 / 조직문화 크게 5가지로 나눠서 SRE 적용해볼 수 있도록 책은 구성하고 있다. Devops 형태의 시스템을 운영하는 조직에게는 SRE 적용하기 딱 좋은 환경이라고 생각한다.기본적인 시스템의 life cylce 전반에 SRE 녹여서 의도치 않은 보안 문제나, 버그들을 사전에 잡는 방법 등을 직접 적용해볼 수 있는 환경이 이미 되어 있기 때문에 SRE 기본적인 개념과 지식이 꼭 필요하겠다.
나는 전부터 체계적이고 안정적인 시스템을 구축하는 것에 관심이 많았다. 하지만 서비스 개발 자체에는 관심이 없어서 직접 개발을 하는 것보다는 운영하면서 부딪히는 이슈들을 해결하는 것을 좋아한다. 예를 들어 학생 시절에는 마인크래프트 서버를 운영하면서 어떻게 사용자 수가 많아지면서 어떻게 서버를 확장할 수 있을지 고민도 해보고, 성능 저하가 발생했을 때 원인을 찾고 해결하곤 했다.
그 때 나는 문제를 주먹구구식으로 해결했지만, 이번에 리뷰할 [SRE를 위한 시스템 설계와 구축]은 서비스의 설계 단계부터, 구현, 유지보수 등 각 단계에서 어떻게 보안(Security)과 신뢰성(Reliability) 문제를 어떻게 예방하고 대처할지 차근차근 알려준다. 메모장과 같은 단순한 프로그램부터 복잡한 웹 서비스까지 무엇을 개발하더라도 안정성과 보안은 빠뜨릴 수 없는, 사용자와의 신뢰의 문제이기 때문에 모든 개발 조직에서 고려할 문제라고 생각한다.
책의 내용이 생각보다 방대한데, 그 중 인상 깊었던 몇 가지 내용을 정리해본다. 책의 내용에 깊이가 있어서 여러 번 읽어보는 것을 추천한다.
설계
이해 가능성을 위한 설계
시스템 원활하게 관리하고, 장애에 대처하려면 시스템을 최대한 단순하게 설계해야한다. 물론 성능을 위해서 복잡해지는 경우도 종종 있지만, 복잡성에는 이유가 있어야 하며 과해서는 안된다. 그렇지 않으면 문제가 발생해도 원인을 분석하기가 어려워진다. 이해하기 쉬운 설계를 위해서는 시스템을 작고 이해하기 컴포넌트로 분리해야한다.
범위의 변화를 위한 설계
(거의) 모든 시스템은 한 번 개발이 된 후에 멈추는 게 아니라 항상 변화한다. 새로운 기능을 추가하거나 수도 있고, 보안 취약점을 패치할 수도 있다. 하지만 단순히 코드를 바꾸고 배포하는게 아니라 코드 리뷰와 테스트로 검증하고, 단기적 변화냐, 장기적 변화냐에 따라서도 다른 전략을 취해야 한다.
구현
코드 작성
코드는 항상 완벽하지 않고, 취약점도 생기기 마련이다. 아무리 열심히 리뷰하고 테스트를 해도 버그가 전혀 없을 수는 없다. 그리고 모두가 해박한 보안 전문가가 되는 것은 비현실적이기 때문에, 공통적인 라이브러리를 사용해서 보안 문제를 관리할 수 있도록 하는것이 필요하다. 그리고 데이터의 타입이 단순 문자열이 아니라 잘 정의된 타입을 사용하면 더 수월하게 보안 문제를 예방할 수 있다.
코드 테스트
사람의 코드 리뷰는 완벽하지 않기 때문에 코드는 항상 테스트해야한다. 구글은 각각의 컴포넌트가 의도적으로 동작하는지 테스트하는 단위테스트와, 시스템 전체가 의도대로 동작하는지 통합 테스트도 수행한다.
그리고 정적인 테스트 뿐만 아니라 Undefined Behavior, Race Condition, Memory Leak, Memory Corruption 등 어플리케이션에서 발생할 수 있는 다양한 이상 동작들을 탐지할 수 있는 도구도 적극적으로 사용한다.
개발 관련 글, 채용 공고에서 'SRE'라는 단어가 자주 보인다. 찾아보니 RedHat 홈페이지에 SRE에 대해 정리된 글이 있었다.
사이트 신뢰성 엔지니어링(SRE)은 IT 운영에 대한 소프트웨어 엔지니어링 접근 방식입니다. SRE 팀은 소프트웨어를 툴로 활용하여 시스템을 관리하고, 문제를 해결하고, 운영 태스크를 자동화합니다.
시스템 개발 초기에는 개발 분량도 적고, 범위도 적어서 소수의 인원으로 관리 및 유지보수가 가능하다. 하지만 서비스가 성장하고 그에 따라 시스템 확장, 개발 및 유지보수 인력 증가 등 더이상 소수의 인원이 관리하기가 힘든 상황을 마주하게 된다. 협업을 위한 관리 시스템을 도입하거나 만들지만 이것 역시 또다른 관리 대상이 되고만다. 이런 어려움 때문에 시스템 관리를 전담하는 SRE라는 직군이 생겨난 것이다.
그렇다면 SRE는 개발된 시스템을 관리만하면 끝일까? 그렇지 않다. 관리하면서도 시스템은 운영되고 있고, 외부로부터 공격, 재난상황 등 예상치 못한 상황에 대응해야한다. 상황을 하나씩 해결하며 경험을 쌓는다면 좋겠지만 장애가 자주 발생하는 서비스라면 사용자들의 재방문은 줄어들 것이 뻔하다.
초대형 기업인 구글에서는 이 어려움을 어떻게 극복했을까? 그에 대한 답이 이번에 리뷰하는 《SRE를 위한 시스템 설계와 구축》에 담겨있다. 저자들은 구글에서 근무하며 겪은 장애 및 극복 경험들을 소개하는데 읽으면서도 선배의 업무 노트를 보는 느낌이라 좋았다.
Part 1.부터 Part 5.까지의 구성 중 Part 4를 지나는 시점에서 든 생각은 《SRE를 위한 시스템 설계와 구축》은 일반적인 다른 기술서적들처럼 특정 기술을 소개하고, 사용법을 알려주는 책이 아니다. 예전에 읽은 《의사가 말하는 의사》, 《도와주세요! 팀장이 됐어요》 와 같은 정보와 경험담을 고르게 담고 있는 에세이에 가깝다. 저자도 쿡북 형식의 책이 아니며 배웠던 점을 공유하는 것임을 책의 구성에서 말하고 있다.
책은 크게 5개 부분으로 구성되어 있다.
Part 1. 들어가며
문제 상황을 대비해서 예방 및 대응 시스템을 만들었지만 관리 문제로 정작 필요할 때 대응하지 못했던 사례를 소개한다. 사례를 통해 왜 안전하고 신뢰할 수 있는 시스템이 필요한지, 위협의 종류와 그 대응 방법에 대해 정리되어 있다.
Part 2. 시스템 설계
시스템은 상황에 맞게 잘 설계를 해야 한다. 보안과 신뢰성이 보장되는 시스템을 설계하기 위해 노력했던 이야기와 방법들을 소개한다.
Part 3. 시스템의 구현
Part 1 시스템이 왜 필요한지 알아보고, Part 2에서 시스템 설계를 설명했다. 앞 내용을 바탕으로 구현할 때 주의해야 할 부분은 무엇인지, 무엇을 추가로 고려해야하는지를 소개한다.
Part 4. 시스템 유지 보수
아무리 설계를 잘 하고, 구현을 완벽하게 했더라도 예기치 못한 상황은 발생한다. 우리가 할 수 있는 것은 예상되는 추가 예외 상황은 무엇인지 분석하고 실제로 상황이 발생한다면 어떻게 대응할지 계획을 세우는 것이다. Part 4에서는 재해시 대응 전략 및 복구, 후처리에 대해 소개한다.
Part 5. 조직과 문화
Part 1부터 4까지는 기술적인 이야기가 많았다면 'Part 5. 조직과 문화'에서는 앞의 내용들을 팀에 적용했던 경험에 대해 들려준다. 그리고 팀에 적용한 것에 그치지 않고 앞으로 또 어떤 것들을 고민해야할지 같이 생각해본다.
앞에서 '일반적인 다른 기술서적들처럼 특정 기술을 소개하고, 사용법을 알려주는 책이 아니다.'라고 말한 이유는 아래 사진을 보면 이해할 수 있다. 실제 업무를 진행하며 발생했던 문제들을 해결하기위해 했던 것들을 잘 정리해둔 메모노트와 같다. 'A라는 상황에서 발생한 문제를 B를 적용했고, 그 결과 해결했다'는 일련의 과정이 상세하게 기록되어 있다.
그리고 '한 줄 요약'에서 'SRE 팀 선배의 업무 노트를 보는 듯한 노하우가 담긴 책'이라고 말한 이유가 있다.
책 전체가 에세이처럼 기술 및 사례와 경험담을 이야기하고 있지만 특히 네모로 구분된 부분은 더 좋았다. 문제 상황에 막혀 해결못하고 있을 때 선배가 해결책 한마디 툭 던져주고 가는 느낌이었기 때문이다.
아직 Part 5까지 읽지 못했지만 기대된다. 저자들이 팀 내부에서 그리고 외부에서 기술을 적용하고 문제상황들을 어떻게 극복했는지 궁금하기 때문이다. SRE가 아니더라도 시스템 개발, 유지보수와 관련되거나 접점이 있는 사람이라면 《SRE를 위한 시스템 설계와 구축》를 꼭 읽어보면 좋겠다.
SRE(Site Reliability Enginners, 사이트 신뢰성 엔지니어)라는 말은 매우 매력적인 단어 인 듯 하다. 신뢰할 수 있는 사이트를 만들기 위한 시스템 설계와 구축이라니, 또한 구글에 있는 사람들이 만든 책이라니.
시작부터 매우 매력적인 책인 것은 틀림이 없었다.
책에 저자도 여러명이고, 내용 또한 매우 방대한 책(600쪽이 넘는다.)이다.그런 만큼 여러가지 면에서 많은 내용들이 빼곡히 담겨 있는 책이다.
IT업계에 들어온지 얼마되지 않는 사람들보다는 시스템 구축 및 운영에 대한 경험이 있고, 시스템에 대한 고민을 많이 하고 있는 분들이 보면 매우 좋은 책일 것이다.
시스템 설계와 구축단계에서 고민할 내용들이 매우 많이 있으며, 당연한 이야기 이겠지만 운영 중인 시스템에 대해서는 변화하기 란 매우 어려울 것이다.
현재 회사에서도 구축된 시스템에 대해서 좀 더 안전하고 효율적으로 변화를 하고 싶지만 그에 대한영향도 파악이 어려운 관계로 거의 하지 못하고 있는 실정이다. 그런 측면에서 보면 코드, 테스트, 배포 들에 대한 내용은 도움이 많이 될 뜻 하다. 또한 현재 운영하고 있는 시스템도 장애가 종종 발생하고 있는데, 그에 따른 프로세스가 정립이 안되서 고생을 하는 중이다. 시스템 유지 보수 장을 보면서 많은 깨닭음과 고민이 생겼다. 현재에 적용하기에는 시간이 걸리겠지만, 그래도 앞으로의 발전을 위해서는 꼭 필요한 요소라고 하겠다.
이처럼 시스템을 구축하거나, 운영하는 데 부족한 부분이 있다면 이 책을 통해서 많은 깨닮음을 얻어가면 좋을 뜻 하다.
8월 리뷰를 진행하도록 하겠습니다.이번 리뷰를 진행할 책은 <SRE를 위한 시스템 설계와 구축> 입니다.
구글이 공개하는 SRE 모범 사례와 설계, 구현, 운영 노하우가 담겨있는 책입니다.
SRE 라는 용어조차 생소한 단어이네요.
사실 저도 이번 리뷰를 하면서 처음으로 접해보는 단어입니다.
사이트 신뢰성 엔지니어링(SRE)은 IT 운영에 대한 소프트웨어 엔지니어링 접근 방식입니다. SRE 팀은 소프트웨어를 툴로 활용하여 시스템을 관리하고, 문제를 해결하고, 운영 태스크를 자동화합니다.
SRE 팀은 기존에 운영 팀이 수동으로 하는 경우가 많았던 태스크를 받아 엔지니어 또는 운영 팀에 넘기고, 엔지니어 또는 운영 팀은 소프트웨어 및 자동화를 사용해 문제를 해결하고 프로덕션 시스템을 관리합니다.
SRE는 확장 가능하고 신뢰성이 높은 소프트웨어 시스템을 생성할 때 유용한 방법입니다. 코드를 통해 대규모 시스템을 관리할 수 있으므로 수천 대에서 수십만 대에 이르는 머신을 관리하는 시스템 관리자에게 더 큰 확장성과 지속가능성을 제공합니다.
사이트 신뢰성 엔지니어링은 Google 엔지니어링 팀의 Ben Treynor Sloss가 창안한 개념입니다.
쉽게 풀어보자면 '구글에서 적용하고 있는 시스템을 효과적으로 설계하고 구축하여 운영, 유지보수하는 방법' 정도로 정리할 수 있다.
책은 매우 두껍고, 딱딱하게 작성되어 있어요. 페이지 수는 무려 624페이지에 어려운 용어가 굉장히 많이 나옵니다. IT분야 초급자에게는 추천하지 않겠습니다.
하지만, IT 종사자이며, 어느정도 개발과 매니징을 하신 분이라면 반드시 읽어보실것을 추천드립니다.
이 책에서는 구글의 전문가들에 의해 발행이 되었으며, 실제 경험에 대해서 아주 잘 작성되어 있습니다. 실제로 프로젝트가 시작되면 여러분야에서 많은 부담을 가지게 됩니다. 특히 시스템을 설계하고 개발해야하는 개발부서에서는 시스템의 정상화를 위한 아주 많은 노력을 하게됩니다. 특히, 설계단계부터 많은 논의와 고민을 통해 탄탄한 시스템이 시작될 수 있습니다.
많은 사람들이 흔히들 잘못 알고 있는 부분들이 많이 있습니다. 모바일앱 개발을 하여 출시하면 모든 앱들이 카카오톡이나 토스같은 앱이 될것이라는 생각입니다. 하지만, 이러한 모바일앱들은 매우 오랜기간동안 안정화된 앱이거나, 아주 오랜 경험을 가진 개발자들이 아주 신중한 설계와 개발을 통해 완성도가 높은 앱일 확률이 높습니다.
실제로 스타트업이나, 중견기업에서 출시하는 대부분의 모바일앱들은 사용하는데 불편함이 느껴질 정도로 오류가 많이 있습니다. 하지만, 출시 후 오류들을 줄여가며 안정화를 통해서 비로서 사용할만한 모바일앱이 되어 갑니다.
이처럼 시스템은 처음부터 완벽할 수 없고, 많은 사람들에 의해 완성도가 높아져가는 것입니다. <Building Secure & Reliable Systems, SRE를 위한 시스템 설계와 구축>은 시스템 설계와 구축, 운영, 유지보수 전단계에 대한 실제 노하우를 통해 조금더 완성도 있는 시스템을 만드는데 도움을 줄 수 있습니다.
만약 시스템 설계와 구축, 보안성과 신뢰성에 대해 어렵더라도 도전하고 싶은 분들은 읽어보면 아주 좋을 책입니다.
어려운 책이지만, 분명히 얻어가는 것이 있는 책입니다. 좀더 높은 수준으로 성장하고 싶은 분들께 추천하고 싶습니다. 만약 IT 초보자이거나 초급 개발자라면 조금더 성장한 후에 보기를 바랍니다.
SRE(Secure & Reliable Systems)은 IT 운영에 대한 소프트웨어 엔지니어링 접근 방식이다.
SRE팀은 소프트웨어 툴을 활용하여 시스템을 관리하고, 문제를 해결하고, 운영 태스크를 자동화한다.
기존에 운영 팀이 수동으로 하는 경우가 많았던 태스크를 받아 엔지니어 또는 운영 팀에 넘기고, 엔지니어 또는 운영 팀은 소프트웨어 및 자동화를 사용해 문제를 해결하고 프로덕션 시스템을 관리한다.
간단히 SRE에 대해서 알아보았다.
이 책은 구글이라는 거대 IT 기업이 지금까지 수많은 서비스를 개발하고 운영해 오면서 터득한 보안과 신뢰성 관련 경험과 지식을 총망라한 책이다. 보안과 신뢰성은 서로 상충하는 부분도 있지만 궁극적으로는 안전하며 안심하고 사용할 수 있는 소프트웨어와 서비스를 제공하기 위해서는 반드시 고려해야 할 필수적인 요소이다.
보안과 신뢰성은 현대 소프트웨어 개발에서는 반드시 최우선으로 고려해야 할 요소이다. 이 책은 보안과 신뢰성에 어떤 문제가 발생할 수 있는지 그리고 이를 어떻게 예방하거나 대처할지에 대해 실용적이면서도 현실적인 조언을 제공한다.
구글은 거대 IT 기업이기 때문에 여러분들이 몸담고 있는 회사의 규모에 맞지 않는다고 느껴질 수도 있지만, 하나씩 천천히 도입해보면 보안과 신뢰성은 점점 더 견고해질 것이다.
책의 구성에 대해서 알아보자.
저자는 먼저 1장과 2장을 읽은 후 그 다음으로 관심이 가는 부분을 읽어보길 권한다.
이 책의 대부분의 장은 다음과 같은 내용으로 구성된 서문이나 실천적인 요약으로 시작한다.
- 문제에 대한 정의
- 각 장이 소개하는 원리와 사례를 적용하기에 적합한 소프트웨어 개발 수명 주기 단계
- 신뢰성과 보안 사이의 교집합 또는 절충
이 책은 업계에서 권장 사례로 여기는 많은 도구와 기술을 추천한다. 하지만 모든 것이 독자 여러분의 상황에 적합하지는 않을 것이므로 진행 중인 프로젝트의 요구사항을 평가하고, 프로젝트의 위협 요소에 적합한 솔루션을 설계하기 바란다.
본문 중의 인상 깊었던 부분을 살펴보자.
신뢰성과 보안은 시스템 설계의 이머전트 속성이다
전체 서비스를 마이크로서비스 같은 여러 컴포넌트로 나누는 방법을 예로 들고 있는데, 구축 과정에서 발생할 수 있거나 예상해야 하는 리스트에 대한 부분을 여러 컴포넌트로 나누고 있다. 이렇게 많은 설계 목표 간에 균형을 맞추는 일은 어렵다는 설명으로 SRE라는 것이 경험이 많이 필요한 영역이라는 것을 말하며, 그 경험에 대한 부분을 책에서 제공해주기 때문에 관련한 직무를 하고 있거나 하고자 하는 개발자라면 직접적인 도움이 될 책이라 생각된다.
아직,
본인에게는 조금 거리가 있는 영역이긴 하나 SRE라는 것을 알고 머릿속에 인지하면서 커리어를 쌓아간다면 목표점이 좀 더 명확해지지 않을까 하는 막연한 기대가 있다.
SRE(Site Reliability Engineering, 사이트 신뢰성 엔지니어링) 말만 들었지 대체 뭔데? 싶은 사람들 SRE? 배포하고 장애대응 말고 뭐 해요? 라는 생각을 가진 사람들 제가 SRE팀으로 이직하게 되었는데요, 뭘 하게 될까요? 가 궁금한 사람들 SRE, 어떻게 하면 더 잘 할 수 있을까요? 다른 회사는 어떻게 하나요? 가 궁금한 사람들
SRE 설계 원칙, 조직 구성, 운영 노하우를 구글의 사례를 통해 확인하실 수 있습니다. 저는 이 책이 오라일리의 다른 책인, 유명한 바로 그 책, 사이트 신뢰성 엔지니어링(원제 Site Reliability Engineering)과 비슷하다고 느꼈는데요. 당연합니다. 둘 다 구글의 SRE 프랙티스를 바탕으로 하고 있습니다. 비슷한 맥락으로 사이트 신뢰성 엔지니어링의 일반적인 원칙과 구글에서 이 원칙들을 어떤 프랙티스로 실천하고 있는지를 보여 줍니다. 다만 사이트 신뢰성 엔지니어링의 초점이 조금 더 보안과 서비스 안전성에 초점이 맞춰져 있습니다. 감이 잘 안 오시죠? 예시를 들어서 설명하겠습니다. "로깅" 이라고 했을 때, SRE성 활동을 하지 않는 조직이라면 그냥 프로메테우스 통해서 들어오는 메트릭이나 조금 보고, 로깅은 애플리케이션 로그만 확인하는 경우가 많습니다. 그래서 침해사고가 발생했을 때에도 침해사고가 발생했는지조차 모르거나, 아니면 인지하더라도 로그가 유실되었다거나, 아니면 어느 로그를 봐야 하는지 몰라 대응이 늦어지는 경우가 있습니다. 이 책에서는 기록할 보안 로그의 지점으로 운영체제 로그(syslog, auditlog 등), 호스트 에이전트 로그, 애플리케이션 로그, 클라우드 로그(AWS라면 cloudtrail 같은 서비스를 이용해 볼 수 있겠죠..), 네트워크 로그 같은 다양한 경로를 소개합니다. 이런 식으로 A라는 SRE 관련 주제가 있다면 그 주제에 대해서 어떤 식으로 정보를 얻을 수 있는지 소스들을 A-1, A-2, A-3,... 이런 식으로 소개해 주고 있어 필요한 것을 골라서 사용하는 책이라고 생각해 주시면 됩니다. 이 책은 이 책만 보고 뭔가를 바로 따라할 수 있는 쿡북은 아닙니다. 대신, 내가 모른다는 것을 모르고 있었던 부분을 채워 나갈 수 있게 키워드를 일깨워 주는 책이다, 라고 생각해 주시면 됩니다.
DevOps 내지는 SRE 조직에서 보안과 안정성에 조금 더 신경 쓰고 싶을 때 읽어보면 좋은 책입니다. 특히, 장애의 정의라든가 조직의 역할 같은 정답이 없는 불분명한 부분에 답을 내려야 할 때 읽어 본다면 구글의 프랙티스와 비교해 보면서 잡히지 않는 부분의 윤곽을 그려낼 수 있겠다 싶은 책이었습니다. 다만, SRE든 DevOps든 경험이 없는 분에게는 추천하지 않고, 실제 애플리케이션 운영을 해 본 경험이 있는 SRE/DevOps/개발팀/인프라 조직의 엔지니어가 읽어 보아야 할 책입니다.
이 서평은 한빛미디어 <나는 리뷰어다> 활동을 위해 책을 제공받아 작성된 서평입니다. (도서는 제공받았으나 저자와는 어떠한 관계도 없으며, 서평의 내용은 모두 개인의 의견으로 작성되었습니다.)
책의 제목에서 짐작할 수 있듯 보안과 신뢰성과 관련된 모든 것을 다루는 책이다. 신뢰성과 보안은 서로 연관이 있으면서도 다른 부분 역시 있다.
신뢰성에 가해지는 가장 큰 위협은 본질적으로 악의적인 것이 아니다. 이와 다르게 보안의 경우엔 시스템의 취약성을 악용하려는 적대적인 사용자에게서 발생한다. 보안과 신뢰성 모두 시스템의 기밀성, 무결성, 가용성 등과 관련있으나 이를 바라보는 시각 또한 다르다.
반면 이 둘에는 공통점 역시 존재한다. 가장 먼저 꼽을 수 있는 것은 불가시성(모든 것이 정상일때는 드러나지 않는다.)이며 그 다음으로 평가 방식이나 간결성 등을 소개할 수 있다. 책은 총 4개의 파트로 이루어져있다. 파트 1은 타이틀 '들어가며'에 충실하게 위의 보안성과 신뢰성 등을 소개하고 보안에서 고려해야하는 공격자의 유형과 동기등을 소개하고 있다. 파트 2 시스템 설계는 가장 두꺼운 파트로 3장에서 10장에 걸쳐 있다. 시스템 설계 단계에 따른 보안과 신뢰성 요구사항을 효율적으로 구현하는 방법을 다루고 있다. 파트 2의 시작인 3장은 사례 연구에 관한 간단한 장이고 4부터 파트 2의 주제와 연관된 얘기를 본격적으로 한다. 파트 3 시스템의 구현은 파트 2 설계에 이어서 계획에 따른 구현을 다루고 있다. 개인적으로 책에서 이 파트를 가장 재미있게 읽었는데 아무래도 바로 적용해볼 수 있는 부분에 대해 다루고 있어서 그런것같다. 추후에 담당중인 서비스에서 적용되지 않은 방안이 있는지, 해당 방안이 적절하다면 어떻게 적용할지 연구해봐야겠다. 파트 4 시스템 유지보수는 서비스 운영시 발생하는 사고에 대처하는 방법에 대해서 다루고 있다. 구글 등의 회사에서 발생한 사건사고등을 실사례로 소개하고, 이에 대한 대처방안들을 소개하고 있다. 파트 5 조직과 문화는 해당 책의 마지막 파트다. 타이틀에서 알 수 있다시피 이전에 설명한 방법을 구현하는데에 있어 문화적인 관점을 중점적으로 소개하는 파트다.
<총평>
보안과 신뢰성을 획득하기 위해서 각 파트의 단계상에서 어떻게 해야하는지 잘 설명한 책이다. 각 파트에서 말하는 바를 자세히 설명하고자 실사례를 들어 이해를 돕고 있으며, 구현 관련된 파트에서는 다양한 언어로 예시 코드도 제시하고 있다. 이제 겨우 주니어를 벗어날까말까 하는 단계인 사람으로서 평소 개발할때 보안이나 신뢰성에 관한 고려가 부족한 상태로 진행했단 생각이 자주 들었었는데 많은 도움이 되었다.
시스템 엔지니어 및 개발자, 아키텍트등 다양한 이해관계자의 관점에서 시스템의 신뢰성이란 매우 중요한 요소중 하나입니다. 갑자기 시스템이 다운된다거나 하는 일이 있어서는 안되기에 그 많은 돈을 들여 모니터링 시스템 및 자동화 시스템을 구축하는 것이죠. 또한 엔지니어에겐 대규모 시스템을 다뤄볼 기회를 가지길 원하는 분들도 많습니다.
그 점에서 이 책은 구글 엔지니어의 관점 및 사례를 바탕으로 잘 정리된 케이스를 하나씩 풀어서 시스템의 신뢰성을 어떻게 확보해야 할지 일종의 가이드 라인을 제시합니다. 초보 엔지니어라면 일종의 지침으로 숙련된 엔지니어라면 그대로 얻는게 있을 책입니다. 저 같은 경우 자동화 된 프록시, 디펜던시의 최신 버전을 유지하고 자주 빌드할 것등 공감이 되거나 경험적으로 이해했던 부분을 설명해 주어 정말 좋았다고 느꼈습니다.
다만, 이 책을 읽을 독자분들에게 모든 부분을 적용하려고 노력하지 마시고 언제나 시스템은 Case by Case 이듯 적절한 절충점을 찾아 적용하시기 바랍니다.
한빛미디어에서 번역서로 나온 SRE를 위한 시스템 설계와 구축은 아주 흥미로웠습니다. 여기저기 파편화돼서 흩어져있던 정보를 이 책 한 권으로 말끔하게 정리한 것 같습니다. 21개의 챕터, 600페이지가 넘는 분량으로 SRE를 위한 정보는 빠짐없이 담으려는 노력이 엿보이는데요. 특히 중간중간 등장하는 구글의 사례는 아주 흥미롭습니다.
특히 "보안과 신뢰성에 대한 책임을 지는 사람은 누구인가?"라는 질문에 "우리는 조직의 전 직원이 보안과 신뢰성에 대한 책임을 갖기를 권한다. 즉, 개발자, SRE, 보안 엔지니어, 테스트 엔지니어, 기술 리드, 관리자, 프로젝트 관리자, 기술 문서 작성자, 임원 등 모두가 책임을 공유해야 한다"라는 답변에 그동안 재직했던 회사들은 어떠했는지 돌이켜볼 수 있었습니다(웃음).
"유리 깨기 메커니즘"도 재밌습니다. 소방전에 '긴급 시 이 유리를 깨시오'에서 유래한 메커니즘이라고 하는데, 긴급 상황에서 승인 시스템을 완전히 우회하여 시스템에 접근하는 방법을 제공한다고 합니다. 일을 하다 보면 이런 경우는 꽤 있습니다. 보통 hotfix라는 이름으로 배포를 했던 경험, 혹은 새로 배포된 기능에서 문제가 발견돼서 빠르게 롤백했던 것 등. 그동안 몇 개의 유리를 깼을까요 :)
이 책이 여러 사람에게 읽힐까를 생각해보면 제목이 주는 무게 때문에 그렇지 못할 것 같습니다. 마치 SRE의 길을 걷고 있거나 목표로 하는 사람을 위한 책처럼 느껴지니까요. 하지만 개발자라면 꼭 한 번은 읽어보길 권해드립니다. 아주 풍성한 배경지식을 얻게 될 테니까요.
구글 엔지니어가 알려주는 안전하고 신뢰성 높은 시스템의 설계부터 테스팅, 복구, 위기 관리까지
시스템이 근본적으로 안전하지 않다면 신뢰할 수 있을까? 보안과 신뢰성은 제품 품질, 성능 및 가용성에 중요한 역할을 하기 때문에 확장되는 시스템의 설계와 운영에 매우 중요하다. 이 책은 안전하고 확장이 가능하며 신뢰할 수 있는 시스템을 설계하는 데 도움을 주는 구글의 구체적인 모범 사례를 자세히 공유한다. 또한, 보안과 안정성에 특화된 실무자의 시스템 설계, 구현 및 유지 보수에 대한 통찰력도 함께 제공한다. 구글러들의 경험으로 얻은 통찰과 SRE 지침을 익혀, 안전하고 신뢰성이 높은 시스템을 구축하길 바란다.
[대상 독자]
- 시스템을 설계하고 구현하는 아키텍처
- 시스템 개발자
- 시스템 관리자
- 보안 엔지니어
[서평]
이 책은 수많은 예제를 제공하고 구글을 비롯한 업계의 성공 스토리와 지난 몇년간의 최신 기술들을 배울수 있다. 인프라스트럭처는 조직마다 다르다. 여기서 제공하는 솔루션 중 어떤 것은 당장 도입해야 하는 것도 있지만 또 어떤것은 현재 한국 기업문화에 맞지 않는 부분도 있다. 그래서 각각의 기업의 환경에 맞게 잘 판단 해야 한다.
먼저 1장과 2장을 먼저 읽어 보고 그 다음부터는 크게 순서 대로 읽을 필요 없이 마음이 가는 파트 부터 읽어도 무방하다. 이 책의 대부은 다음과 같은 내용으로 구성된다.
문제에 대한 정의
각 장이 소개하는 원리와 사례를 적용하기에 적합한 소프트웨어 개발 수명 주기 단계
신뢰성과 보안 사이의 교집합 또는 절충
각 장이 다루는 주제는 가장 기본적인 것부터 가장 복잡한 내용 순으로 정리되어 있다. 또한 ‘더 알아보기’에서는 특화된 주제를 좀더 자세히 설명한다.
업계에서 권장 사례로 여기는 많은 도구와 기술을 추천하지만 모든 것이 현재 한국IT 문화에 맞지 않는 부분도 있어 그걸 감안 하고 읽어야 한다. 이책에서 구글의 전문가들이 왜 신뢰성이 시스템 설계의 기본인지에 대해 설명한 ‘사이트 신뢰선 엔지니어링’책을 참고하면 개념이해에 도움이된다.
시스템을 안전하게 보호하는 기술과 실전 기법을 배우고, 이번 방법들이 어떻게 동작하는지 쉽게 풀어서 설명이 잘되어 있다. 특히 신뢰성과 보안을 소프트웨어와 시스템 수명주기에 직접 통합하는것에 상세히 설명하고 있어 시스템 설계, 구현, 유지보수에 대한 보안과 신뢰성에 관심이 있다면 이책을 꼭 읽어 보는걸 추천한다.
SRE(Site Reliability Engineering, 사이트 신뢰성 엔지니어링)은 IT 운영에 대한 소프트웨어 엔지니어링 방식 중 하나이다.
SRE를 한 마디로 정의하자면 "자동화" 이다. '툴'을 사용해서 관리 및 모니터링을 통해 기존에 많은 부분 수작업으로 진행되던 시스템 운영 방식을 '자동화' 하겠다는 것이다.
이를 통해 운영 태스트를 개선하고 현 시스템의 신뢰성을 향상하고 그 신뢰성을 지속하여 높아지도록 지원한다.
지금 재직 중인 회사에서도 기존 시스템 모니터링을 자동화하기 위해 로그 추적 및 배포 자동화 등 상당 부분 자동화하기 위해 고민하고 있다.그러면 DevOps 와 무엇이 다를까? DevOps 개념은 10여년 전부터 유행했었던 것 같다. 그러다 최근 들어 DevOps 엔지니어에 대한 수요가 많이 늘어난 것 같다. 채용정보를 봐도 DevOps 엔지니어 포지션이 심심치 않게 나오는 것을 알 수 있다.
조대협님은 SRE와 DevOps의 관계를 아래와 같이 정의했다.
class SRE implements DevOps DevOps 는 개발과 운영 조직 간 사일로 현상을 해결하기 위한 일종의 '조직 문화'에 대한 방향성이며, SRE는 DevOps 를 적용하기 위한 실제 구현으로 말이다. 서론이 길었는데, SRE는 구글이 개발-운영 조직 간 문제 해결을 위해 시도한 방법이다.
그리고 이 도서는 구글 내부 엔지니어들이 실제 SRE 를 직접 수행하면서 겪은 사례를 제시하고 있어 SRE 에 대해 보다 상세히 와 닿는다.
사실 빠르게 변화하는 시장 상황하에서 빠른 개발 릴리즈는 회사 입장에서는 매력적일 것이다. 그러나 서비스 런칭 후 시스템을 유지보수 하는 입장에서 안정성을 고민하는 것 또한 중요하다.
이 책은 구글의 뛰어난 엔지니어들이 앞서서 고민하고 부딪혔던 문제들에 대한 고백서(?) 이다.읽어 보면 '헉! 구글에서 진짜 이랬어?' 하는 부분도 있는데, 그러한 문제로부터 지금의 구글을 만들어오지 않았나 싶다. 오늘도 안전한 시스템을 고민하며 이 책을 덮어본다.
구글 엔지니어가 알려주는 안전하고 신뢰성 높은 시스템의 설계부터 테스팅, 복구, 위기 관리까지
시스템이 근본적으로 안전하지 않다면 신뢰할 수 있을까? 보안과 신뢰성은 제품 품질, 성능 및 가용성에 중요한 역할을 하기 때문에 확장되는 시스템의 설계와 운영에 매우 중요하다. 이 책은 안전하고 확장이 가능하며 신뢰할 수 있는 시스템을 설계하는 데 도움을 주는 구글의 구체적인 모범 사례를 자세히 공유한다. 또한, 보안과 안정성에 특화된 실무자의 시스템 설계, 구현 및 유지 보수에 대한 통찰력도 함께 제공한다. 구글러들의 경험으로 얻은 통찰과 SRE 지침을 익혀, 안전하고 신뢰성이 높은 시스템을 구축하길 바란다.
라고 교보문고가 말하더라.
# 이 책의 특징
1. devops라는 것에 관심이 있다면 볼 책
여기서는 Reliability까지 추가해 devsecops라는 말을 했지만.. 아직 우리이게는 앞선 단어일지 모르겠다.하지만 내가 지금 공부하는 구조 설계애서 충분히 쓸 만한 내용이 많다. 특히 내게 있어서는 "재해"라는 용어가 배울만하다고 본다.
2. 구성
구성은 평범하다. 책 두께는 비범하다. 내용은 방대하다.내가 맞는 주제를 보고 읽는 것이 맞다고 느꼈다.
3. 용어설명
용어 설명 또한 충실하다. 책이 괜히 두꺼운 것이 아니다.
한국어로 잘 설명되어 있다. 역자의 노력이 보인다.
4. 내용은 어렵다.
이미 아는 내용 보다 나는 새롭게 등장하는 것들이 많아서 힘들다.
하지만 처음이라 그렇다. 이미 다 알고 있으면 나는 이미 주니어가 아니겠지..?ㅋㅋㅋ
#후기
내가 이 책을 다 읽는다고는 못해도현재 필요한 부분이 있음은 분명하다.하지만 너무 어렵다... 아직은.. 응애 나 아기 개발자SRE 이제 알아볼거다. 업무 프로세스랑 같이 익히면서 잘해보겠다.
SRE는 구글에서 비롯되었다. 대규모 서비스를 하는 회사 특성상 안정성이 매우 중요한데, 이 부분을 체계적으로 발전시키면서 나온 부산물이 이제는 업계의 표준 용어같이 쓰이는 상황이다. IT 인프라가 국가의 중요한 부분이 되면서(최근 러시아의 우크라이나 침략을 보면 정말 극명하게 드러난다) 서비스 안정성과 관련된 법안도 생길 정도이니 말이 필요없다.
Microservice 역시 말이 필요없는 표준 용어나 마찬가지이다. 많은 개발자들이 MSA 하고 싶다고 이야기하지만, 사실 규모 면에서 필요한지도 생각해야 하고, 그냥 여러 개의 서비스로 나누면 microservice라고 착각/오해하는 사람들도 있어서 monolithic으로 하면 괜찮았을 걸 굳이 나눠서 문제가 생기는 경우도 있다. 당연히 “R”eliability가 저하된다.
이 책은 java로 microservice를 할 때 안정성을 확보하고 복원력을 높이기 위해 필요한 거의 모든 것을 다룬다. java를 다루던 회사를 떠나면서 java는 손 놓은지 오래되어서 이제는 예전 방식 코드만 기억이 나기도 하고, 또 오래된 언어 특성상 boilerplate code가 많아 java를 좋아하지 않긴 하지만, 이런 책에서 보여주는 다양하고 강력한 생태계를 보면 가끔 jvm 세상으로 돌아가고 싶어지곤 한다. spring을 다루는 개발자라면 정말 좋은 예제 코드를 얻을 수 있어서 100% 이 책을 활용할 수 있겠지만, 나 같이 java와 무관한 사람이라도 이 책이 설명하는 기본 개념들, metric부터 observability, CI/CD, traffice 관리까지 다양한 설명을 읽는 것만으로도 큰 도움이 될 거라고 확신한다.
넷플릭스같은 회사도 Guava의 dependency 때문에 사이트가 마비되는 경우가 있다는 걸 보면, 우리의 코드베이스에 숨어있는 다양한 (잠재적인) 문제를 찾아내고 방지하는 일이 얼마나 어려운지 알수 있다. 이 책을 읽으면 미처 생각지 못한 문제점을 찾고 방어하는 작업이 얼마나 어려운지 알고, 최소한 ‘시작'이라도 할 수 있다.
시스템의 강건함을 보증하는 지표는 여럿 존재하지만, 그중 두 개를 꼽으라면 단연 보안성과 신뢰성이다. 보안성이 결여된 시스템은 결코 안전한 시스템일 수 없으며 신뢰성에 문제가 있는 서비스는 사용자의 외면을 받기 마련이다. 결국 보안성과 신뢰성을 바탕으로 한 시스템과 서비스를 제공하기 위해 부단히 노력해야하는 수 밖에 없다. 보안성과 신뢰성이라는 속성이 공히 온전히 동작할 때만 강건한 시스템을 유지할 수 있는 것이다.
SRE(Site Reliiability Engineering)라는 단어는 IT 업계에 종사하는 이들에게도 결코 흔하지 않은 용어이다. 이 용어는 최초에 구글에서 고안되었으며, 실제 구글에서는 SRE를 바탕으로 시스템을 운용하고 있고 이러한 추세는 전 세계적으로 전파되고 있는 상황이다. Devops의 실체가 모호한 추상적인 개념이라면, SRE는 Devops라는 이념이 제시하는 실천적인 방향을 제시하는 하나의 엔지니어링 프랙티스로 묘사되고 있는 실정이다. 하지만 용어의 정의가 무엇이 되었든, 중요한 것은 SRE가 지향하는 목표는 '강건한 시스템을 설계하고 그 바탕위에 구축된 시스템을 운용하며 유지될 수 있도록 노력하는 것'에 있다고 생각한다. 오늘은 SRE의 실천 이념을 바탕으로 세상에 그 모습을 드러낸 'SRE를 위한 시스템 설계와 구축'이라는 도서에 대해 얘기를 나누고자 한다.
이 책은 실제 구글에서 활동한 전문가들에 의해 출판되었고, 그들의 생생한 경험에 입각한 내용이 도서 전반에 녹아 있기 때문에 독자들로 하여금 SRE와 관련된 서술에 대해 한층 신뢰성을 높이고 있다고 해도 과언이 아니다.
책의 도입부는 보안성과 신뢰성이 시스템에 어떠한 영향을 미치는가에 대해 운을 떼며 서막을 알린다. 이윽고 시스템 설계와 관련된 중요하면서도 결코 간과할 수 없는 사상과 엔지니어링 프랙티스에 대해 서술을 이어 나간다. 이를테면 최소 권한의 원칙과 이해 가능성, 범위의 변화, 회복성, 복구와 관련 된 다양한 저자들의 생각과 실제 경험에서 빚어진 실증 사례가 언급되며 보안성과 신뢰성을 기반으로 한 설계의 중요성을 역설한다.
시스템 설계 이후의 시스템 구현, 시스템 유지 보수에 이르는 일련의 시스템 생애주기에 대한 실천적이고 유용한 다양한 팁이 여과 없이 제공되며 책의 후반부에 이르러서는 조직과 문화에 대한 주제로 이야기는 마무리 된다. 결국 보안성과 신뢰성을 기반으로한 시스템 구현에 있어, 그 중심에 있는 사람과 이를 둘러싼 조직, 조직의 담론을 형성하는 문화의 중요성은 시스템이 아닌 사람에게 초점이 맞춰지며 담대한 여정이 종지부를 찍게 된다.
다시 한번 이 글의 처음으로 돌아가, 시스템의 강건함을 보장하기 위해서는 보안성과 신뢰성이 무엇보다 중요함에 대해 강조하고자 한다. 결함 없는 완전한 시스템은 이 세상에 존재하지 않기에, 제대로 굴러 가는 온전한 시스템을 설계하고 운영하며 유지하기 위해서는 보안성과 신뢰성을 기반으로 한 엔지니어링 프랙티스가 중요함을 절실히 깨닫게 해 주는 계기가 되었다. SRE의 정수를 온전히 맛볼 수 없지만, 강건한 시스템을 구현하는데에 관심이 있는 독자라면 이 책과 그 여정을 시작하길 바란다.
시스템 설계의 기본이 되는 신뢰성을 기반으로 어떻게 구글이 운영되는지 그 노하우를 담고 있다. 보안에 대해 지식이 좀 짧지만 SRE라는 단어를 만든 것이 구글이라는 것은 알고 있다.
저자 목록을 쭉 훑어보는데 엔지니어링뿐 아니라 테크니컬 라이터들도 다수 참여했다. 이 분야가 그만큼 여러 분야에 미치는 영향력이 커졌고 또 그렇기 때문에 보안을 넘어서 소프트웨어 개발에도 넓게 영역을 차지한다는 것을 새삼 느낄 수 있다. 그래서 그런지 책이 무지 두껍다. 저자도 이를 알아서 친절하게 구성을 설명하며 어떻게 읽어야 할 지 가이드를 내려준다.
1-2장 부터 읽고 흥미로운 분야 우선으로 읽되, 구글과 동일한 조직환경이 아닐 수 있으므로 감안해서 내용을 읽으라고 한다. 어떻게 보면 회사라는 것은 이래서 흥미롭다. 각 회사마다 동일 산업에 속하더라도 사용하는 평균 데이터 크기나 처리하는 데이터의 성질, 비즈니스의 속성 등에 따라서 벌어지는 일들이 제각각이다. 어떤 곳은 아주 빨리 대용량의 데이터를 실시간으로 처리하는 게 중점인데 반해 어떤 곳은 속도가 그닥 중요하지 않고 천천히 쌓이는 데이터를 잘 다듬어서 분석에 용이하게 만드는 게 더 비중이 크기도 하다. 이 두가지 모두다 중요한 큰 회사들도 있다.
구글의 힘은 이렇게 이전에 존재하지 않았던 새로운 시도를 해서 그걸 개념화하고 일반화하는 데에 장점이 있다고 생각한다. 물론 이 1개의 차별화를 위해 수많은 아이디어 무덤이 생기기도 한단다.
나도 가끔 구글 서비스를 이용하면서 이거 안전한 거 맞아? 라는 생각이 들 때가 있다. 주로 크롬을 사용하면서 궁금한 점이 생긴다. 다행히 책의 5부. 조직과 문화 에서 '사례 연구: 크롬 보안 팀' 챕터에서 궁금한 점을 어느 정도 해소할 수 있었다. 크롬의 보안팀이 커지게 된 배경을 읽고 나니 결국 어느 정도 경험이 쌓이거나 코드를 만지고 서비스를 키워보면 보안은 수강 필수과목이 되는 것 같다. 혼자서 뭔가를 만들어 세상에 내놓았는데 만약 운좋게 사람들의 관심을 받게 된다면 그 관심의 일부는 악용되어 취약한 보안을 공격할 수도 있다. 구글은 결국 모든 엔지니어가 일상적으로 보안을 고려한 개발을 하게 되었다고 말한다. 굉장히 좋은 업무방식인 것 같다. 그리고 이런 구글의 보안팀 운영에 있어서 중요하게 작용한 게 '어떻게 조직을 구성할 것인가' 였다. 집중 분야를 책임질 리드를 먼저 정하고 그 뒤에 관리자를 선정했다고 하며 '리드'의 경우는 종합적으로 보안 이슈를 체크하고 팀에게 정보를 정리해주며 프로젝트 협업 등 스케줄 또한 검토하는 훌륭한 PM...이 되어야 함을 설명한다. 굉장히 빡시겠다... 어떤 의미로는 정말 훌륭한 오케스트라 음악을 연주할 수 있는 지휘자 혹은 예술가 같다고 생각한다.
그리고 책을 읽으면서 이게 쿡북처럼 기술을 나열한 뒤 잘 연습하게 도와주기보다는 그냥 뭔가 경험담? 체험담처럼 쉽게 써있어서 술술 읽혔고 의외로 흥미로운 부분이 많았다.
그리고 맨 첫장부터 시작하는 구글의 보안 에피소드. 로드 밸런싱과 로드 셰딩이라는 신뢰성 측면과 시스템 보안을 위해 설계한 복잡한 과정이 합쳐져서 우여곡절 끝에 사태를 수습하게 된다. 이처럼 신뢰성과 보안은 중요한 두 축이지만 결이 조금은 다르다. 책은 이를 비교하면서 각각을 설계할 때 어떤 요소가 중요한지 설명한다.
그리고 2장에선 보안의 주적이 누군지를 설명한다.
1. 취미로 즐기는 사람
2. 취약점 연구원
3. 정부와 법 집행 기관
4. 운동가
5. 범죄자
6. 자동화와 인공지능
7. 내부자
이후 챕터들은 이런 공격자에게 비효율적이고 비경제적인 공격을 하도록 하여 포기하도록 유도하는 내용들이다. 구글에서 일단 일어난 일을 바탕으로 설명하기 때문에 참고할 때 도움이 되고 일을 수습하고 해결하는 과정에서 어떤 교훈을 얻었는지도 상세하게 설명해준다. 구글 내부에서 어떻게 신뢰성과 보안을 고려한 시스템 설계를 하는지 자세히 알 수 있고 동시에 어떤 상황이 공격에 취약한지도 학습할 수 있어서 유익했다.
일하다 보면 복잡한 스펙과 빡빡한 일정 때문에 보안, 가용성, 성능, 안정성 등에는 관심을 두지 못하고 개발만 하게 되는 경우가 있습니다. 그러다 보면 자연스럽게 여러 기술 부채를 지게 됩니다.
이런 기술 부채는 단순히 코드의 개선점 수준이 아니라 장애 발생, 개인 정보 유출, 지나치게 많은 운영 비용 등 비즈니스에 위해를 가하는 치명적인 문제로 발현되기도 합니다.
보안, 안정성 등의 주제는 개발을 한참 진행하고 나서 개선하기가 만만치 않습니다. 개발 초기부터 목표와 설계에 포함하고 개발 업무 프로세스 전반에 걸쳐 반드시 필요한 프로세스로 내재화할 필요가 있습니다.
이 책은 개발자에게 이런 일들이 왜 중요한지에 대한 깊이 있는 통찰을 제공합니다. 서비스 설계 단계부터 개발, 배포, 운영, 장애 대응, 후속 조치와 이에 필요한 조직 문화에 이르기까지 우리가 실제로 고민하게 될 주제들을 폭넓게 이야기 하고있습니다.
이 책을 읽고 한 단계 더 좋은 개발자로 성장하는데 필요한 고민들을 해볼 수 있으면 좋겠습니다.
구글은 (모든 IT인들이 그렇겠지만) 특히나 서버개발자에게 가장 선망의 대상이 되는 회사 중 한 곳이다. 구글급 사이즈의 전 세계에서 들어오는 엄청난 트래픽을 문제없이 소화하는 능력은 아무데서나 얻을 수 있는 능력이 아니기 때문이다. 그렇다고 구글의 장애율이 0%는 아니지만 문제에 대한 예방과 복구 프로세스 등이 잘 정립되어 있다. 그런 구글에서 많은 개발자, SRE, 보안전문가 등이 모여서 집필한 이 책은 수십 년간의 구글의 사례와 노하우들이 녹아들어 있다. 제목은 SRE를 위한다고 쓰여있지만 그렇지 않다. SRE 뿐만 아니라 서버개발자, 더 나아가 프론트개발자, 데이터 분석가 등 모든 개발자들에게도 도움이 되는 보편적이고 공통적인 내용들도 많이 있다.
허구한 날 비밀번호가 노출되었다고 연락이 오고 하루에도 몇 번씩 다운되는 서비스를 사용하고 싶은 사용자가 있을까? 사용자 입장에서도 안전하지 않고 신뢰성이 없는 서비스는 쓰고 싶지 않지만, 기업 입장에서도 이는 굉장한 영업 손실로 이어진다. 쉬운 예로 주말 저녁 피크타임에 배달앱이 몇 시간 동안 마비가 된다면 배달앱 업체뿐만 아니라 가게 사장님, 고객 들까지도 모두 손해를 보게 된다. 요새는 IT가 접목되지 않은 서비스가 사실상 없고 상당히 많은 부분들이 앱이나 웹 같은 서비스를 통해 이루어진다. 이런 상황이다 보니 서비스의 보안과 신뢰도는 더 이상 2순위가 아니게 되었다. 기능이 좋아 매우 많은 사용자를 끌어 모았다고 하더라도 보안 사고나 신뢰성 부분에 문제가 생긴다면 외면받는 것은 순간이다. SRE가 따로 없는 회사라 할지라도 SRE에 대한 투자와 강화는 항상 해야 하고 할 수밖에 없다.
서버개발자로 일하면서 무심코 지나갔던 부분들도 깨닫게 되었다. 예를 들어 서비스 다운 같은 것에 대비해 신뢰성을 높이기 위해 이중화라던지 메시지 큐 도입 등을 하면 보안 위험도가 증가하고 (개인정보 저장같은), 그것에 대비해 보안 위험도를 낮추면 또 이번에는 신뢰성이 낮아지게 되는 케이스도 있다고 한다. 변화(보안이든 코드든 모든 것에 대응이 가능해 보인다)에 대한 내용도 나온다. "변화는 증분적이어야 하고, 문서화되어 있어야 하고, 테스트를 거쳐야 하고, 격리되어야 하고, 검증되어야 하고, 단계적이어야 한다" (p.181) 개발로 인한 코드 변화가 해당 원칙들을 지키고 있는지도 다시 한번 돌아보아야겠다.
12장엔 코딩에 관한 보편적인 내용들도 나온다. 다중 중첩 방지, YAGNI 스멜 제거, 기술부채 해소, 리팩토링 등이 있다. 또한 기본적인 보안과 신뢰성을 지키기 위해 메모리 안전한 언어 사용을 권하고, 강력한 타입 및 정적 타입 검사 사용을 권하고 있다.
14장 코드 배포에 대한 내용 중에 다음 내용들이 눈에 들어왔다.
1. 코드 검토를 반드시 실행하자 2. 자동화를 도입하자 3. 사람이 아닌 결과물을 검증하자 4. 설정을 코드처럼 관리하자
4개 항목 어느 하나 소홀할 것이 없어 보인다. 코드 검토 (흔히들 코드 리뷰라고 부르는)를 코드의 퀄리티와 안정성을 보장해준다. 자동화는 사람의 실수를 방지해 준다. 결과물을 검증해야 배포자의 실수라던지 악의적인 사용자의 행위를 막을 수 있다. 쿠버네티스 같은 컨테이너 환경을 사용하면 설정을 코드로 이미 관리하고 있다고 한다.
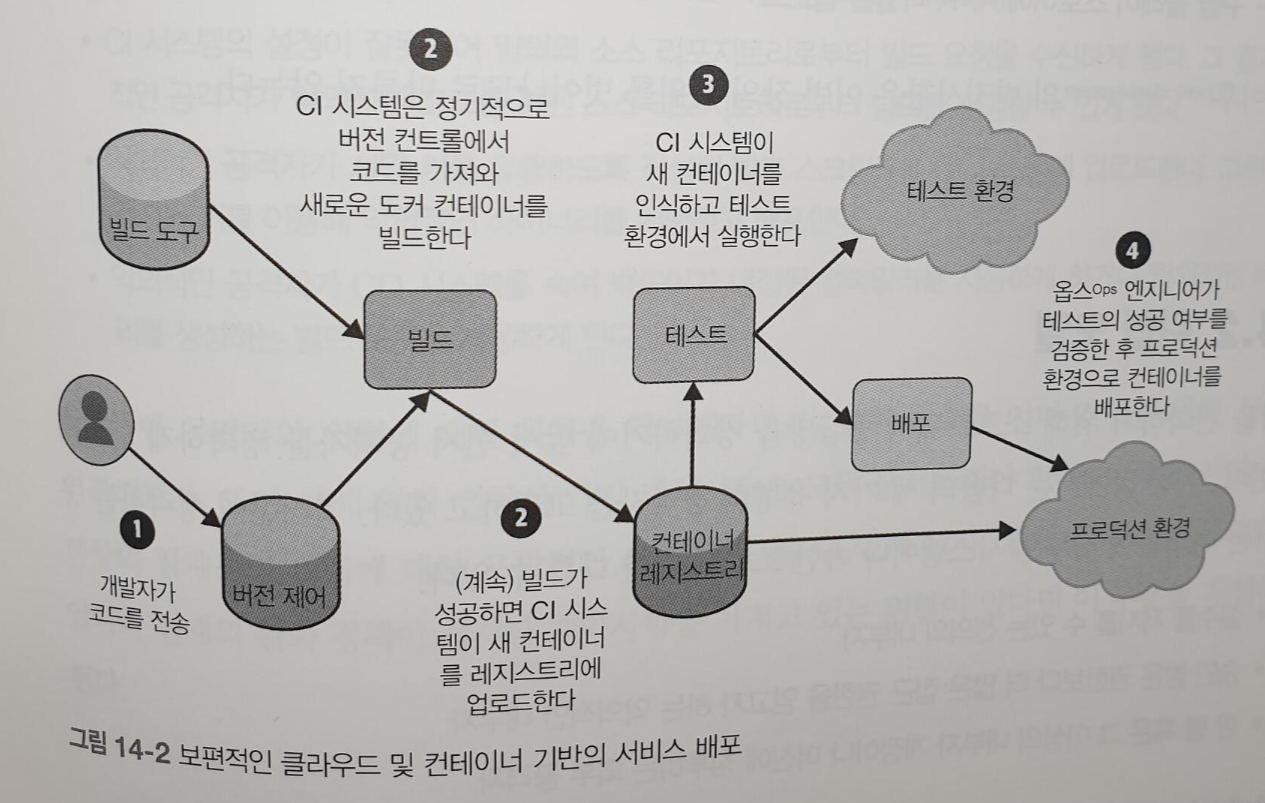
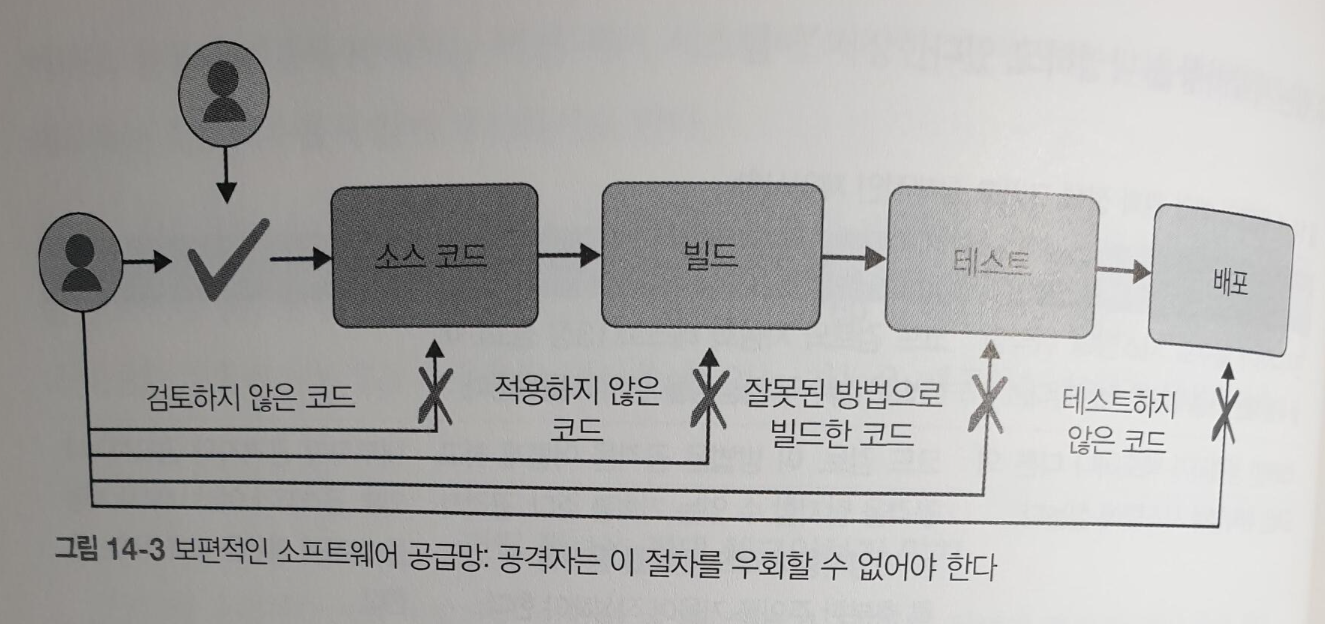
그리고 아래 그림처럼 각 단계를 우회할 수 없어야 한다고 했는데 우리 시스템이 이런가 반성하게 되는 계기도 되었다.
<정말 우회할 수 없을까?>
15장 시스템 조사에서는 디버깅에 대해 명언을 찾을 수 있었다.
문제를 해결하고 수정하기 위해 마법을 불리 필요는 없다. 단지 느리지만 구조화된 조사 과정을 거치면 된다. (p. 420)
자칫 지루하고 따분한 일이 될 수 있는 게 디버깅이지만 중요하고 가치 있는 일이다. 디버깅을 잘하는 왕도는 없으며 끈기와 노력이 중요한 것 같다.
17장 사고 대응에 대한 내용에서는 아래의 도표가 눈에 들어왔다. 구글 같은 글로벌 서비스는 세계 각지에 직원들이 있고 사고를 24시간 계속해서 대응할 수 있다는 점이 놀라웠다.
<24시간 사고 대응이 가능한 구글>
책의 내용과 분량이 상당히 방대하고 다양하다. SRE뿐만 아니라 다른 개발자들도 읽어 보면 좋을 것 같다. 구글만큼 큰 서비스를 운영하고 있지 않더라도 분명 도움이 되는 내용이며, SRE가 따로 없는 우리 회사의 경우 내가 언제라도 SRE로서의 역할도 할 수 있게 관련 역량들을 계속 쌓아 나가고자 한다.
이 책은 구글이 수많은 서비스를 개발하고 운영하면서 터득한 보안과 신뢰성 관련 경험 및 지식을 총망라한 책이다. 보안과 신뢰성이 왜 중요한지, 보안과 신뢰성에 어떤 형태로 구멍이 생길 수 있고 또 이를 예방하려면 어떻게 해야 하는지에 대해 실용적인 조언을 제공한다.
보안과 신뢰성은 모든 정보 시스템에서 가장 중요하고 기본적인 속성이지만, 실제 사고가 발생한 이후에 고치려면 상당한 추가 비용이 든다는 공통점이 있다. 그러므로 이 책은 모든 사람이 개발을 시작하는 단계에서부터 보안과 신뢰성에 대한 부분들 고민해야 하며, 이러한 원리들을 시스템 수명 주기에 최대한 일찍 통합해야 한다고 강조한다.
더불어 위와 같은 요구사항을 시스템 설계 단계에서 비용 효율적으로 구현하는 방법, 최소 권한 모델을 도입하여 알려지거나 알려지지 않은 사용자가 악의적 혹은 실수로 시스템과 데이터에 피해를 주는 상황을 보호하는 방법, 시스템 장애 발생 시 진행할 복구를 고려해 시스템을 설계하는 방법 등 시스템의 신뢰성과 보안을 향상시키는 데 도움이 되는 내용들이 상세히 담겨있다.
다만 구글의 사례이므로 실제로 책을 읽는 독자들의 조직에는 적용하기 어려운 부분들이 있을 수도 있지만, 업계 최고 전문가들의 수십 년의 경험과 풍부한 지식을 한 권의 책을 통해 얻을 수 있는 기회이므로 각자의 상황에 따라 다양한 인사이트를 얻을 수 있으리라 기대한다.