요즘 서점에 가보면 IT분야는 머신러닝, 딥러닝 책들이 주를 이룬다.
이러한 흐름에 더불어 Data Science(어색하긴 하지만 이하 데이터 과학)라 일컫는 데이터를 분석하는 영역에 대한 책들도 꽤 눈에 띈다.
어떻게 생각해보면 머신러닝이니 딥러닝이니 하는 것들도 다 데이터를 분석하고 이용하기 위한 방법이나 수단의 한 방편에 불과하고 크게 보면 데이터 과학의 관점에서 거시적에서 미시적으로 접근하는게 올바른 접근법이 아닌가 싶기도 하다.
'파이썬과 대스크를 활용한 고성능 데이터 분석'이란 책은 후자에 가깝다.


소위 요즘 말하는 머신러닝, 딥러닝은 대량의 데이터와 이를 처리하는 컴퓨팅 파워가 필수적이다, 이를 위해 필여적으로 필요한 것이 메모리와 병렬처리라 할 수 있는데 이를 위해 이 책에서는 대스크(Dask)를 이용해서 이러한 것들을 효과적으로 수행하기 위한 방법을 소개하고 있다.
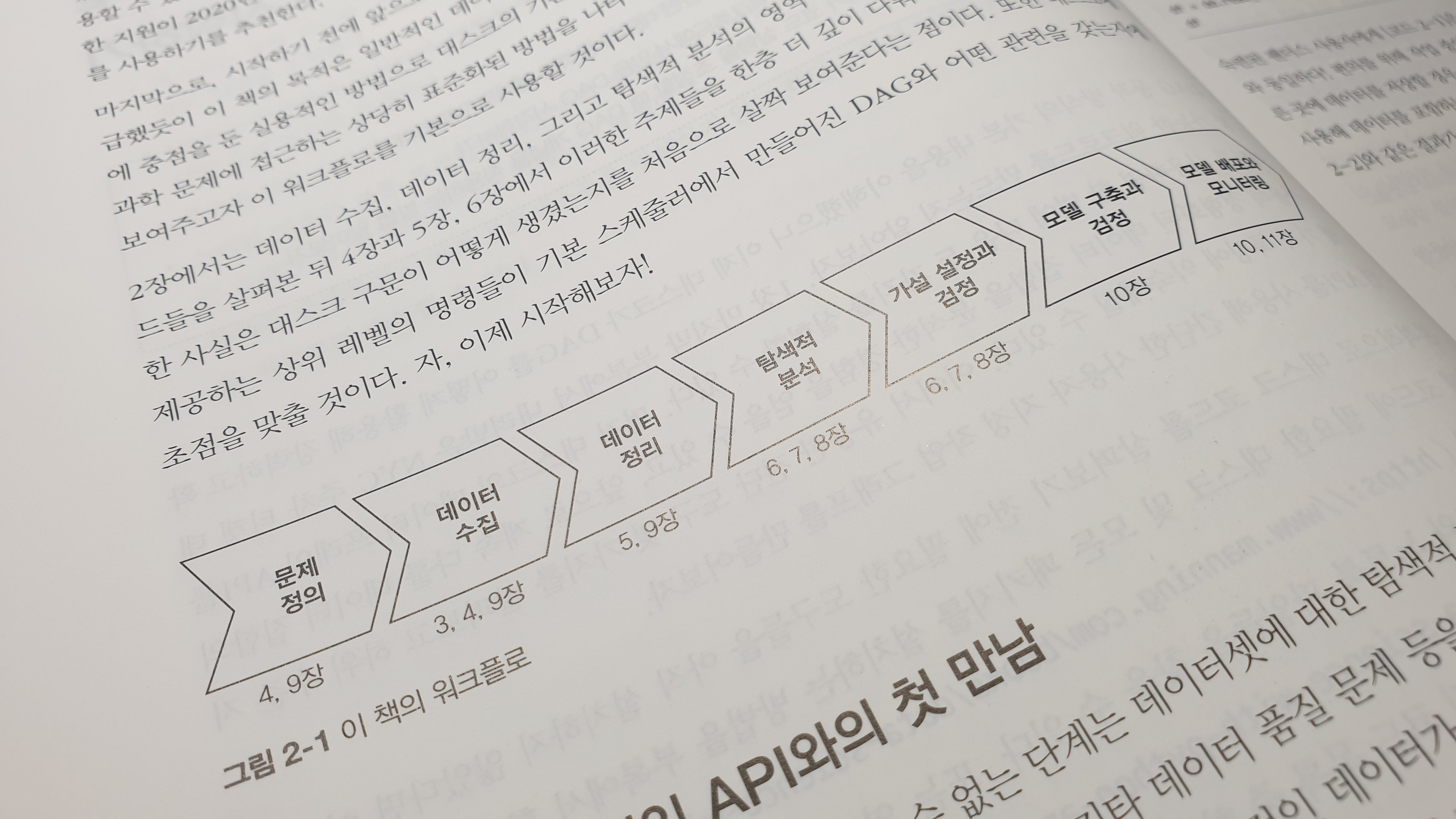
전반적인 책의 내용은 일반적인 데이터 과학 관련 작업을 수행할 때 대스크를 적용하여 처리하는 방법에 대한 내용을 담고 있다.
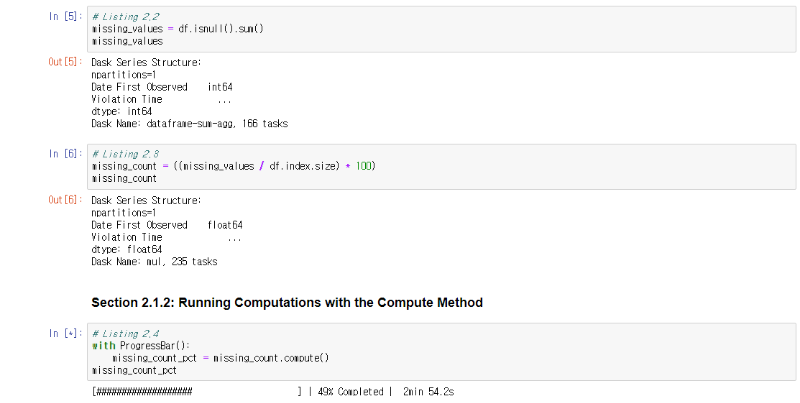
앞서 이야기 한대로 대용량 데이터를 처리할때 대용량의 메모리와 CPU(또는 GPU) 파워는 필연적이다. 흔히들 기본적으로 사용하는 넘파이(Numpy)나 판다스(Pandas)를 이용한 모델 학습 등을 할때 대용량 데이터를 통으로 돌리다 보면 메모리 문제로 죽는 경우를 왕왕 볼 수 있다.
대스크는 아래 그림에서도 알수 있듯이 대용량 데이터를 여러개로 분할해서 하나씩 또는 병렬로 처리함으로써 상대적으로 적은 메모리상에서도 데이터 분석 모델을 돌리는 것이 가능하다.

몇년전서부터 데이터 사이언스 영역에서는 시각화 분석이 유행이다, 시각화 분석에 특화된 TIBCO Spotfire와 같은 사용 전문 툴에 비할바는 아니겠지만, 이 책은 분석을 시각화 하는 부분에 대해서도 언급하고 있다.
뿐만 아니라 ML모델을 구축하고 이를 빌드하고 패키징, 배포하는 것까지 두루두루 다루고 있다.
대스크를 이용해서 비정형 데이터를 처리하는 것도 가능하지만 대규모 정형데이터 처리에 효과적으로 적용해볼 수 있을것 같다.
이 책은 이러한 고민을 가지고 있는 사람들이 입문하기에 꽤 괜찮은 접근법을 제시하고 있다, 데이터 분석에 첫발을 내딛거나 대용량 데이터 처리가 필요한 분들에게 좋은 인사이트를 제공할꺼라 생각한다.
※ 본 리뷰는 IT 현업개발자로서 한빛미디어 리뷰어로 출판사로부터 제공받아 읽고 작성한 글입니다.