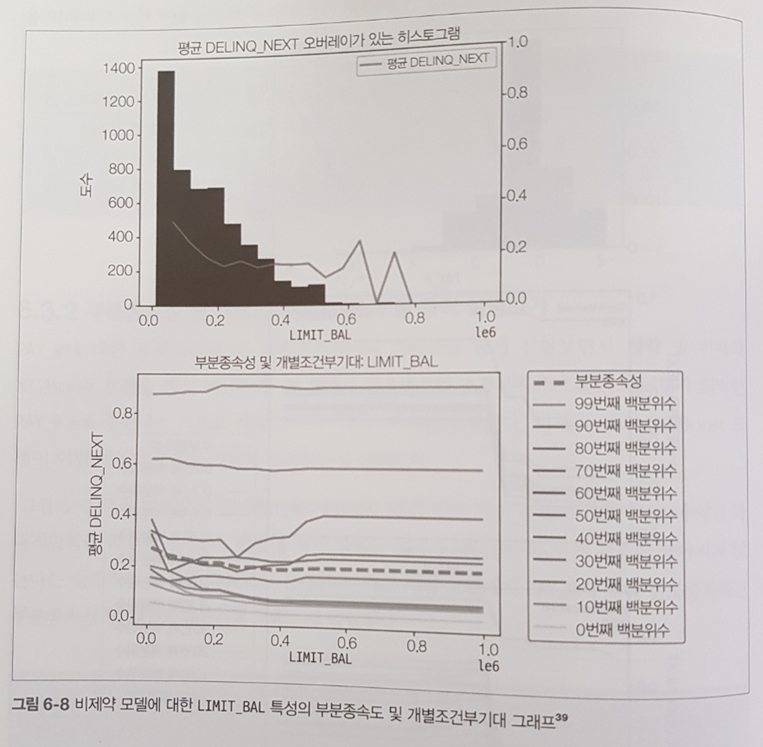
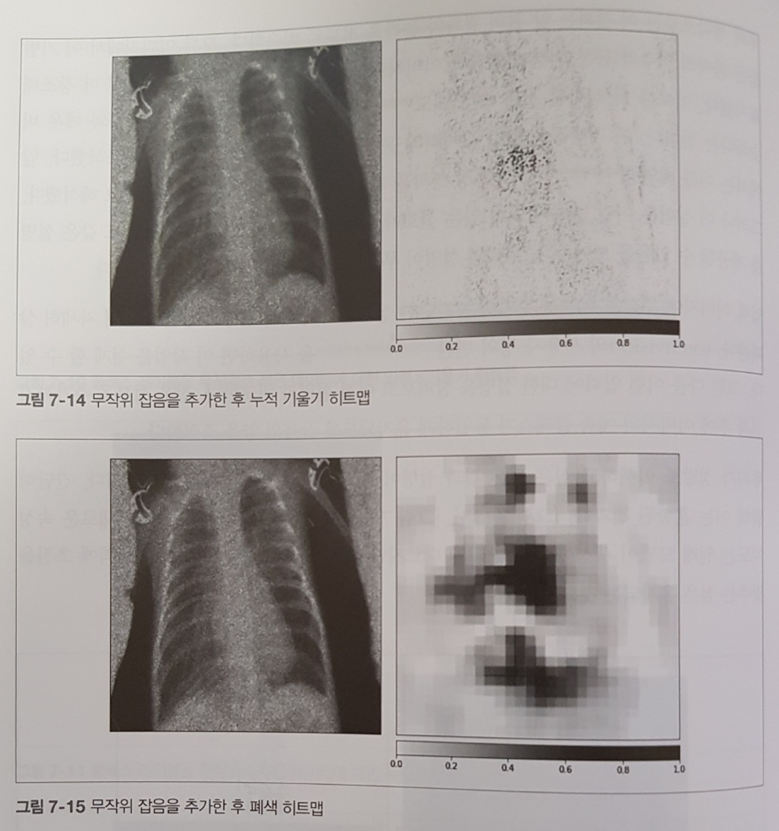
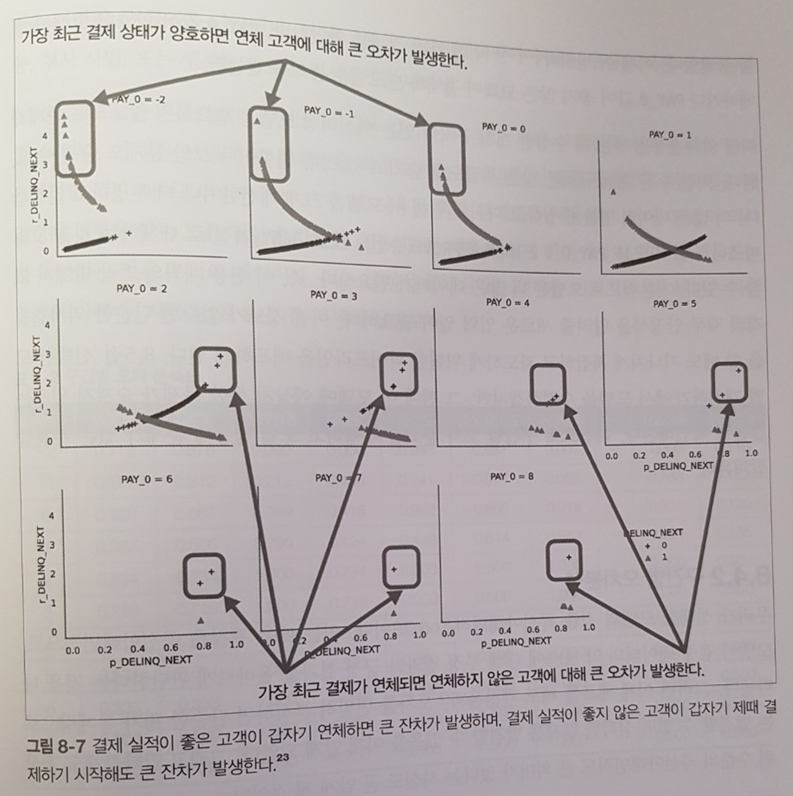
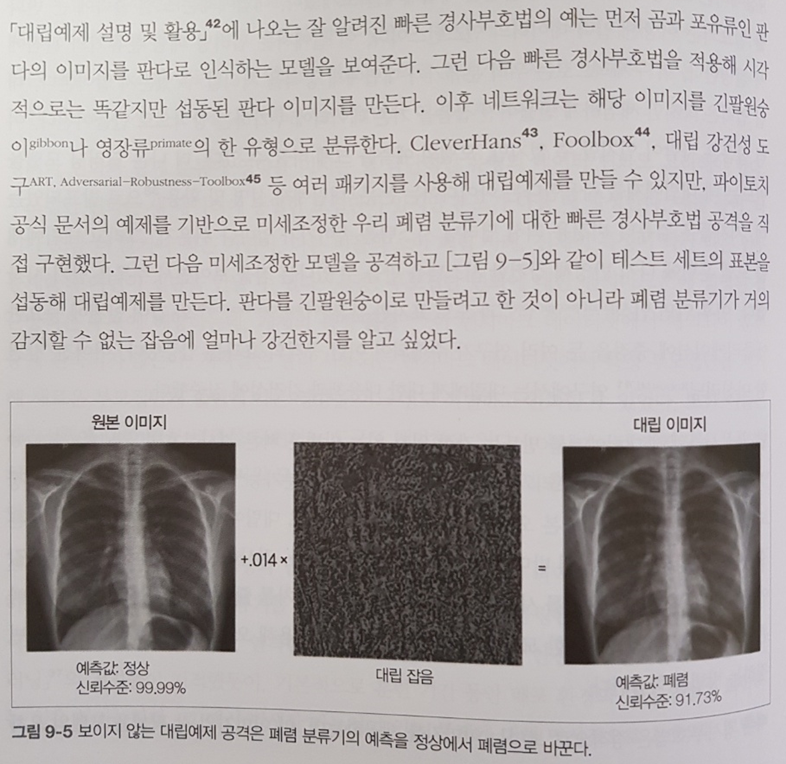
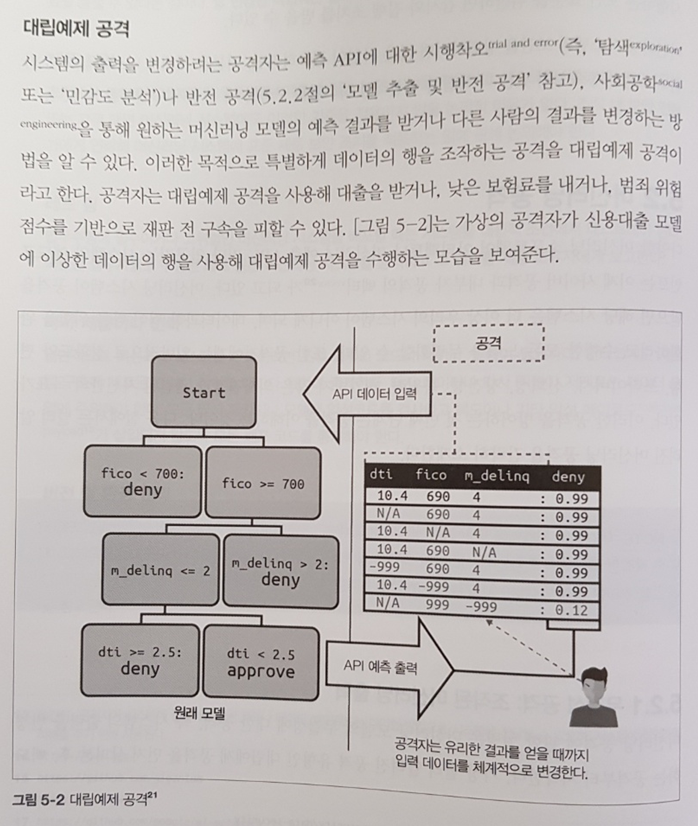
의사결정나무는 if-then 분기가 5단계를 넘어가면 해석하기 어려워진다. 또한, 사운드나 이미지, 비디오, 텍스트와 같은 비정형 데이터에서는 성능이 나빠지는 경향이 있다. (p.92)
주어진 데이터셋에 대해 가능한 모델이 많은 이 문제는 좋은 모델의 다중성과 라쇼몽 효과라는 두가지 이름으로 불린다. 라쇼몽 효과는 과소특정화라는 또 다른 문제와도 관련이 있는데, 초매개변수 조정과 검증 데이터 기반 모델 선택은 테스트 시나리오에서는 괜찮아 보이지만, 실제로는 실패하는 모델이 만들어지는 것을 의미한다.(p.92)
사후 설명의 단점 3가지
모델을 이해할 수 없으면 설명도 할 수 없다
머신러닝 모델은 너무 복잡해서 정확하게 요약할 수 없다
머신러닝 시스템에 관한 설명 정보를 광범위한 사용자와 이해관계자에게 전달하기 어렵다.(p.97)
해당 분야에서의 성능을 고려하면 평가 통계량의 정확한 수치보다는 가상환경에서의 성능을 실제 성능에 맞추는 것이 더 중요하다.
--- 또한 둘 이상의 측도를 사용하고 데이터의 중요한 부분 외에 훈련과 검증, 테스트 데이터 파티션 전반에서 성능 계량을 분석하는 것이 중요하다. (p.148)
훈련에서의 불안정성은 주로 적은 훈련 데이터나 훈련 데이터에서의 희박한 영역, 훈련 데이터에서 상관관계가 높은 특성, 또는 심층 단일 의사결정나무와 같이 분산이 큰 모델 형태와 관련이 있다. 교차검증은 훈련에서의 불안정성을 감지하는 대표적인 도구다(p.152)
하나의 특성 중요도가 다른 모든 특성의 중요도를 크게 압도한다면, 실제 신뢰성과 보안에 나쁜 영향을 미친다. 이 중요한 해당 특성의 분포가 변하면 모델의 성능이 떨어질 수 있다.(p.162)
NIST의 최근 연구인 "인공지능의 편향 식별 및 관리표준"에서는 편향의 대상을 구조적 편향과 통계적 편향, 인적 편향으로 구분한다.(p184)
예를 들어 4장의 편향 부문 소제목까지 살펴보자
기본적인 편향의 정의, 분류만 있는 게 아니라, 어떻게 테스트를 하고 편향을 줄일 수 있는지에 대한 지식들이 포함되어있다(관련 논문도)
4.1 ISO 및 NIST의 편향 정의
4.1.1 구조적 편향
4.1.2 통계적 편향
4.1.3 인적 편향 및 데이터과학 문화
4.2 미국의 머신러닝 편향에 대한 법적 개념
4.3 머신러닝 시스템의 편향을 경험하는 경향이 있는 사람
4.4 사람들이 경험하는 피해
4.5 편향 테스트
4.5.1 데이터 테스트
4.5.2 기존 접근방식: 동치결과 테스트
4.5.3 새로운 사고방식: 동등한 성능 품질을 위한 테스트
4.5.4 미래 전망: 광범위한 머신러닝 생태계를 위한 테스트
4.5.5 테스트 계획 요약
4.6 편향 완화
4.6.1 편향 완화를 위한 기술적 요소
4.6.2 과학적 방법과 실험설계
4.6.3 편향 완화 접근방식
4.6.4 편향 완화의 인적 요소
4.7 사례연구: 편향 버그 바운티
책 서문에 "이 책은 머신러닝이나 머신러닝 위험관리를 책임 있게 사용하는 방법을 배우려는 초중급 머신러닝 엔지니어 및 데이터과학자를 위한 기술서다." 라고 명시되어있다.
찾아보니 2023년에 과기부와 TTA에서 "신뢰할 수 있는 인공지능 개발 안내서"가 발간되었다. 체크리스트와 간략한 설명을 제공하는 데 유용해보인다. 사실 인공지능을 적용할 줄만 알지, 그것의 위험관리를 고민하는 분위기는 아직 시작되지도 않은 것 같다.
이론적 설명이지만, 어려운 용어들도 많이 등장한다. 인공지능을 어떤식으로든 적용하는 분들 모두에게 추천할만 하다. 사고나기 전에 보안을 챙기지 않았던 것처럼, 인공지능에 대한 위험도 준비를 해야할 때 이 책이 좋은 길잡이가 되어줄 것 같다.
"한빛미디어 < 나는리뷰어다 > 활동을 위해서 책을 제공받아 작성된 서평입니다."