요근래 나는 조직이 변경되었다. 예전의 나를 소개할때는 통신 소프트웨어 엔지니어라고 소개되었는데, 이제는 하는 업무가 딥러닝/강화학습 적용쪽으로 변경되었다. 그러면서 개발환경도 이전의 C언어로 짜던 것이 이제는 Python으로 외부 라이브러리도 내 입맛대로 가져다쓰고 개발하고 있다. 아무래도 딥러닝/강화학습을 하려다보니 주어진 dataset을 처리할 기회가 많아지고, 이를 다룰 패키지인 numpy나 pandas, matplotlib에 대한 활용 케이스가 많아졌다. 특히 요근래에는 시각화 관련해서 공부도 좀 하고 있었다. (찾아보니까 보통 matplotlib을 쓰긴 하지만, 사용자에 따라서는 seaborn을 사용하기도 하고, bokeh 같은 걸 쓰기도 한다. 좀더 찾아보니까 시각화 라이브러리인 d3.js를 활용한 케이스도 많은거 같다..)
사실 집에 예전 리뷰를 한다고 받았었던 "파이썬 라이브러리를 활용한 데이터 분석"(한빛 미디어) 책이 이런 데이터 처리와 관련해서 잘 설명되어 있다. 흔히 numpy, pandas, matplotlib 관련해서 처음 입문하는 사람한테는 간단하게 응용해볼 수 예제와 설명들이 들어있는 책이고, 무엇보다 두껍다. 그런데 인터넷을 통해서 많이 샘플 코드를 찾아보고, 좀 현업에 응용해보고자 하는 사람이라면 그 책으로는 갈증을 해소하기에 조금 부족할 것이다. 그래서 현업에 좀 응용해보려면 혼자서 고민을 해봐야 되는 측면이 있다. 지금 소개할 책이 어쩌면 그런 책일 듯하다.

우선 Scipy를 모르는 사람에게 잠깐 소개하자면 Scipy는 Open source 형태로 개발되고 있는 수학/과학 연산을 위한 패키지 set이다. 조금 두루뭉실하지만, 아마 데이터처리를 공부하거나, 현업에서 활용하는 사람이라면 이미 이 scipy를 다 쓰고 있다. 앞에서도 소개한 numpy, pandas, matplotlib들이 모두 이 scipy 패키지에 포함되서 유지/관리되며, 배포되고 있다. 참고로 scipy 구성 요소는 다음과 같이 되어 있다.
- numpy : 고차원 배열 데이터 연산을 위한 패키지
- pandas : 다량의 데이터를 처리하기 위한 구조 및 처리
- matplotlib : 시각화 패키지
- IPython : Interactive console 제공 (유저에게 데이터 처리를 할 수 있는 여지를 부여함)
- Sympy : Symbolic 수학 연산
- Scipy : 과학/수학 관련 연산에 필요한 기능 제공
그래서 책 제목에도 표현되어 있다시피 Scipy내 API들을 활용해서 다양한 예제를 다루는 책이다. (사실 scipy라고 명시는 되어 있지만, 예제를 살펴보면 sklearn 같은 다른 패키지를 활용한 예제들도 있다.)
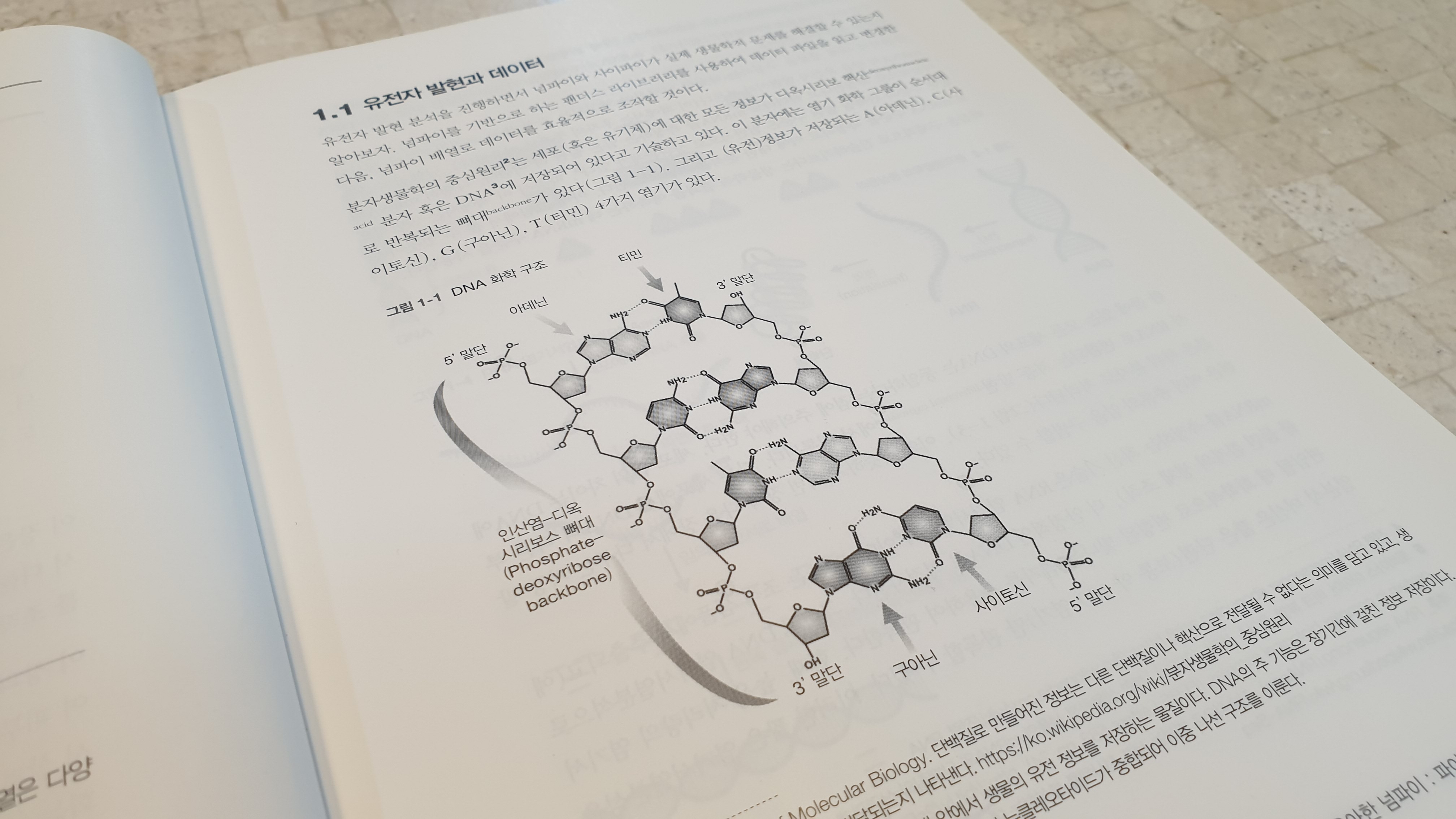
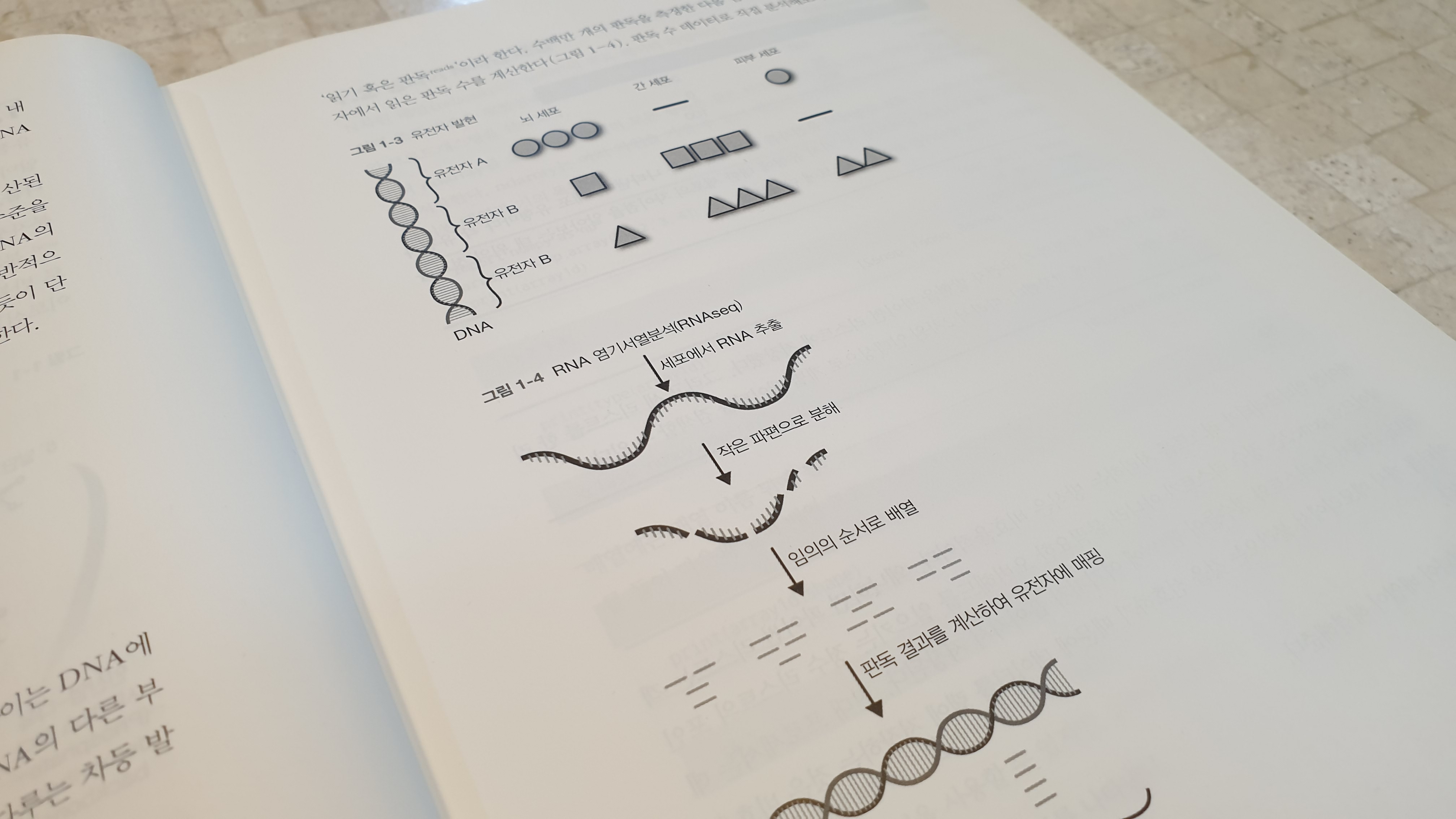
이 책의 특징이라고 한다면, 무엇보다 책 내에서 언급되고 있는 예제들의 주제나 수준이 여타 데이터처리 책들에 비하면 좀 생소하다는 점이다. 아마 저자의 전공 주제가 책에도 영향을 미쳤겠지만, 책 처음부터 나오는 예제가 DNA 처리와 관련된 내용이다.

처음에는 내가 책을 잘못 선택한 건 줄 알았다. 아무래도 컴퓨터 서적이다보니 뭔가 다른 주제를 다루더라도, 통계적 이해를 돕기위한 주제로 특이할 줄 알았는데, 책의 첫장부터 DNA내 염기서열의 분석을 어떤 방식으로 하는지에 대해서 설명한다. 좀 의아할 수 있는데, 이 책의 진행방식이 이런 거였다. 처음에 해당 분야에서 답을 구하는 방식에 대해서 언급하고, 그걸 scipy 패키지를 활용해서 해결하기 위한 방안을 소개하는 서술 구조로 되어 있는 것이다. 갑자기 DNA니, 염기서열이니 하는 말이 나와서 생뚱맞을 수도 있는데, 어쩌면 scipy를 "잘" 활용하는 방법을 설명하는 방법으로 좋은 접근이었던 것 같다. (사실 생뚱맞았다는 말이 나와서 그런데, 개인적으로 데이터 처리를 하는 입장에서도 해당 분야에 대한 어느정도의 domain knowledge가 필요한거 같다. 아무래도 그런 기반지식이 조금 갖춰져야 뭔가 처리를 하고 딥러닝이나 강화학습를 미지의 분야에 적용하고자 할때도 그만한 성과가 나오기 때문이다. 기반지식없이는 잘못된 결과가 나와도 이게 잘못된건지, 아니면 뭐가 부족한 건지를 파악하기가 매우 어렵다..)
그 외에도 좀 특이한 예제를 소개하자면 음성 데이터를 Fast Fourier Transform과 같은 후처리를 하는 과정에 대해서도 소개되어 있는데, 사실 나도 이런 음성처리 같은건 matlab에서 강점을 가지고 있었던 걸로 알았다. 그런데 이렇게 scipy내의 패키지를 활요해서 음성을 추출하고, 결과를 시각화하는 작업까지 할수 있는 것을 보니, 좀 신기하다는 생각이 들었다. 몰랐던 기능을 상기시켜주는 내용이랄까..
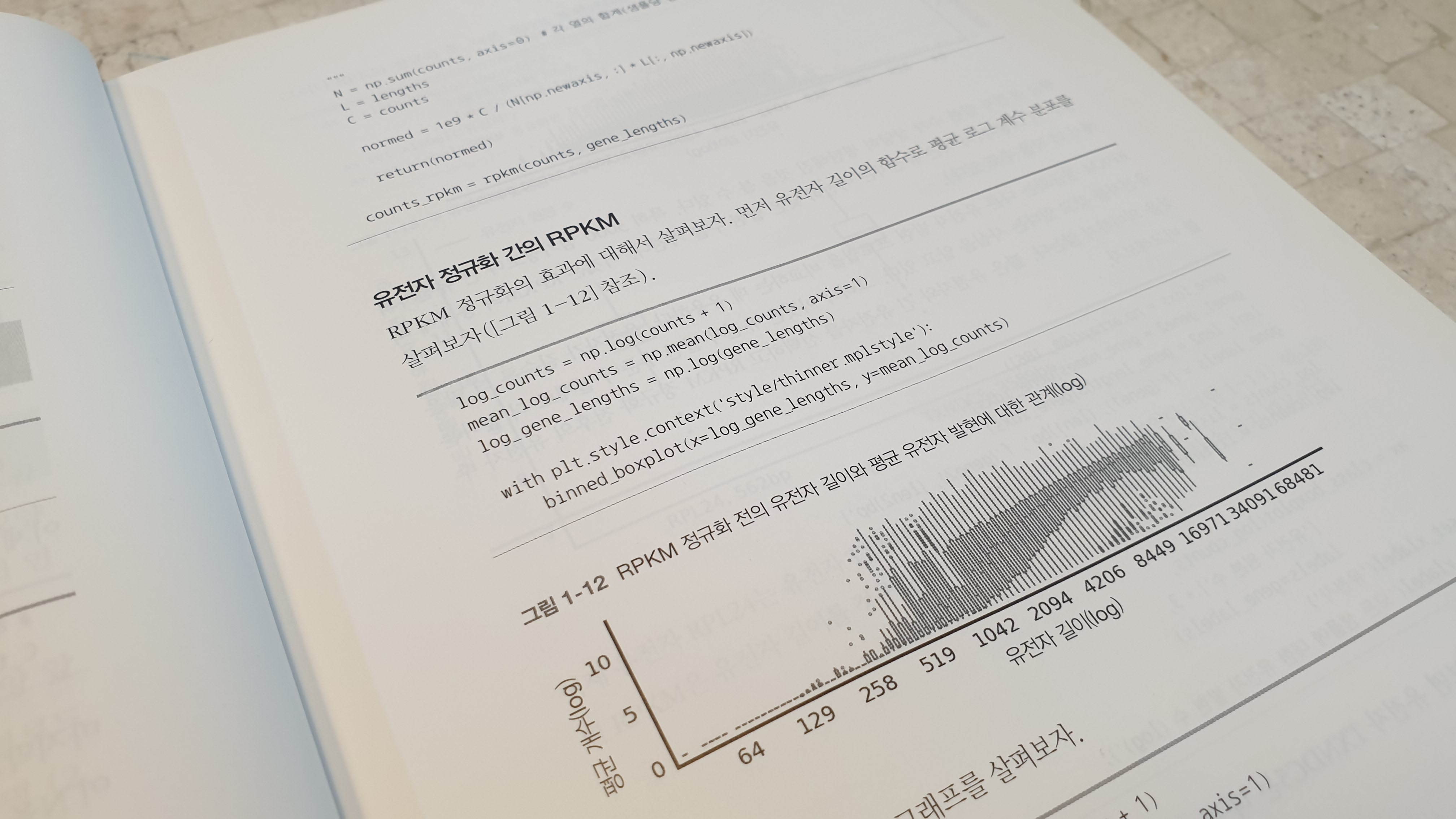
그런데 읽다보니 기타 데이터 분석 책과 비교했을 때 조금 아쉬운 점들도 눈에 띄였다. 우선 이 책의 범주를 굳이 나누자면 데이터 분석 관련책이라기 보다는 데이터 분석을 할 때 Scipy를 어떻게 활용할 수 있을까를 알려주는 설명서 같은 느낌이 들었다. 그러다보니 책을 읽고 나서도 뭔가 지식을 알게됬다기 보다는 이런 상황에서 scipy관련 API는 뭘쓰면 되겠구나 라는 테크닉을 알려주는 책이란 느낌이 좀 강했다. 그리고 추가로 책의 상당 부분이 코드로 되어있고, 이에 대한 설명이 조금 부족하다.(의도된 건지는 모르겠지만, 초반 코드에는 line by line 별로 주석이 잘 달려있지만, 후반부 코드에는 주석없이 본문 내용으로 기능을 유추해야 한다.) 물론 숙련자라면 이 책만큼이나 원하는 기능을 생소한 예제를 통해서 숙지할 수 있을 기회를 얻을 수 있는 심플한 책이 될 수도 있겠지만, 자칫 의도된 바와 다르게 이책은 그냥 scipy 패키지의 codebook 정도라고 느낄 여지가 조금 있는 것 같다.
그럼에도 이 책이 다른 데이터 분석 관련 책에 비해서 가지는 차별점은 앞에서 소개한 바와 같이 scipy를 활용하는 insight를 제공하는 거라고 생각한다. 뭔가 domain knowledge가 부족한 분야에서도 어떤 접근 방식이 필요하고, 그 방식을 실현하는데 scipy를 사용하는 방법을 묘사했다. 그래도 책의 내용이 다루는 주제 특성상 처음 scipy를 쓰는 사람보다는 어느정도 해당 패키지에 좀 익숙하고,그걸 좀 "우아"하게 써보고 싶은 사람한테는 조금이나마 도움이 될 책이지 않을까 싶다.
참고:
- 원서 github : https://github.com/elegant-scipy/elegant-scipy
- binder : https://mybinder.org/v2/gh/elegant-scipy/notebooks/master?filepath=index.ipynb
- 역자 github : https://github.com/AstinCHOI/elegant-scipy
( 참고로 위 github에 jupyter notebook으로 예제가 제공되기 때문에 해당 환경이 갖춰져있으면 책에 다뤄졌던 내용들을 바로 실습해볼 수 있다.)
- 포스트에서 언급되는 "우아한 사이파이" 는 한빛미디어에서 지원을 받았으며, 이에 대한 개인적인 느낌을 작성한 것임을 알려드립니다. -
출처: http://talkingaboutme.tistory.com/892 [자신에 대한 고찰]