처음 배우는 인공지능이라는 책 제목을 보고 매우 간단한 기초적인 내용을 다룰것이라고 생각을 했지만 처음 책의 목차를 펼쳐 보는순간 탄탄한 구성으로 내용을 이루었다고 생각을 했습니다. 이책은 총 14개의 챕터로 구성이 되어있습니다.
1장은 가볍게 인공지능이란 무엇인가? 라는 주제를 다루고 있습니다. 읽으면서 가장 와 닿는 문구가 하나 있었습니다. '어디까지가 패턴 인식 프로그램이고, 어디부터가 지능을 갖는 프로그램이라고 할 수 있을까?' 라는 문구였습니다. 이 책에서는 이 질문에 대해서 개발자의 관점에서 '사람처럼 행동하도록 만들어진 장치'라는 답변을 해주었습니다. 저 또한 이질문에 대해서 개발자 관점에서 생각을 했을때 사람처럼 행동하는 것이 아니라 ‘사람이 하기 귀찮아 하는 일을 대신 행동하도록 만들어진 장치'가 아닐까 하는 생각을 하였습니다.

과연 로봇도 사람처럼 사고가 가능한 시점이 언제올지 참 궁금합니다. 저는 그건 불가능하다고 생각을 하고있지만요 ㅎ
2장에서는 모델의 발전에 대한 주제에 대해서 다루고 있습니다. 여기서 모델이란 판단하는 방법을 의미합니다. 방법에 따라 여라가지 이름으로 불립니다. 규칙기반, 지식기반, 전문가 시스템, 추천 시스템에 대한 내용을 다루고 있습니다. 우리가 수학시간에 배운 순서도 그림, 스무고개 같은 트리기반 등 여러가지 방법에 대해서 소개합니다. 오늘날 많은 기업에서 추천 서비스를 사용하고 있는데 기본이 되는 내용을 다루고 있습니다. 간단한 예제를 통해서 수학에 익숙하지 않은 독자분들도 쉽게 이해를 할 수 있도록 구성이 되어있습니다.
3장에서는 오토마톤과 인공 생명 프로그램에 대한 주제에 대해서 다루고 있습니다. 게임을 통해서 내용을 쉽게 설명을 하여 전달을 하고 있습니다. 저 또한 게임에 비유를 좀더 쉽게 내용을 이해할 수 있었습니다. 이번장에서 인공지능이 스스로 학습할 수 있는 원리 중 반복 처리를 실행하면서 마치 살아 있는것처럼 상태를 변경해가는 내용을 다루고 있습니다. 이번장에서 수학적인 내용중 미분 방정식이 등장합니다. 미분 방정식은 학교를 다닐때 배웠던 내용인데 이것을 이런 책에서 다시보니 감회가 새로웠습니다
4장에서는 가중치와 최적해 탐색에 대한 주제를 다루고 있습니다. 이번장에서는 갑자기 많은 수학적인 내용이 등장하기 시작합니다. 4장을 들어가기 전에 심호흡을 한번 하고 들어가야 합니다. 가장 처음으로 나오는 것은 두 변수의 상관관계에 대해서 나옵니다 상관관계는 2장에서 추천 서비스를 설명하면서 등장을 했었기 때문에 어렵지 않게 읽어나갈 수 있을겁니다. 그외에도 선형, 비선형 계획법과 회귀분석, 가중 회귀분석에 대한 내용이 등장을 하고 마지막으로 비교대상에 대한 유사도를 측정하는 방법에 대해서 설명을 하게 됩니다. 이번장에서는 tensorflow를 이용화여 선형회귀 예제를 다루는 내용이 등장을 하게 됩니다. 수식은 매우 복잡하게 느껴질수도 있지만 막상 코드를 보면 이렇게 쉽게 풀수 있구나 하는 생각이 들겁니다. 또한 tensorflow를 이용하면 그래프를 그릴 수 있기때문에 수식만 봤을때보다 훨씬더 이해하기 쉬울것입니다.
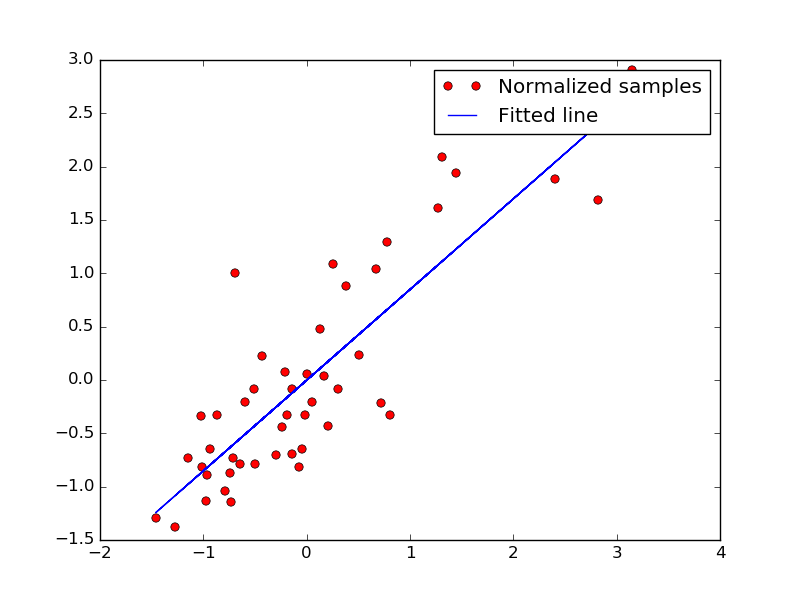
위 그래프는 실제 텐서플로우를 이용하여 그려진 그래프입니다. 이처럼 원하는데로 그래프를 그릴 수 있습니다.
5장에서는 가중치와 최적화 프로그램에 대한 주제를 다루게 됩니다. 신경망과 베이즈 네트워크에 기초가 되는 내용을 다루고 있습니다. 또한 유전자 알고리즘이라고 하는 최적화 시키는 방법을 다루고 있습니다. 유전자 알고리즘은 유튜브에 유전자 알고리즘을 검색을 해보시면 어떤식으로 작동이 되는지 알 수 있을겁니다.
해당 링크로 가시면 유전 알고리즘을 이용하여 만든 내용이 나타나게 됩니다. 유전자 알고리즘은 외부에서 입력값을 넣는게 아니라 스스로 입력값을 만들어 스스로 피드백을 받고 발전을 하여 최적의 해를 찾는 알고리즘입니다. 이번장에서 주로 다루는 자료구조는 그래프에 대한 내용입니다. 그래프의 행렬표현식, 그래프 탐색과 최적화를 다루고 있습니다. 그래프는 트리구조와 비슷한 형태로 생각을 하면 이해하기 쉽습니다. 탐색 트리를 이용하여 체스같은 턴제게임을 비유하여 설명 하고 있습니다. 이번장에서도 tensorflow를 이용하여 신경망을 구축하고 MNIST라는 손글씨 데이터를 대상으로 학습시킨 후 평가하는 코드를 작성을 하게 됩니다. '신경망을 이용한 머신러닝은 컴퓨터 자원을 많이 사용하므로 21세기 전에는 도입하는데 한계가 있었습니다'
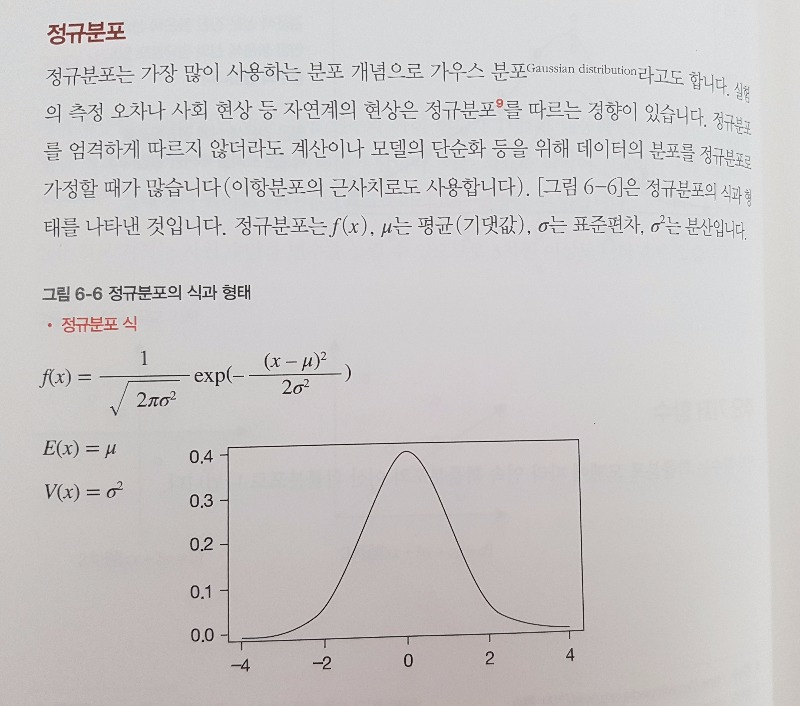
6장에서는 확률분포와 모델링에 대한 주제를 다루고 있습니다. 각종 확률분포, 베이즈 정리, 베이즈 추론, 마르코프 연쇄 몬테카틀로법을 설명합니다. 아 참고로 마르코프는 사람이름 입니다. 여기서 정규분포라는 용어가 등장 합니다. '이 세상의 모든것은 정규분포로 나타낸다'라는 말을 들어본적이 있습니다. 이것은 제가 회사에서 다른 개발자분과 일하면서 들었던 말입니다. 이 장에서는 이 책에서 처음으로 머신러닝이라는 용어가 등장을 하게 되는데 여기서 회귀분석이 머신러닝 및 신경망과 어떻게 연관이 되는지 보여줍니다. 6장은 확률에 대한 내용을 다루기 때문에 다양한 분포도를 소개합니다. 아마 확률, 통계의 개념이 많이 부족하다면 조금 어렵게 느껴질 수 있습니다.
7장에서는 자율학습과 지도학습에 대한 주제를 다루고 있습니다. 자율학습은 계산을 반복하면서 가중치 계수를 업데이트하는 방법입니다. 여기서 포인트는 정답 정보가 없는 상태에서 학습을 통해 모델을 만들어 냅니다. 이것을 데이터 마이닝이라고도 합니다. 반대로 정답 정보가 들어 있는 데이터를 기준으로 모델을 만드는 지도 학습에 대한 내용도 다루고 있습니다. 나이브 베이즈 정리가 바로 지도학습에 해당합니다. 이번장에서는 tensorflow를 이용하여 k-mean에 대해서 코드를 작성을 하는 예제가 나옵니다. tensorflow뿐 아니라 pandas라는 데이터 프레임 워크를 사용하는 방법에 대해서 나타납니다.
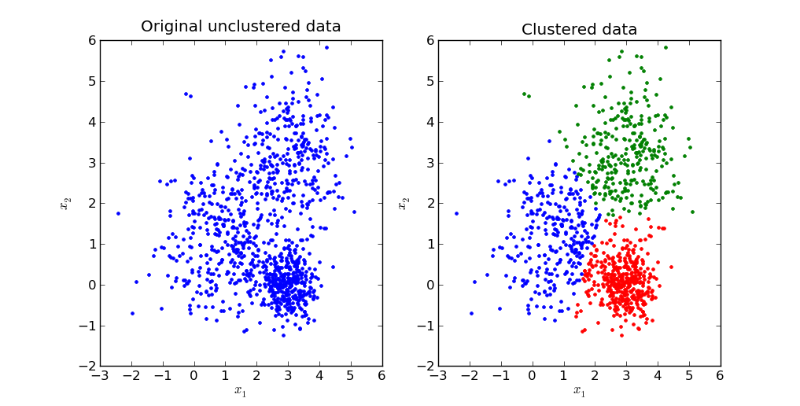
위 그래프틑 k-mean를 이용하여 군집화 결과를 나타낸 결과입니다. k-mean를 이용하여 클러스터링을 시키고나니 그래프가 그럴듯 해보이네요. 당장 앞에 나가서 피티 발표를 해보고 싶어집니다.
8장은 강화학습과 분산 인공지능에 대한 내용을 다루고 있습니다. 학습기를 생성하는 방법, 프로그램이 외부와의 상호작용을 일으키는 환경에서 피드백을 받으면서 자율적으로 학습하는 강화학습, 전이 학습을 설명합니다. 이번장을 읽으면서 가장 와닿는 문구는 ‘학습 방법을 학습한다’였습니다. 이를 메타학습이라고 하는데 이것이 진정한 인공지능이지 않나 싶었습니다.
9장은 딥러닝에 대한 내용을 다루고 있습니다. 딥러닝은 신경망을 이용한 개념인데 [처음 배우는 인공지능] 책에서는 합성곱 신경망(CNN)과 순환 신경망(RNN)에 대해서 다루고 있습니다. NN이 붙는 알고리즘은 신경망에 대한 알고리즘 입니다. 이번장에서도 tensorflow를 이용하여 오토인코더, 합성곱 신경망을 다루는 예제가 등장하게 됩니다.
10장은 이미지와 음성 패턴 인식에 대한 내용을 다루고 있습니다. 이미지와 음성 패턴인식은 머신러닝을 이용한 패턴 인식의 대표적인 사례입니다. [처음 배우는 인공지능] 책에서는 해석학 측면으로 접근하는 고전적인 머신러닝 방법과 최근 주목받는 딥러닝을 이용한 방법을 설명하며 스타일 변환 등 응용 사례도 간단히 설명하고 있습니다. 또한 고전적인 머신러닝을 이용하는 것보다 딥러닝을 이용하는 것이 어려운 이유도 설명을 하고 있습니다. 이번장에서는 딥러닝이 무조건 적으로 최고의 방법이 아니라는 것을 설명해주고 있습니다. 수학적인 측면에서 푸리에 변화의 공식이 등장을 하게 됩니다. 대학교 공업수학에서 다루는 내용인데 제가 공학수학을 공부 하면서 가장 좋아했던 부분이라서 그런지 이번장을 가장 재밌게 읽었던것 같습니다. 이번장에서도 tensorflow로 GAN을 구현하는 예제가 등장 합니다.
이 그래프를 보니 학교에서 수업 들을때가 생각이 나네요
11장은 자연어 처리와 머신러닝에 대한 내용을 다루고 있습니다. 여기서는 사람이 평소 대화와 메시지 등에서 사용하는 단어에 대해서 학습을 하고 학습된 결과를 바탕으로 텍스트를 생성을 하는 알고리즘에 대한 내용을 다루고 있습니다. 요즘 많이 서비스화 되고있는 챗봇이 바로 여기에 해당합니다. 추가적으로 인공지능을 이용하여 음악생성, 소설집필과 같은 분야에 대한 내용도 함께 다루고 있습니다. 자연어 처리는 우리가 하는 말, 메시지로 부터 형태소를 쪼개어 빈도수 체크, 상관 관계를 분석하여 vector 형태로 표시를 하여 단어마다 연관 관계를 나타내는 방법을 사용합니다.
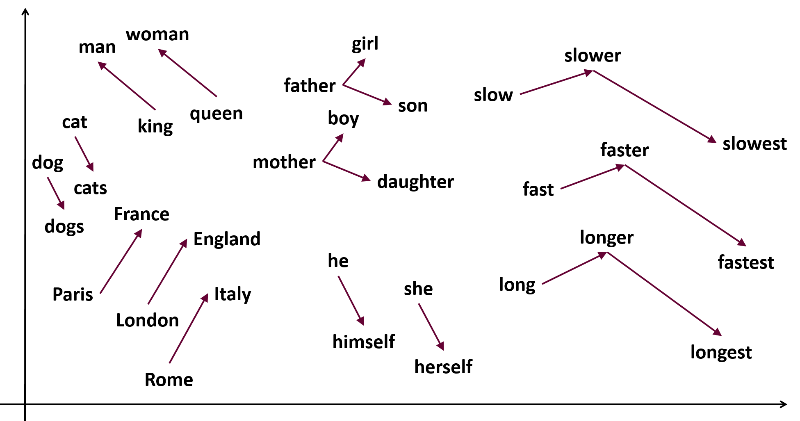
해당 이미지는 word2vec이라는 알고리즘을 이용하여 단어들을 vector 형태로 나타낸 그래프 입니다. 단어를 그래프화 시키는건 정말 멋진 아이디어인것 같습니다. 그래프화가 되었다는건 선형계산이 가능함을 의미합니다. 즉 +,-, *, /이 가능해집니다.
12장은 지식 표현과 데이터 구조에 대한 내용을 다루고 있습니다. 이번장에서는 지식 기반을 사용하는 시스템의 데이터와 머신러닝으로 얻은 학습기의 상태(특징량)를 영구적으로 사용하려면 외부 스토리지에 저장할 필요가 있는데 저장이라는 관점에서 주된 내용을 다루고 있습니다. 또한 각 저장소마다의 특징에 대한 설명을 자세히 해주고 있습니다. 바로 우리가 흔히 불러온 DB라는 주제입니다. 데이터 베이스의 종류는 상당히 많습니다. 하지만 모든 데이터 베이스를 사용하는 것이 아닌 우리가 사용하고 있는 서비스, 시스템에 맞추어 선택을 해서 사용을 하게 되는데 이것을 선택을 하기 위해서는 데이터의 성격을 파악후 그 성격에 맞는 데이터 베이스를 선택을 해야 합니다. 예를 들면 은행처럼 transaction이 중요한 시스템에서는 주로 관계형 디비를 많이 사용합니다. 하지만 빅 데이터를 처리하기 위해서는 I/O의 시간을 줄이기 위해 또한 데이터의 모델을 정의 하기 힘들경우 NoSQL이라고 하는 데이터 베이스를 선택을 하고 NoSQL에서도 다양한 디비가 존재하는데 데이터의 성격에 따라 선택을 하게 됩니다. 이 책에서는 데이터 베이스를 선택을 하기 위해 어떤 것을 중점적으로 봐야하는지 설명이 잘 되어있습니다. 디비 특성 이외의 데이터를 불러오는 방법에 대해서도 설명을 하고 있습니다.
저도 전 회사에서 데이터를 다루면서 참 많은 디비를 다뤄보았지만, 어떤 디비는 설치하면 바로 쓸수 있지만 또 다른 디비는 셋팅하는데만 몇날 몇칠이 걸리는 경우도 있습니다. ㅎ 이번 장을 읽으면서 전에 디비셋팅을 하던기억이 떠오르더군요
13장은 분산 컴퓨팅에 대한 내용을 다루고 있습니다. 물리적으로 컴퓨터를 늘려 네트워크로 연결을 하여 분산처리를 할지, 하나의 하드웨어에서 여러 프로세스를 띄워 처리를 하는 병렬처리에 대한 내용을 다루고 있습니다. 또한 이런것들을 물리적으로 직접 만들지 않고 클라우드 환경에서 사용이 가능하도록 하는 서비스 환경을 머신러닝 개발, 딥러닝 개발에 이용하는 주요 환경을 나누어 소개를 하고 있습니다. 머신러닝 개발환경 제공 서비스인 구글 클라우드 플랫폼, 마이크로소프트 애저 머신러닝, 아마존 머신러닝, IBM 블루믹스, IBM 왓슨에 대해서 설명하고 있습니다. 다음으로 딥러닝 개발환경 제공 서비스인 카페, 테아노, 체이너, 텐서플로, MXNet, 케라스에 대해서 설명하고 있습니다.
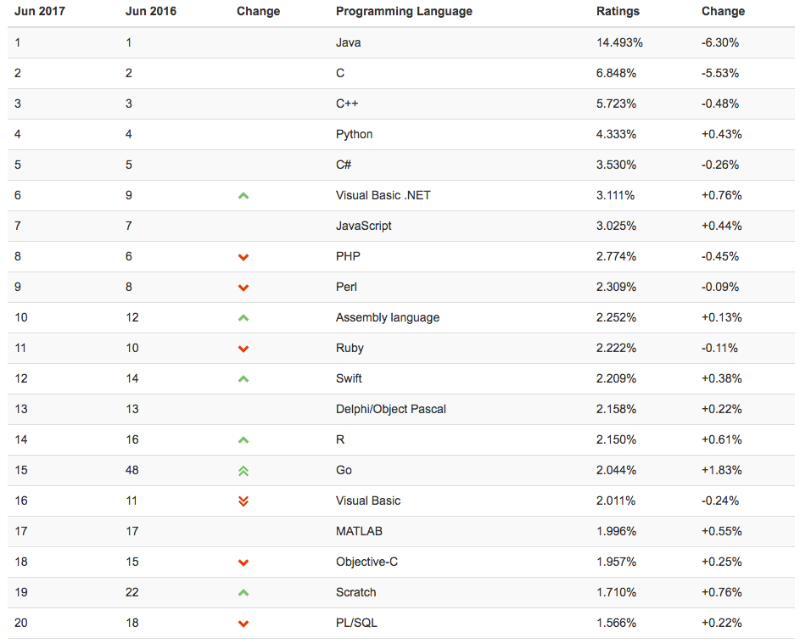
해당 이미지는 2017년 6월 기준 머신러닝과 딥러닝 개발을 위해 사용되는 프로그래밍 언어 순위표입니다. 저는 python과 javascript가 주력언어이면서 c와 c++도 어느정도 다룰줄은 압니다. 요즘은 php도 다뤄야 하는 상황이 생겨서 php 기반의 소스 분석을 하고 있습니다. 어셈블리가 10위 있는건 좀랍더군요
14장은 빅데이터와 사물인터넷의 관계에 대한 내용을 다루고 있습니다. 여기서는 다양한 클라우드 서비스에서 제공하는 저장소 S3, Cloud Strage, 애저, 불루믹스에 대한 소개를 합니다. 다음으로 IOT 제품을 만들기 위한 보드 요즘 가장 많이 각광맏고 있는 Raspberry Pi, Arduino 보드가 등장을 하고 그 외에도 intel Edition, ESP-WROOM-02, GR-PEACH, HiKey board가 등장을 합니다. 어떤 방향으로 사물 인터넷을 만들어 사용을 하는지 다양한 분양에 대해서도 설명을 하고 있습니다.
요즘은 다양한 기기가 나옴으로써 생활이 편리해지고 있습니다. 다양한 보드가 나오면서 많은 사람들이 쉽게 iot에 접근을 할 수 있습니다. 저 또한 학교를 다니면서 아두이노, 라즈베리파이 같은 보드를 이용하여 이런 저런것들을 만들어 보기도 하였는데요. 세상이 점점 더 빠르게 변화를 하는것 같습니다.
이 책의 가장 좋다고 생각한 이유는 알고리즘만 중점적으로 설명하는 것이 아닌 알고리즘의 변천과정, 알고리즘의 사용목적, 어디에 사용을 하는지에 대해서 자세히 설명이 되어있습니다. 우리가 자료구조처럼 스택, 큐, 그래프를 공부할때 많은 사람들이 이러한 자료구조는 왜 공부를 하지?라는 의문을 가진사람을 많이 만나봤는데, 머신러닝또한 이러한 알고리즘을 익혀도 어디에 어떻게 사용하지라는 질문을 많이 받아왔습니다. 하지만 이 책은 머신러닝, 딥러닝 알고리즘 뿐 아니라 변천과정부터 어디에 어떻게 사용을 하는것이 좋은지에 대해서도 설명이 잘 되어 있습니다. 또한 이러한 알고리즘을 사용하기 위한 플랫폼, 서비스, 라이브러리들에 대해서도 설명을 하고 있어서 다양한 관점을 가지고 접근을 할 수있습니다.