이책은 CNN, 강화학습, 몬테카를로 탐색 기술을 활용하여 인공지능 기반의 바둑봇인 알파고를 만들수 있도록 도와준다.
Random 봇이라는 저급의 바둑 봇에서 시작하여 다양한 탐색기술을 적용, 바둑 기보에서의 신경망 학습을 통한 기력 향상, 강화학습을 통해 수를 읽고 바둑 형세를 읽는 법을 학습하여 , 마침내는 인간 바둑 고수의 고난이도 바둑 기술을 학습하여, 최고수의 경지에 이르는 인공지능 바둑봇을 개발하기 위한 전반적인 인공지능 기법을 소개하고 있다.
강화학습과 관련하여 DQN 과 Actor-Critic 기술을 활용하고 있으며, 실제 구현 예제를 살펴보는 일은 흥미진진하다.
최신 CNN망과 강화학습을 응용한다면, 알파고보다 뛰어난 바둑봇을 구현할수 있으리라 기대한다.


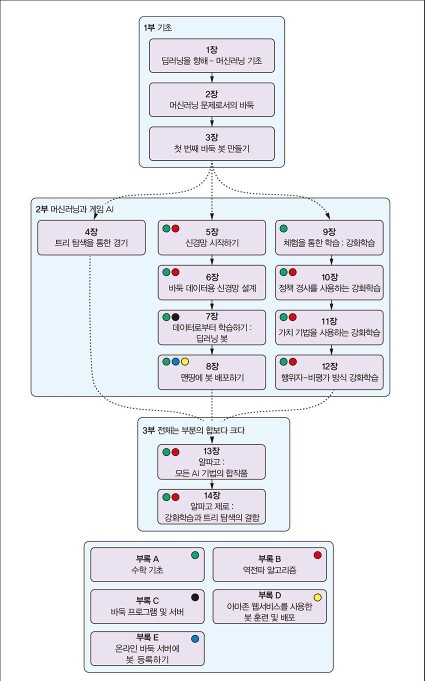
다음은 이책의 목차이다.
CHAPTER 1 딥러닝을 향해 - 머신러닝 기초
1.1 머신러닝이란 무엇인가
__1.1.1 머신러닝은 AI와 어떤 연관성이 있는가
__1.1.2 머신러닝으로 할 수 있는 것과 할 수 없는 것
1.2 사례로 보는 머신러닝
__1.2.1 애플리케이션에서 머신러닝 사용
__1.2.2 지도학습
__1.2.3 비지도학습
__1.2.4 강화학습
1.3 딥러닝
1.4 이 책에서 학습할 내용
1.5 요약
CHAPTER 2 머신러닝 문제로서의 바둑
2.1 왜 게임인가
2.2 간단한 바둑 소개
__2.2.1 바둑판 이해하기
__2.2.2 돌 놓기와 잡기
__2.2.3 경기 종료 및 점수 계산
__2.2.4 패 이해하기
2.3 접바둑
2.4 추가 학습 자료
2.5 머신에 무엇을 가르칠 수 있을까
__2.5.1 포석 두기
__2.5.2 다음 수 찾기
__2.5.3 고려할 수 줄이기
__2.5.4 게임 현황 평가하기
2.6 바둑 AI가 얼마나 강력한지 측정하는 방법
__2.6.1 일반 바둑 등급
__2.6.2 바둑 AI 벤치마킹
2.7 요약
CHAPTER 3 첫 번째 바둑봇 만들기
3.1 파이썬으로 바둑 나타내기
__3.1.1 바둑판 구현하기
__3.1.2 바둑에서 연결 추적하기 : 이음
__3.1.3 바둑판에 돌 놓기와 따내기
3.2 대국 현황 기록과 반칙수 확인
__3.2.1 자충수
__3.2.2 패
3.3 게임 종료
3.4 첫 번째 봇 만들기 : 상상 가능한 최약체 바둑 AI
3.5 조브리스트 해싱을 사용한 대국 속도 향상
3.6 봇과 대국하기
3.7 요약
[Part 2 머신러닝과 게임 AI]
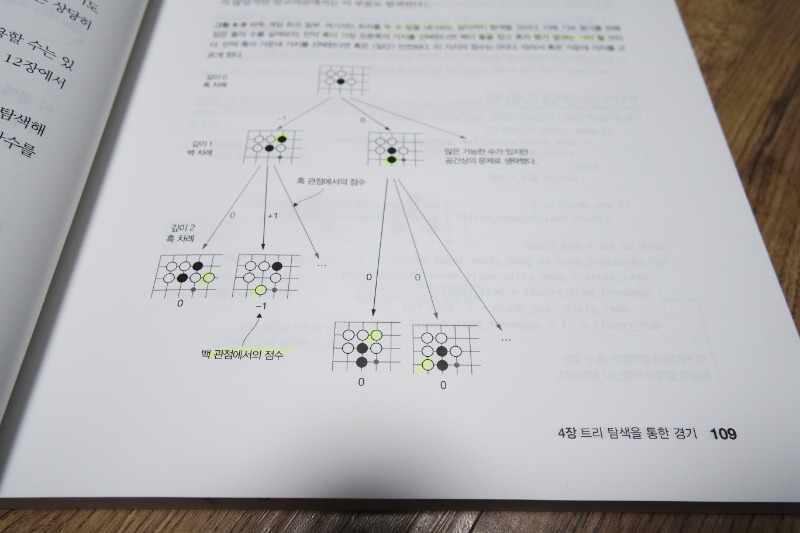
CHAPTER 4 트리 탐색을 통한 경기
4.1 게임 분류
4.2 미니맥스 탐색을 사용한 상대 수 예측
4.3 틱택토 풀기 : 미니맥스 예제
4.4 가지치기를 통한 탐색 공간 축소
__4.4.1 위치 평가를 통한 탐색 깊이 축소
__4.4.2 알파-베타 가지치기를 사용해서 탐색 폭 줄이기
4.5 몬테카를로 트리 탐색을 이용한 경기 상태 평가
__4.5.1 파이썬으로 몬테카를로 트리 탐색 구현하기
__4.5.2 탐색할 가지 선택법
__4.5.3 바둑에 몬테카를로 트리 탐색 적용하기
4.6 요약
CHAPTER 5 신경망 시작하기
5.1 간단한 사례 : 손글씨 숫자 분류
__5.1.1 MNIST 숫자 손글씨 데이터셋
__5.1.2 MNIST 데이터 처리
5.2 신경망 기초
__5.2.1 단순한 인공 신경망으로의 로지스틱 회귀
__5.2.2 1차원 이상의 결과를 갖는 신경망
5.3 순방향 신경망
5.4 우리 예측은 얼마나 훌륭한가 : 손실 함수와 최적화
__5.4.1 손실 함수란 무엇인가
__5.4.2 평균제곱오차
__5.4.3 손실 함수에서의 최솟값 찾기
__5.4.4 최솟값을 찾는 경사하강법
__5.4.5 손실 함수에서의 확률적 경사하강법
__5.4.6 신경망에 기울기를 역으로 전파하기
5.5 파이썬을 활용한 단계별 신경망 훈련
__5.5.1 파이썬에서의 신경망층
__5.5.2 신경망에서의 활성화층
__5.5.3 순방향 신경망의 구성 요소로서의 파이썬에서의 밀집층
__5.5.4 파이썬으로 순차 신경망 만들기
__5.5.5 신경망으로 손글씨 숫자 분류하기
5.6 요약
CHAPTER 6 바둑 데이터용 신경망 설계
6.1 신경망용 바둑경기 변환
6.2 트리 탐색 게임을 신경망 훈련 데이터로 만들기
6.3 케라스 딥러닝 라이브러리 사용하기
__6.3.1 케라스 디자인 원리 이해
__6.3.2 케라스 딥러닝 라이브러리 설치
__6.3.3 케라스로 익숙한 첫 번째 문제 실행해보기
__6.3.4 케라스에서 순방향 신경망을 사용한 바둑 수 예측
6.4 합성곱 신경망으로 공간 분석하기
__6.4.1 합성곱 역할에 대한 직관적 이해
__6.4.2 케라스로 합성곱 신경망 만들기
__6.4.3 풀링층을 사용한 공간 감소
6.5 바둑 수 확률 예측하기
__6.5.1 마지막 층에서 소프트맥스 활성화 함수 사용
__6.5.2 분류 문제에서의 교차 엔트로피 손실
6.6 드롭아웃과 정류 선형 유닛을 사용해 더 깊은 신경망 구성
__6.6.1 표준화를 위해 일부 뉴런 제거하기
__6.6.2 ReLU 활성화 함수
6.7 기능 결합을 통해 더 강력한 바둑 수 예측 신경망 만들기
6.8 요약
CHAPTER 7 데이터로부터 학습하기 : 딥러닝 봇
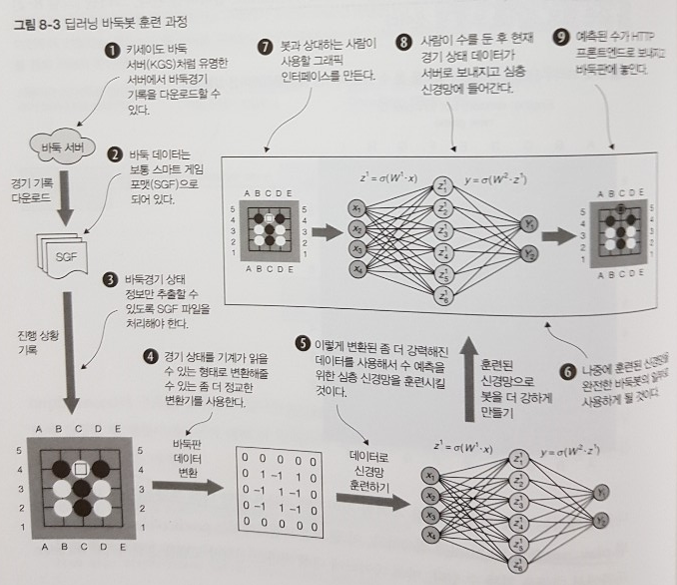
7.1 바둑 대국 기록 가져오기
__7.1.1 SGF 파일 포맷
__7.1.2 KGS에서 바둑 대국 기록을 다운로드해서 재현하기
7.2 딥러닝용 바둑 데이터 준비
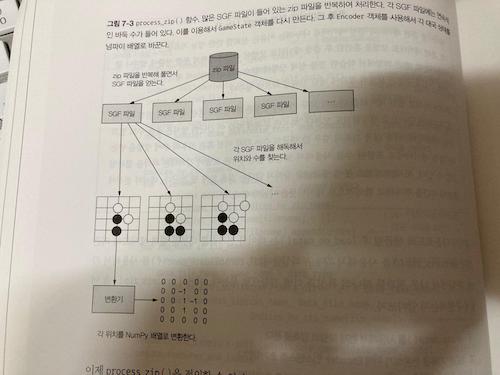
__7.2.1 SGF 기록을 사용해서 바둑 대국 재현하기
__7.2.2 바둑 데이터 전처리기 만들기
__7.2.3 데이터를 효율적으로 불러오는 바둑 데이터 생성기 만들기
__7.2.4 바둑 데이터 처리 및 생성기의 병렬 실행
7.3 인간의 대국 기록으로 딥러닝 모델 훈련하기
7.4 더 실질적인 바둑 데이터 변환기 만들기
7.5 적응 경사법을 사용해서 효율적으로 훈련하기
__7.5.1 SGD에서의 붕괴와 모멘텀
__7.5.2 에이다그래드로 신경망 최적화하기
__7.5.3 에이다델타로 적응 경사법 조정하기
7.6 직접 실험하고 성능 평가하기
__7.6.1 모델 구조 및 하이퍼파라미터 검정 지침
__7.6.2 훈련 및 검정 데이터로 성능 지표 평가하기
7.7 요약
CHAPTER 8 맨땅에 봇 배포하기
8.1 심층 신경망으로 수 예측 에이전트 만들기
8.2 바둑봇을 웹 프론트엔드로 제공하기
__8.2.1 바둑봇 예제 처음부터 끝까지 다루기
8.3 클라우드에서 바둑봇 훈련 후 배포하기
8.4 다른 봇과의 대화에 사용할 바둑 텍스트 프로토콜
8.5 로컬에서 다른 봇과 대결하기
__8.5.1 봇이 차례를 넘기거나 기권해야 할 때
__8.5.2 봇과 다른 바둑 프로그램 간 대국 두기
8.6 바둑봇을 온라인 바둑 서버에 배포하기
__8.6.1 온라인 바둑 서버에 봇 등록하기
8.7 요약
CHAPTER 9 체험을 통한 학습 : 강화학습
9.1 강화학습 주기
9.2 경험을 통해 어떻게 달라질까
9.3 학습 가능한 에이전트 만들기
__9.3.1 확률분포에 따른 샘플링
__9.3.2 확률분포 제한
__9.3.3 에이전트 초기화
__9.3.4 물리 장치로부터 에이전트 불러오고 저장하기
__9.3.5 수 선택 구현
9.4 자체 대국 : 컴퓨터 프로그램이 연습하는 방법
__9.4.1 경험 데이터 나타내기
__9.4.2 대국 시뮬레이션
9.5 요약
CHAPTER 10 정책 경사를 사용하는 강화학습
10.1 임의의 경기에서 좋은 결정을 정의하는 방법
10.2 경사하강법을 사용해서 신경망 정책 수정하기
10.3 자체 대국 훈련 팁
__10.3.1 성능 향상 평가하기
__10.3.2 작은 성능 차이 측정하기
__10.3.3 확률적 경사하강(SGD) 최적화기
10.4 요약
CHAPTER 11 가치 기법을 사용하는 강화학습
11.1 Q-학습을 사용한 대국
11.2 케라스로 Q-학습 만들기
__11.2.1 케라스로 입력값이 둘인 신경망 만들기
__11.2.2 케라스로 ε-탐욕 정책 구현하기
__11.2.3 행동-가치 함수 훈련
11.3 요약
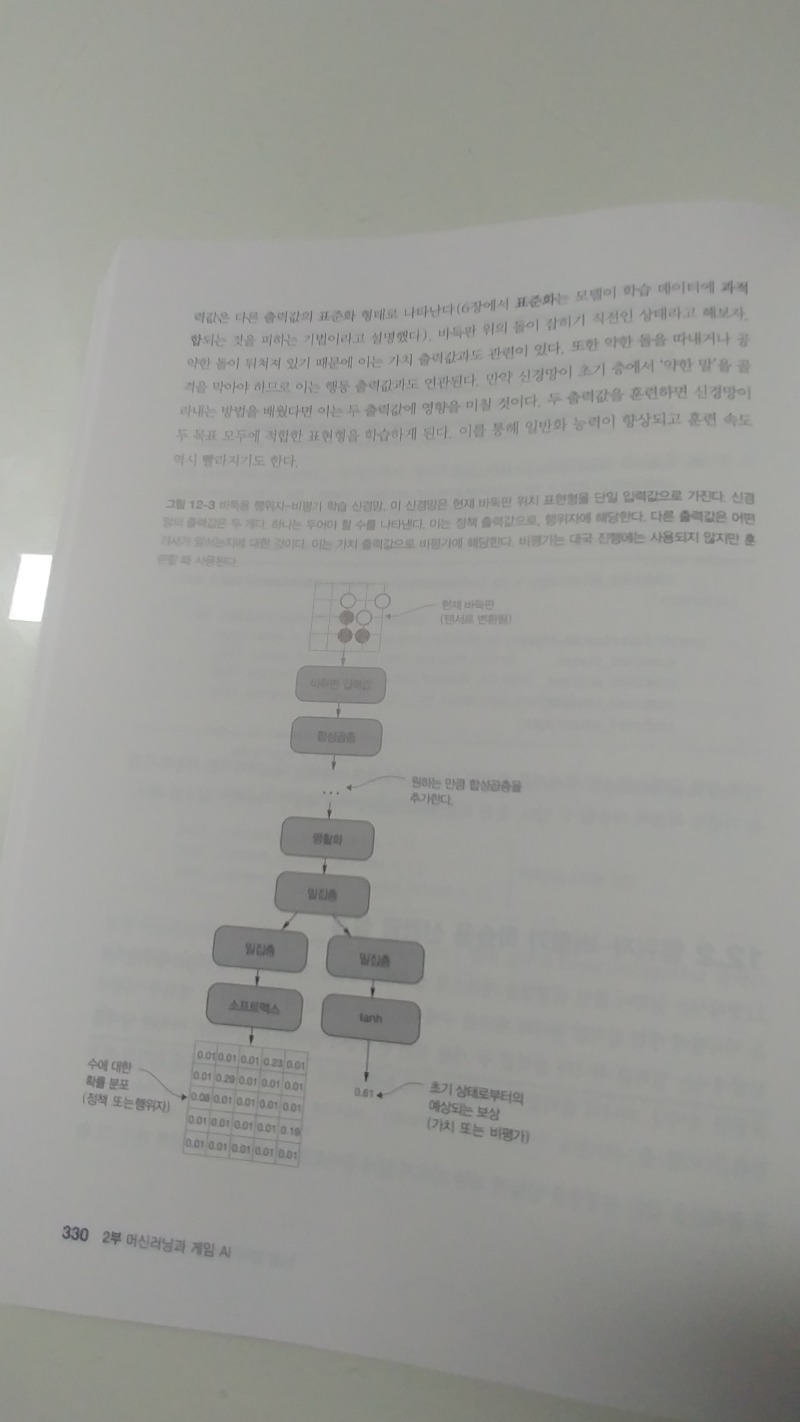
CHAPTER 12 행위자-비평가 방식 강화학습
12.1 어느 결정이 중요한지는 어드밴티지가 알려준다
__12.1.1 어드밴티지란 무엇인가
__12.1.2 자체 대국 중에 어드밴티지 구하기
12.2 행위자-비평가 학습용 신경망 설계
12.3 행위자-비평가 에이전트를 사용한 대국
12.4 경험 데이터로 행위자-비평가 에이전트 훈련하기
12.5 요약
[Part 3 전체는 부분의 합보다 크다]
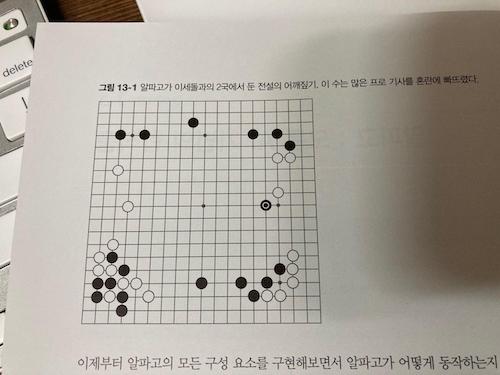
CHAPTER 13 알파고 : 모든 AI 기법의 합작품
13.1 알파고의 신경망 훈련
__13.1.1 알파고의 신경망 구조
__13.1.2 알파고 바둑판 변환기
__13.1.3 알파고 스타일의 정책 신경망 훈련하기
13.2 정책 신경망으로 자체 대국 부트스트래핑
13.3 자체 대국 데이터로 가치 신경망 도출하기
13.4 정책 신경망과 가치 신경망을 사용한 탐색 개선
__13.4.1 신경망으로 몬테카를로 롤아웃 개선하기
__13.4.2 결합 가치 함수를 사용한 트리 탐색
__13.4.3 알파고의 탐색 알고리즘 구현
13.5 각자의 알파고를 훈련할 때 실제로 고민해야 할 부분
13.6 요약
CHAPTER 14 알파고 제로 : 강화학습과 트리 탐색의 결합
14.1 트리 탐색용 신경망 만들기
14.2 신경망으로 트리 탐색 안내하기
__14.2.1 트리 따라 내려가기
__14.2.2 트리 확장
__14.2.3 수 선택
14.3 훈련
14.4 디리클레 잡음을 사용한 탐색 향상
14.5 더 깊은 신경망을 만드는 현대적 기법
__14.5.1 배치 정규화
__14.5.2 잔차 신경망
14.6 추가 참고 자료
14.7 정리
14.8 요약
부록 A 수학 기초
부록 B 역전파 알고리즘
부록 C 바둑 프로그램 및 서버
부록 D 아마존 웹서비스를 사용한 봇 훈련 및 배포
부록 E 온라인 바둑 서버에 봇 등록하기