러스트의 타입 시스템은 다른 주류 언어보다 훨씬 표현력이 뛰어나며 오캐멀 OCaml이나 하스켈 Haskell과 같은 학술 연구용 언어와 비슷한 점이 많다. 러스트 타입 시스템의 핵심 중 하나인 enum(이넘, 열거형) 타입은 다른 언어보다 표현력이 훨씬 뛰어나며, 대수적 데이터 타입 algebraic data type (ADT)도 지원한다.
이번에는 러스트의 타입 시스템을 간략히 소개하고자 한다. 먼저 컴파일러에서 기본으로 제공하는 타입부터 살펴본 후, 이를 조합해 다양한 방식으로 복잡한 데이터 구조를 구성하는 방법을 설명한다.
이 과정에서 러스트의 enum 타입은 핵심적인 역할을 한다. 기본은 다른 언어와 같지만(struct처럼) enum 배리언트 variant 에 데이터 필드를 직접 넣을 수 있다는 점에서 다른 언어보다 훨씬 유연하고 표현력이 높다.
C++이나 고 Go , 자바 Java 와 같은 정적 프로그래밍 언어에 익숙하다면, 러스트의 타입 시스템에 대한 기본적인 내용은 쉽게 이해할 수 있다. 가령, 러스트에서도 다양한 크기로 부호 있는 정수 타입 (i8, i16, i32, i64, i128)과 부호 없는 정수 타입(u8, u16, u32, u64, u128)을 제공한다.
또한 부호 있는 정수 타입(isize)과 부호 없는 정수 타입(usize)도 제공한다. 이런 타입은 타깃 시스템의 포인터 크기에 맞게 제공되지만 러스트에서는 포인터 타입과 정수 타입을 서로 변환할 일이 많지 않아서 큰 의미는 없다. 그보다는 표준 컬렉션이 크기를 (.len()을 통해) usize로 반환하기 때문에, 컬렉션에 담긴 항목에 대한 인덱스를 표현하는 데 usize 값을 자주 사용한다. 이렇게 해도 메모리에 있는 컬렉션의 항목 수가 시스템 메모리의 주소 공간보다 많을 수 없기 때문에 용량 문제는 발생하지 않는다.
정수 타입만 봐도 러스트가 C++보다 훨씬 엄격하다는 것을 알 수 있다. 러스트에서는 다음과 같이 큰 정수 타입(i32)을 작은 정수 타입(i16)에 넣으려고 하면 컴파일 오류가 발생한다.

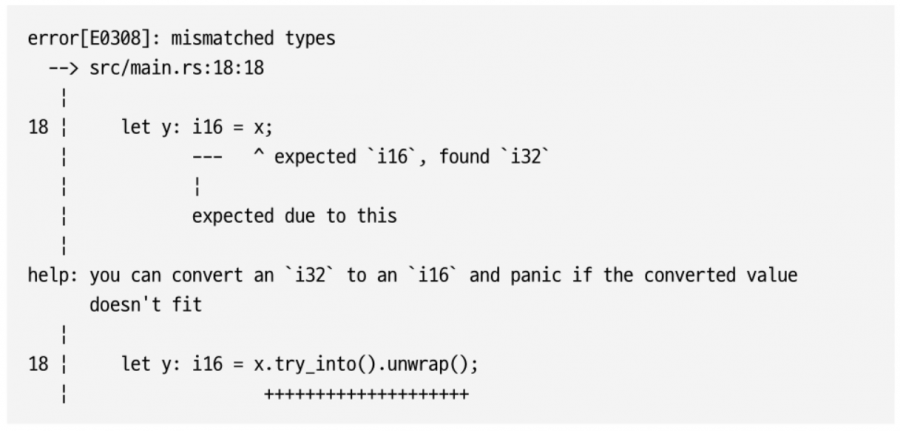
참 든든하다. 러스트에서는 프로그래머가 위험한 행동을 할 수 없다. 방금 본 코드처럼 값을 변환해도 실제로 문제가 되지 않지만, 컴파일러 입장에서는 문제의 여지를 조금이라도 주지 않기 위해 오류로 처리한다.

출력된 오류 메시지만 봐도 러스트에서는 규칙을 훨씬 엄격하게 적용하며, 올바른 작성 방법도 친절히 설명해 주는 것을 알 수 있다. 변환할 값의 크기가 맞지 않을 때 오류 메시지의 제안처럼 구현하는 구체적인 방법은 『이펙티브 러스트』에서 확인할 수 있다.
러스트는 작은 정수 타입 값을 큰 정수 타입에 넣는 것처럼 ‘안전해 보이는’ 작업도 허용하지 않는다.

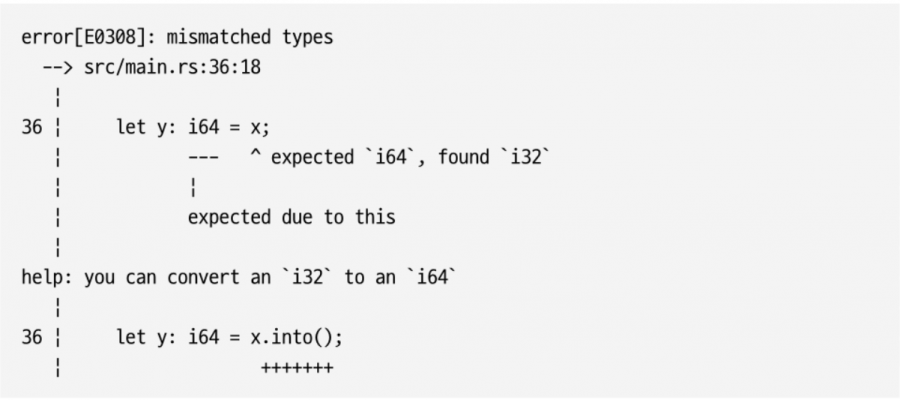
여기서 컴파일러가 제시한 해결법을 보면 오류 처리까지는 하지 않더라도 타입만큼은 명시적으로 변환해야 한다. 그 밖에도 러스트는 bool 타입, 부동 소수점 타입(f32, f64), C의 void와 같은 유닛 unit 타입인 ()도 제공한다.
러스트의 문자 타입(char)은 더 특이하다. 이 타입은 고 언어의 룬 rune 타입처럼 유니코드 값을 갖는데, 내부적으로 4바이트로 표현됨에도 불구하고, 32비트 정수와의 암묵적인 변환은 허용하지 않는다.
이처럼 러스트의 타입 시스템은 엄격하기 때문에 항상 대상을 명확히 표현해야 한다. u32 값은 char와는 엄연히 다르고, char는 UTF-8 바이트 시퀀스 sequence 와 다르며, UTF-8 바이트 시퀀스는 임의 타입의 바이트 시퀀스와 다르다. 따라서 자신이 표현하려는 대상을 구체적으로 명시해야 한다. 이와 관련해 조엘 스폴스키 Joel Spolsky 의 유명한 블로그 게시물을 참고하면 도움이 된다.
물론 다양한 타입 사이의 변환을 도와주는 헬퍼 helper 메서드가 있지만, 실패할 가능성을 처리하 든지 아니면 명시적으로 무시하도록 시그니처가 정의돼 있다. 예를 들어 유니코드 코드 포인트는 항상 32비트로 표현되므로, 6 'a'를 u32로 표현할 수는 있지만, 그 반대로 하기에는 쉽지 않다. u32 값이 모두 올바른 유니코드 코드 포인트가 아니기 때문이다.
이번에는 여러 값을 묶을 수 있는 묶음 타입 aggregate type 에 대해 알아보자. 러스트의 묶음 타입은 다른 언어와 비슷하다.
러스트에는 구조체와 튜플을 혼합한 튜플 구조체 tuple struct 도 있다. 튜플 구조체는 구조체 전체에 대해서는 이름을 붙일 수 있지만, 개별 필드에는 이름이 없고 s.0, s.1 등과 같은 숫자로 표현 한다.
/// 이름 없는 필드 두 개로 구성된 구조체
struct TextMatch(usize, String);
// 내용을 순서대로 제공하도록 만든다.
let m = TextMatch(12, "needle".to_owned());
// 필드 번호로 접근한다.
assert_eq!(m.0, 12);
러스트 타입 시스템에서 핵심적인 역할을 하는 enum (이넘, 열거형)에 대해 알아보자. enum의기본 형태만 보면 그리 특별하지 않다. 다른 언어와 마찬가지로 러스트의 enum도 각 원소마다 숫자를 할당해 상호 배타적인 값으로 구성된 집합을 정의할 수 있다.
enum HttpResultCode {
Ok = 200,
NotFound = 404,
Teapot = 418,
}
let code = HttpResultCode::NotFound;
assert_eq!(code as i32, 404);
각 enum 정의마다 타입이 별도로 생성되므로 단순히 bool 타입 인수를 받도록 정의할 때보다 가독성과 유지 보수성을 높일 수 있다. 예를 들어 다음 코드를 살펴보자.
print_page(/* both_sides= */ true, /* color= */ false);
이 코드를 다음처럼 enum 타입 한 쌍으로 정의할 수 있다.
pub enum Sides {
Both,
Single,
}
pub enum Output {
BlackAndWhite,
Color,
}
pub fn print_page(sides: Sides, color: Output) {
// ...
}
그러면 다음과 같이 호출 지점의 가독성과 타입 안전성을 높일 수 있다.
print_page(Sides::Both, Output::BlackAndWhite);
bool 타입 인수를 받도록 정의할 때와 달리, 라이브러리 사용자가 실수로 인수의 순서를 바꿔 적으면 컴파일러가 즉시 오류 메시지를 출력한다.

뉴타입 패턴 newtype pattern 을 이용해 bool을 래핑하면 타입 안전성과 유지 보수성을 모두 확보할 수 있다. 항상 bool 타입임을 나타낸다면 뉴타입 패턴을 사용하고, 나중에 새로운 대안(예: Sides::BothAlternateOrientation )이 나올 가능성이 있다면 enum을 사용하는 것이 좋다.
러스트의 enum에 대한 타입 안전성은 match 표현식으로도 보장할 수 있다.


컴파일러는 enum으로 표현되는 모든 경우의 수를 프로그래머가 반드시 검토하도록 요구한다. 디폴트 갈래 arm 만 추가하더라도(_ => {} ) 말이다(최신 C++ 컴파일러는 enum에 대한 switch 갈래가 없는 경우에 대해서도 경고 메시지를 출력한다).
러스트 enum의 진정한 강력함은 각 배리언트마다 데이터를 가질 수 있는 능력에 있다. 이를 통해 묶음 타입이 대수적 데이터 타입(ADT)처럼 작동하게 만들 수 있다. 다른 언어를 사용하던 프로그래머에게는 이러한 점이 생소할 수 있는데, C/C++에서 enum과 union을 조합한 것에 타입 안전성이 보장되는 것과 같다.
즉, 프로그램 데이터 구조의 불변성 invariant 을 러스트의 타입 시스템으로 인코딩할 수 있으며, 이러한 불변성을 어기면 컴파일되지 않는다. 작성자의 의도가 컴파일러뿐만 아니라 사람에게도 명확하게 드러나는 enum이야말로 제대로 설계된 enum이라고 할 수 있다.
use std::collections::{HashMap, HashSet};
pub enum SchedulerState {
Inert,
Pending(HashSet<Job>),
Running(HashMap<CpuId, Vec<Job>>),
}
이 타입 정의만 보면 Job은 Pending 상태 큐 queue 에 들어가 있다가 스케줄러가 완전히 활성화 되는 시점에 CPU 풀 pool 에 할당된다고 예상할 수 있다.
이런 식의 구성이야말로 바로 이번 아이템의 핵심 주제인 ‘러스트는 어떻게 타입 시스템을 통해 프로그램 컨셉을 디자인하는가’를 보여주는 단적인 예라 할 수 있다. 다음과 같이 필드나 매개변수의 유효성 조건에 대한 주석이 달린다면, 개념을 타입 시스템에 제대로 표현하지 못했다는 뜻이다.

이런 코드는 다음과 같이 ‘데이터를 담을 수 있는 enum’으로 표현하는 것이 바람직하다.
pub enum Color {
Monochrome,
Foreground(RgbColor),
}
pub struct DisplayProps {
pub x: u32,
pub y: u32,
pub color: Color,
}
간단한 예제지만 이번 아이템의 핵심 주제를 잘 보여 준다. 즉, 유효하지 않은 상태가 타입에 표현될 수 없게 만들어야 한다. 올바른 값 조합만 지원하도록 타입을 구성하면, 오류가 발생할 수 있는 모든 경우를 컴파일러가 걸러낼 수 있으므로 코드를 간결하면서도 안전하게 만들 수 있다.
다시 enum의 강력함에 대한 주제로 돌아와서, 흔히 사용하는 두 가지 enum 타입을 알아보자. 너무나 자주 사용되는 나머지 러스트 표준 라이브러리는 이를 기본으로 제공한다.
✔️Option<T>
첫 번째 enum 타입은 Option이다. 이 타입은 특정 타입의 값이 있을 수도 있고(Some(T)), 없을 수도 있음(None)을 나타낸다. 값이 없을 수도 있는 경우는 반드시 Option으로 표현한다. 예전 방식처럼 센티넬 값 sentinel value (예: -1, nullptr 등)으로 표현하면 안 된다.
여기서 한 가지 고려할 점이 있다. 컬렉션 collection 을 다룰 때, 원소가 없는 경우와 컬렉션이 없는 경우가 같은 의미인지 결정해야 한다. 대부분의 상황에서는 두 경우를 구분할 필요가 없어서 (예를 들어 Vec<Thing>을 사용해) 컬렉션 자체가 없다는 것을 원소가 0개인 것으로 표현해도 된다.
하지만 이런 두 경우를 Option<Vec<Thing>>으로 구분해야 할 상황은 드물지만 분명히 있다. 예를 들어 암호화 시스템에서 ‘페이로드가 별도로 전송되는 경우’와 ‘빈 페이로드가 제공되는 경우’를 구분해야 한다(SQL의 열에 대한 NULL 마커 사용 여부를 둘러싼 논쟁과 관련 있다).
그렇다면 값이 없을 수 있는 String은 어떻게 표현하는 것이 가장 좋을까? 값이 없음을 나타내는 용도로 ""와 None 중에서 어느 것이 더 적합할까?
둘 다 좋지만 Option<String>이 값이 없을 수 있다는 가능성을 보다 명확하게 드러낼 수 있다.
✔️Result<T, E>
두 번째 enum 타입은 오류 처리에서 흔히 사용되는 Result다. 호출한 함수가 실패할 경우, 그실패를 어떻게 전달해야 할까? 이전에는 특수 센티넬 값(예: 리눅스 Linux 시스템 콜의 -errno ) 이나 글로벌 변수(예: POSIX 시스템의 errno )를 사용했다. 최근에는 다중 반환값 또는 튜플 반환값을 지원하는 언어(예: 고 언어)의 경우, (result, error) 쌍을 반환하는 관례를 따른 다. 여기서는 error가 ‘0’이 아니라면 result에 ‘0’에 해당하는 적절한 값이 들어간다고 가정한다.
바로 이런 경우에 러스트의 enum을 사용하면 된다. 실패할 수 있는 연산 결과는 항상 Result<T, E>로 인코딩한다. 여기서 T 타입은 Ok 배리언트에 성공 결과를 담고, E 타입은 Err 배리언트에 실패했을 때의 세부 오류 정보를 담는다.
이처럼 표준 타입을 사용하면 설계 의도를 명확히 드러낼 수 있다. 또한 표준 변환과 오류 처리를 사용할 수 있으므로 ? 연산자로 오류 처리를 간소화할 수 있다.
위 콘텐츠는 『이펙티브 러스트』에서 내용을 발췌하여 작성하였습니다.

최신 콘텐츠