유사한 데이터가 들어 있는 여러 개의 파일이 있는 경우 모든 데이터가 하나의 파일에 포함되도록 데이터를 합쳐야 하는 경우가 있다. 프로그래밍을 배우기 이전에는 각 파일을 수동으로 하나씩 열고 각 워크시트의 데이터를 복사하여 하나의 워크시트에 붙여넣기하는 식으로 작업했을 것이다. 이러한 수작업은 시간이 오래 걸리고 오류가 발생하기 쉽다. 또한 수작업이 불가능한 수준의 양 또는 크기의 파일들을 병합해야 할 수도 있다.
수작업으로 데이터를 연결하는 방법에는 이러한 단점이 있으므로, 이제 파이썬으로 여러 파일의 데이터를 합치는 작업을 살펴볼 것이다. 앞 절에서 작성한 세 개의 CSV 파일을 사용하여 여러 개의 파일 속에 있는 데이터를 하나로 합치는 방법을 살펴보자.
기본 파이썬
기본 파이썬으로 여러 입력 파일 속 데이터를 하나의 출력 파일로 수직으로 합쳐보겠다. 텍스트 편집기에 다음 코드를 입력하고 파일명을 9csv_reader_concat_rows_from_multiple_files.py로 저장한다.
#!/usr/bin/env python3
import csv
import glob
import os
import sys
input_path = sys.argv[1]
output_file = sys.argv[2]
first_file = True
for input_file in glob.glob(os.path.join(input_path,'sales_*')):
print(os.path.basename(input_file))
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'a', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
if first_file:
for row in filereader:
filewriter.writerow(row)
first_file = False
else:
header = next(filereader)
for row in filereader:
filewriter.writerow(row)
14행은 출력 파일을 여는 with 문이다. 지금까지의 예제에서 출력 파일을 쓸 때는 open() 함수의 인수로 w를 지정했다. 이는 출력 파일을 쓰기 모드로 연다는 의미였다.
이번 예제에서는 w 대신 a를 사용하여 ‘추가append’모드에서 출력 파일을 열었다. 각 입력 파일의 데이터를 출력 파일에 계속해서 추가하려면 추가 모드를 사용해야 한다. 쓰기 모드를 사용하면 각 입력 파일의 데이터가 이전에 처리된 입력 파일의 데이터를 덮어쓰므로 출력 파일에는 마지막으로 처리된 입력 파일의 데이터만 남아 있게 된다.
17행에서 시작하는 if-else문은 10행에서 만든 first_file변수를 사용하여 첫 번째 입력 파일과 후속 입력 파일을 구별한다. 헤더 행이 출력 파일에 한 번만 기록되도록 입력 파일을 구분해야 한다. if블록은 첫 번째 입력 파일을 처리하고 헤더 행을 포함하여 모든 행을 출력 파일에 쓴다. else블록은 첫 번째를 제외한 나머지 모든 입력 파일을 처리하고 행을 출력 파일에 기록하기 전에 next()함수를 사용하여 각 파일의 헤더 행을 변수에 할당한다(이렇게 해서 헤더 행을 처리되지 않게 하는 것이다).
스크립트를 실행하려면 명령 줄에 다음을 입력하고 엔터 키를 누른다.
python 9csv_reader_concat_rows_from_multiple_files.py "C:\Users\Clinton\Desktop"
9output.csv
[그림 2-16]과 같이 화면에 출력된 입력 파일의 이름을 확인한다.
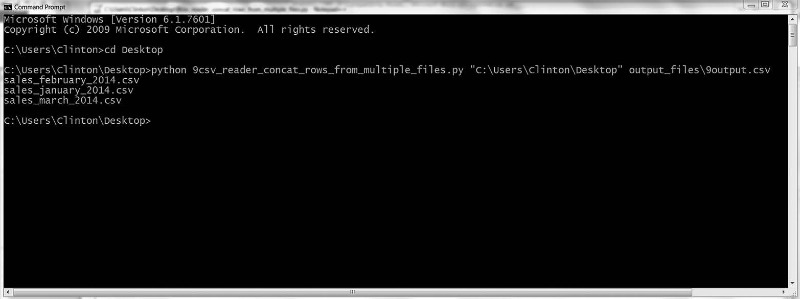
[그림 2-16 파이썬 스크립트 실행 결과]
화면에는 처리된 파일의 이름이 출력된다. 또한 이 스크립트는 세 개의 입력 파일 속 데이터를 합친 하나의 출력 파일을 9output.csv로 저장한다. [그림 2-17]은 출력 파일을 스프레드시트에서 열어본 모습이다.
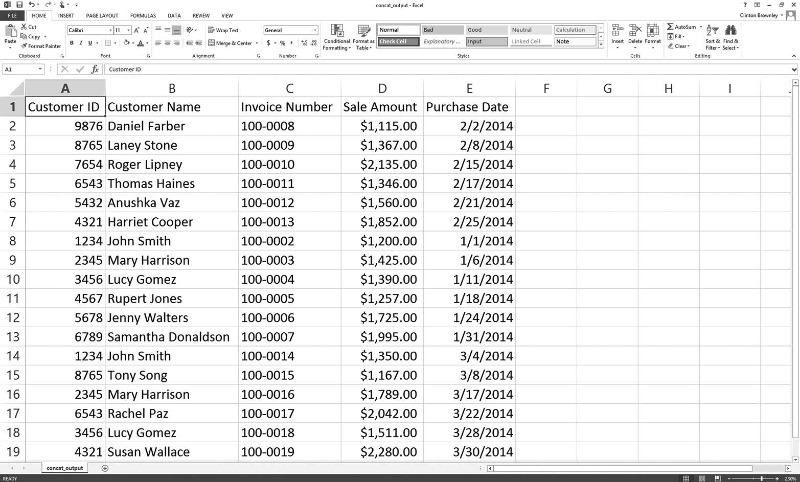
[그림 2-17 출력 CSV 파일]
스크립트가 세 개의 입력 파일에 있는 데이터를 성공적으로 합쳤음을 볼 수 있다. 출력 파일에는 하나의 헤더 행과 세 개의 입력 파일에 있는 모든 데이터 행이 포함되어 있다.
앞에서 14행에서 w(쓰기 모드) 대신 a(추가 모드)를 사용하는 이유와 첫 번째 입력 파일과 이후의 모든 파일을 구별하는 이유도 언급했다. a를 w로 변경한 다음 스크립트를 저장하고 다시 실행하여 결과가 어떻게 변하는지 확인해보면 더 정확하게 이해할 수 있을 것이다. 마찬가지로 if-else문에서 if부분을 제거하면 출력 파일이 어떻게 변하는지 확인할 수 있다.
한 가지 명심할 점은 이 예제에서 사용한 패턴인 sales_*가 상대적으로 구체적이라는 점이다. 바탕화면에 세 개의 입력 파일 외에 sales_로 시작하는 다른 파일이 없다고 예상할 수 있는 상황이기 때문이다. 다른 상황에서는 *.csv와 같이 덜 구체적인 패턴을 사용하여 모든 CSV 파일을 검색할 일이 더 많을 것이다. 이러한 상황에서는 입력 파일이 들어 있는 동일한 폴더에 출력 파일을 생성하지 않는 것이 좋다. 입력 파일을 처리하는 동안 스크립트에서 출력 파일을 열기 때문에 패턴이 *.csv이고 출력 파일도 CSV 파일이면 스크립트는 출력 파일도 입력 파일 중 하나로 인식하여 같은 방식으로 처리하려고 시도할 테고 따라서 문제와 오류가 발생한다. 따라서 출력 파일을 다른 폴더에 저장하는 것이 좋다.
팬더스
팬더스를 이용해 여러 파일의 데이터를 합치는 것은 더욱 쉽다. 기본 프로세스는 각 입력 파일을 데이터프레임으로 읽어 들이고 all_data_frame리스트에 추가한 다음 concat()함수를 사용하여 모든 데이터프레임을 하나의 데이터프레임으로 합친다. concat()함수는 axis인수를 통해서 데이터프레임을 병합하는 방향을 수직(axis=0) 또는 수평(axis=1)으로 지정할 수 있다.
팬더스를 이용해 여러 입력 파일의 데이터를 수직 방향으로 합쳐서 하나의 출력 파일을 생성해보겠다. 텍스트 편집기에 다음 코드를 입력하고 파일명을 pandas _concat _rows _from _multiple_files.py로 저장한다.
#!/usr/bin/env python3
import pandas as pd
import glob
import os
import sys
input_path = sys.argv[1]
output_file = sys.argv[2]
all_files = glob.glob(os.path.join(input_path,'sales_*'))
all_data_frames = []
for file in all_files:
data_frame = pd.read_csv(file, index_col=None)
all_data_frames.append(data_frame)
data_frame_concat = pd.concat(all_data_frames, axis=0, ignore_index=True)
data_frame_concat.to_csv(output_file, index = False)
이 코드는 데이터프레임을 수직 방향으로 합친다. 수평 방향으로 연결하려면 concat()함수에서 axis=1로 설정한다. 팬더스에는 데이터프레임 외에도 시리즈Series라는 자료구조가 있다. 합치려는 객체가 시리즈인 경우에도 동일한 구문을 사용하면 된다.
때로는 단순히 데이터를 수직 또는 수평으로 합하는 대신에, SQL의 조인join과 같이 키가 되는 열의 값을 기준으로 데이터 셋을 합해야 한다. 팬더스에서는 merge()함수를 통해서 이런 작업이 가능하다. SQL 조인에 익숙하다면 pd.merge(DataFrame1, DataFrame2, on='key', how='inner')같이 merge()함수의 구문을 쉽게 활용할 수 있을 것이다.
또 다른 파이썬 모듈인 넘파이도 데이터를 수직 및 수평으로 합치는 몇 가지 기능을 제공한다. numpy를 np라는 이름으로 임포트하는 것이 일반적이고, 데이터를 수직으로 합치려면 np.concatenate([array1, array2], axis=0), np.vstack((array1, array2)) 또는 np.r_[array1, array2]같은 함수를 사용할 수 있다. 마찬가지로 데이터를 수평으로 합치려면 np.concatenate([array1, array2], axis=1), np.hstack((array1, array2)) 또는 np.c_[array1, array2]를 사용할 수 있다.
스크립트를 실행하려면 명령 줄에 다음을 입력하고 엔터 키를 누른다.
python pandas_concat_rows_from_multiple_files.py "C:\Users\Clinton\Desktop" pandas_
output.csv
그다음 출력 파일인 pandas_output.csv를 열어 결과를 확인할 수 있다.
최신 콘텐츠