지난 회에이어 자바로 배우는 핵심 자료구조와 알고리즘 "2장 알고리즘 분석"에 있는 실습2에 관한 이충일님의 풀이를 시작합니다.
이제 본격적으로 List를 구현하는 클래스를 설계해보자.
깃헙의 샘플소스는 최대한 사용하지 않고, 책에 기술되어있는 코드만을 통해 테스트코드가 제대로 동작할 수 있도록 메인 클래스를 설계해보려 한다. 먼저 앞으로 진행할 메인 클래스인 MyArrayList 의 기본 구조이다.
Base Code
public class MyArrayList<T> implements List<T> {
private int size;
private T [] array;
private final int DEFAULT_CAPACITY = 10;
@SuppressWarnings("unchecked")
public MyArrayList(){
array = (T[]) new Object[DEFAULT_CAPACITY];
size = 0;
}
@Override
public boolean add(T element) {
if(size >= array.length){
T[] bigger = (T[]) new Object[array.length * 2];
System.arraycopy(array, 0, bigger, 0, array.length);
array = bigger;
}
array[size] = element;
size ++;
return true;
}
@Override
public T get(int index) {
if(index < 0 || index >= size){
throw new IndexOutOfBoundsException();
}
return array[index];
}
@Override
public T set(int index, T element) {
// TODO : fill this method
return null;
}
}
책에선 이정도의 샘플 코드만 제공하는데, List를 구현받기 때문에 List인터페이스의 모든 메서드를 implements하면 아주 많은 List의 메서드를 확인할 수 있다.(add, get, set, remove, contains 등...)
이 중 실제로 내가 구현해볼 메서드는 다음과 같다.
- set
- indexOf
- add
- remove
Basic Test Code
public class MyArrayListTest {
protected List<Integer> mylist;
/**
* @throws java.lang.Exception
*/
@Before
public void setUp() throws Exception {
mylist = new MyArrayList<>();
mylist.add(1);
mylist.add(2);
mylist.add(3);
}
}
앞으로 진행할 테스트의 베이스가 되는 기본 세팅이다.
MyArrayList 인스턴스를 생성하여 1~3이라는 값을 세팅해주고 다음의 구현된 테스트를 진행해보려 한다.
1. set() 구현하기
자 첫번째 미션인 testSet() 이라는 테스트 메서드이다.
Test Code
@Test
public void testSet() {
Integer val = mylist.set(1, 5);
assertThat(val, is(new Integer(2)));
val = mylist.set(0, 6);
assertThat(val, is(new Integer(1)));
val = mylist.set(2, 7);
assertThat(val, is(new Integer(3)));
// return value should be 2
// list should be [6, 5, 7]
assertThat(mylist.get(0), is(new Integer(6)));
assertThat(mylist.get(1), is(new Integer(5)));
assertThat(mylist.get(2), is(new Integer(7)));
//System.out.println(Arrays.toString(mal.toArray()));
try {
mylist.set(-1, 0);
fail();
} catch (IndexOutOfBoundsException e) {} // good
try {
mylist.set(4, 0);
fail();
} catch (IndexOutOfBoundsException e) {} // good
}
}
테스트 메서드에 앞서, @Before를 통해 테스트 실행 전 mylist변수를 세팅해주었는데, mylist.add(1), add(2), add(3)이 그 내용이다.
그러면 현재 상태에서 테스트코드를 실행해보자.
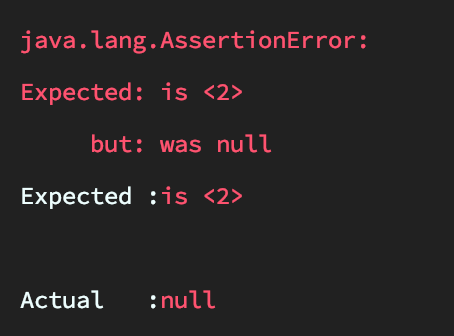
2라는 값이 들어오는것을 기대했는데, null이 들어왔다.
그도 그럴것이, set이 무슨 역할을 하는지 모르겠지만, set에서 어떤 작업을 한 결과를 val라는 변수가 받았고,
val라는 변수에 '2'가 있는지를 검증했는데, 'null' 이 나온 것이다.
왜?
@Override
public T set(int index, T element) {
// TODO : fill this method
return null;
}
우리가 무슨 값을 넣어도 set은 null을 반환하기 때문이다.
해당 메서드에서 필요한 add()와 get()은 이미 제공해주었으니, set()메서드만 정의하면된다.
Java docs : Set()
javadocs의 set()에 대한 명세를 살펴보면,
Replaces the element at the specified position in this list with the specified element (optional operation).
대략적으로 '특정한 위치'의 '특정한 요소'를 대체 한다는 것이 핵심이다.
Parameters:
index - index of the element to replace
element - element to be stored at the specified position
2개의 파라미터를 요구하는데,
- 대체될 index의 위치(specified position)
- 그 위치에 저장될 새로운 요소(specified element)
Returns:
the element previously at the specified position
지정된 위치의 '이전의 요소(값)'를 리턴한다.
정리하자면, 리스트의 해당 index를 새로운 element로 대체하여 저장하고, 리턴하는 값은 이전에 저장되어 있던 값이다.
그러면 심플하다.
해당
@Override
public T set(int index, T element) {
T prevValue = get(index);
array[index] = element;
return prevValue;
}
요구사항에 맞는 코드를 작성하면 다음과 같이 사용할 수 있겠다.
get()메서드를 재사용함으로써 교재 HINT에서 안내하는 '인덱스를 검사하는 코드의 반복'을 피할 수 있다.
자 그러면 다시 테스트 코드를 실행해보자.
무난하게 성공했다.
알고리즘
set() 함수는 입력되는 index값을 통해 array의 인덱스를 바로 접근하여 요소를 변경하고, 기존 array의 결과만 리턴해주면된다.
즉, 어떤 인덱스가 들어와도 전체 요소 중 하나만 접근하기 때문에 set()함수는 **상수 시간 연산 O(1)** 의 집합에 속한다.
2. indexOf() 구현하기
자 다음 미션은 indexOf 메서드를 채우는 것이다.
Java Docs : indexOf()
indexOf를 채우기에 앞서 javadocs의 설명부터 살펴보자.
int indexOf(Object o)
Returns the index of the first occurrence of the specified element in this list, or -1 if this list does not contain the element.
More formally, returns the lowest index i such that (o==null ? get(i)==null : o.equals(get(i))), or -1 if there is no such index.
리스트의 요소 중 첫번째 위치한 index를 반환한다. 만약 그 요소가 없다면 '-1'을 반환한다.
공식적으로 가장 낮은 index를 반환 (o == null ? get(i)==null : o.equals(get(i))) 하거나 해당 index가 없는 경우 '-1'을 반환한다.
Parameters:
o - element to search for
파라미터는 찾고자하는 element값.
Returns:
the index of the first occurrence of the specified element in this list, or -1 if this list does not contain the element
리스트의 요소 중 첫번째 위치한 index를 반환한다. 만약 그 요소가 없다면 '-1'을 반환한다.
Test Code : indexOf()
자 이제 테스트 코드를 살펴보자.
testindexOf()
@Test
public void testIndexOf() {
assertThat(mylist.indexOf(1), is(0));
assertThat(mylist.indexOf(2), is(1));
assertThat(mylist.indexOf(3), is(2));
assertThat(mylist.indexOf(4), is(-1));
}
4개의 검증이 진행되는데, 1부터 4라는 값이 각각 어떤 index에 위치하는지 검증하는 것이다.
구현하기
@Override
public int indexOf(Object o) {
for(int i=0; i<size; i++){
if(array[i] == o){
return i;
}
}
return -1;
}
우선 내 작업은 이렇게 정리했다. (equals함수에 대한 처리는 하지 못했다.)
결과적으로는 위와 같이 작성한 후 테스트하여도 결과는 성공을 볼 수 있다.
그런데 결과 코드를 보니까 조금 모양이 다르다. 하나씩 다시 짚어봐야 하겠다.
@Override
public int indexOf(Object target) {
for (int i = 0; i<size; i++) {
if (equals(target, array[i])) {
return i;
}
}
return -1;
}
private boolean equals(Object target, Object element) {
if (target == null) {
return element == null;
} else {
return target.equals(element);
}
}
여기서 내가 가장 큰 실수를 한것은 바로 ==연산과 equals연산의 혼동이다.
평소에 큰 고민없이 사용하던 습관이 이런 결과를 만들었다.
정확한 '값(Call by Value)'의 동일 여부를 검증하기 위해선 equals() 함수를 통해 검증해야한다. 그렇기 때문에 문서에서도 equals함수에 대한 언급이 있었을 것이다.
(o == null ? get(i)==null : o.equals(get(i))
하지만 습관적으로 사용한 '==' 연산(Call by Reference)은 값의 존재여부(null처리)를 정확히 처리해주지 못했다.
따라서 equals()라는 헬퍼함수를 통해서 null처리를 해준 후 정확한 값을 비교해야 했다.
알고리즘
indexOf() 함수는 인자로 받는 Object가 전체 배열 중 어떤 인덱스에 위치하는지 한번에 검증할 수 없다.
반복문을 통해서 전체 배열을 검사하여 해당 해당 인자값이 인덱스에 존재하는지의 여부와 위치를 검증해야 한다.
따라서 이 알고리즘은 최악의 경우 배열의 전체 크기만큼 반복하여 검증이 필요하므로, **선형 알고리즘 O(n)** 의 집합에 속한다.
3. add() 구현하기
다음은 add()함수에 2가지 인자(index, element)를 받는 경우다.
기존에 있던 add() 함수는 element 만을 받아, 가장 마지막 index ++ 에 해당 element가 위치한 것이라면,
이번에 확인해 볼 함수는 기존 index의 값이 이미 존재한다면, 다른 값들을 전체적으로 이동(shift)하여 공간을 만들어 주어야 한다.
Java Docs : add()
그럼 add()함수의 정의를 살펴보자.
void add(int index, E element)
Inserts the specified element at the specified position in this list (optional operation). Shifts the element currently at that position (if any) and any subsequent elements to the right (adds one to their indices).
리스트의 특정 위치에 요소를 삽입한다. 해당 위치에 이미 값이 존재한다면, 차후의(해당 인덱스 다음의) 모든 요소들은 오른쪽으로 이동한다.(이동된 요소의 인덱스에 1을 더한다.)
Parameters:
index - index at which the specified element is to be inserted
element - element to be inserted
리스트에 추가할 요소와 해당 요소를 삽입할 index를 받는다.
Test Code : add()
다음은 테스트 코드이다.
@Test
public void testAddIntT() {
mylist.add(1, 5);
assertThat(mylist.get(1), is(new Integer(5)));
assertThat(mylist.size(), is(4));
try {
mylist.set(-1, 0);
fail();
} catch (IndexOutOfBoundsException e) {} // good
try {
mylist.set(4, 0);
fail();
} catch (IndexOutOfBoundsException e) {} // good
mylist.add(0, 6);
//System.out.println(Arrays.toString(mal.toArray()));
assertThat(mylist.get(0), is(6));
mylist.add(5, 7);
//System.out.println(Arrays.toString(mal.toArray()));
assertThat(mylist.get(5), is(new Integer(7)));
}
첫 3줄만 보면, mylist의 인덱스 '1'에 '5'라는 값을 삽입했다.
따라서 다음의 get(1)에는 방금 삽입한 5라는 요소가 존재해야 하므로, true가 될 것이고,
기존에 add(1) ~(3)까지 size가 '3' 이 었는데, 방금 add를 통해 중간에 새로운 요소가 삽입 되었으므로, 전체 사이즈는 '4'가 될 것이다.
구현하기
그럼 이제 add()함수를 고민해보자.
핵심은 이부분일 것이다.
기존에 해당 인덱스에 값이 존재한다면, 해당 인덱스 다음의 모든 요소들은 오른쪽으로 이동한다.(이동된 요소의 인덱스에 1을 더한다.)
@Override
public void add(int index, T element) {
if(add(element)) {
for (int i = size; i <= index; i--) {
array[i] = array[i - 1];
}
array[index] = element;
}
}
이와같이 add()함수를 완성했다.
교재의 HINT에 다음과 같이 나와있었다.
배열을 더 크게 늘리는 코드를 반복하지 마세요.
놓칠뻔한 부분인데 이 힌트를 참고하여, 최우선적으로 기존의 add(element)를 재사용했다.
현재 배열 초기화시 배열의 크기(DEFAULT_CAPACITY)를 '10' 으로 해주었는데,
추가되는 element의 index 가 현재 배열의 length와 크거나 같을때 동적으로 그 사이즈를 *2 증가 시켜준다.
뿐만아니라, 현재 배열의 크기(size++)를 연산해주기 때문에 해당 함수는 호출해주는 것이 효율적이다.
다음 반복문의 경우, 기존의 인덱스에 값이 존재할 경우 전체가 오른쪽으로 이동해야하는데,
작은 인덱스부터 오른쪽으로 이동할 경우 i+1 번째의 인덱스가 모두 동일해진다.
떄문에 전체 배열 중 가장 오른쪽(가장 높은 인덱스)에 위치한 요소부터 이동시켜줘야한다.
그 작업을 한 것이 반복문의 내용이고, 나머지는 간단하게 해당 인덱스에 값을 넣어준 것이 전부 이다.
그러면 결과 코드와 다시 비교해보자.
@Override
public void add(int index, T element) {
if (index < 0 || index > size) {
throw new IndexOutOfBoundsException();
}
// add the element to get the resizing
add(element);
// shift the elements
for (int i=size-1; i>index; i--) {
array[i] = array[i-1];
}
// put the new one in the right place
array[index] = element;
}
얼추 비슷한 결과이지만, 놓친것은 역시 '**예외처리'** 이다. 여전히 예외처리를 재대로 고민하지 않는 습관이 있다.
알고리즘
이 역시 이전의 indexOf()와 크게 다르지 않다. 어떤 인덱스에 새로운 요소가 추가될지 모르기 때문에,
인자값에 따라 배열을 n번 탐색해야하기 때문에 마찬가지로 **선형 알고리즘 O(n)** 의 집합에 속한다.
4. remove() 구현하기
마지막으로 remove() 함수를 처리하는 것이다.
Java Docs : remove()
E remove(int index)
Removes the element at the specified position in this list (optional operation). Shifts any subsequent elements to the left (subtracts one from their indices). Returns the element that was removed from the list.
리스트의 해당 위치에 존재하는 요소를 제거한다. 차후에 전체 요소는 왼쪽으로 이동한다(이동된 전체 인덱스들은 1씩 차감된다.)
리스트에서 제거된 요소의 값을 반환한다.
Parameters:
index - the index of the element to be removed
파라미터는 제거할 요소의 인덱스(위치) 이다.
Returns:
the element previously at the specified position
해당 인덱스에 존재했던 요소를 반환한다.
간단하게, 리스트의 인덱스에 위치한 요소를 제거하고, 제거된 인덱스 다음에 위치한 모든 인덱스들은 왼쪽으로 한칸씩 이동한다.
그리고 방금 제거된 요소를 반환하면 된다.
Test Code : remove()
테스트 코드이다.
@Test
public void testRemoveInt() {
Integer val = mylist.remove(1);
assertThat(val, is(new Integer(2)));
assertThat(mylist.size(), is(2));
assertThat(mylist.get(1), is(new Integer(3)));
}
역시 심플하다. remove된 후 기존에 위치하고 있던 값을 리턴하고 있고, 배열의 전체 사이즈는 1만큼 줄어 들었다.
구현하기
이를 성공시킬 코드를 구현해보았다.
@Override
public T remove(int index) {
T prevVal = get(index);
int cnt = size - index;
for(int i=index; i<=cnt; i++){
array[i] = array[i+1];
}
size --;
return prevVal;
}
값이 제거되면, 해당 인덱스의 값이 비어있기 때문에 삭제되는 인덱스보다 큰(우측에 있는) 요소들의 인덱스는 전부 -1씩 빼주어야 한다.
따라서 반복문의 시작은 index 가 기준이 될 것이고, 반복 횟수는 전체 사이즈에서 index 를 뺀 횟수 만큼 해야한다.
반복문에서는 배열의 인덱스 값을 하나씩 옮겨 주는 것이고, 작업 완료 후 배열의 사이즈는 1만큼 감소 시킨다.
그리고 옮기기 전 기존에 존재하던 요소를 리턴할 준비를 미리 해 두었다.
일단 이와같이 작업해서 테스트코드는 성공시켰다.
결과 코드와 비교해보자.
@Override
public T remove(int index) {
T element = get(index);
for (int i=index; i<size-1; i++) {
array[i] = array[i+1];
}
size--;
return element;
}
이번엔 다행히도 전체 로직은 거의 비슷하다.
내 코드에선 cnt라는 변수에 다소 불필요한 연산을 진행했다.
정확한 반복횟수를 계산하기 위함이었는데, 사실 index의 위치부터 size 만큼 반복하는 것이니, 저 연산은 불필요하다.
알고리즘
remove에서 진행되는 get(index) 는 O(1)의 알고리즘,
그리고 반복문에서 진행되는 로직은 역시 인자값(index)에 따라 n번 만큼 수행될 수 있기 때문에 마찬가지로 역시 **선형 알고리즘 O(n)**에 속한다.
따라서 전체 알고리즘 연산은 **O(n)** 이다.
이로써 처음으로 List라는 객체에 대해서 분석하고, 리스트의 구조를 이해하며, 그 안에서 일어나는 알고리즘에 대해서 살펴보았다.
10번 눈으로 보는것보다 1번 해보는 것이 낫다고, 처음 자바를 배울때도, 그리고 간간히 리스트에 대한 텍스트를 많이 읽어왔지만 사실 그 때 뿐이었다.
사실상 실무에선 ArrayList만 사용해왔기 때문에 리스트의 구조에 대해서 깊이있게 고민해본적도, 알고자 한적도 없었다.
그리고 무엇보다, 막상 실제 구조를 들여다보니 생각보다 복잡하거나 어렵지 않다는 것도 고무적이다.
이제 맛보기에 불과하지만 앞으로 진행할 Map 이나 Tree와 같은 자료구조들에 대한 실습도 기대된다.
최신 콘텐츠