괜찮게 잘 봤습니다.
편하게 보시려면 먼저, 파이썬과 인공지능 선행수업이 필요합니다.
[나는 리뷰어다] 1월 이벤트에 당첨되어 한빛 미디어 첫걸음 시리즈중 신간인 강화학습 첫걸음을 접하게 되었다.

강화학습 첫걸음 - 텐서플로로 살펴보는 Q 러닝, MDP, DQN, A3C 강화학습 알고리즘
지은이 - 아서 줄리아나, 옮긴이 송교석
작년에 나온 신경망 첫걸음이 개인적으로 유익했던 터라 강화학습 첫걸음도 꽤 기대를 했고, 결론부터 말하자면 상당히 만족스러웠다.

신경망 첫걸음, 강화학습 첫걸음
책의 흐름은 간단한 밴딧 문제를 시작으로 부제에 나온대로 마르코프 결정과정(MDP), Q 러닝, 딥 Q 네트워크(DQN), 어싱크 어드밴티지 액터-크리틱(A3C), 그리고 파트2에서 심화 주제로 넘어 간다.
책의 구성은 챕터별 설명과 예제 코드가 포함되어 있다. 예제 코드를 이해해기 위해 텐서플로우와 파이썬의 기본적인 지식은 있어야 수워하게 실습을 진행할 수 있다. 예제 코드는 깃헙(https://github.com/awjuliani/DeepRL-Agents)에 모두 올라가있지만, 통채로 클론받아서 돌리는것 보다는 직접 코드를 쳐보고, 값을 변경해 가며 결과가 어떻게 달라지는지 확인하며 진행 한다면 책의 내용을 이해하는데 더욱 효과적일 것이다.
끝으로 이 책은 신경망과 경사하강법 등 머신러닝 기술에 어느 정도 익숙한 독자를 대상으로 쓰여졌다. 그러나 학습기법에 대한 설명이 심플하게 잘 되어있어 딥러닝이나 신경망에 대한 지식이 없어도 크게 거북하지 않을것이라 개인적으로 생각한다.

관련도서 소개 - 밑바닥부터 시작하는 딥러닝, 텐서플로 첫걸음, 딥러닝 첫걸음
혹시 딥러닝에 대해서 처음 접근한다면 위에 나와있는 관련도서나 앞에 언급한 신경망 첫걸음도 도움이 될 것이다.
한빛미디어의 인공지능 시리즈 중 강화학습에 대해 설명한 책이다.
기존과 비교해 봤을 때 "신경망 첫걸음", "처음 배우는 인공지능" 같은 경우는 초심자들이 인공지능을 시작할 때 접근하기 좋은 책이라면, "강화학습 첫걸음" 이라는 책은 인공지능 초심자보다는 약간이라도 딥러닝을 접한 사람 그리고 기초를 넘어 강화학습을 배우고 싶은 사람들에게 보다 추천되는 책이다.
(실제로 해당 책에서는 Tensorflow를 통해 구현하기 때문에, Tensorflow에 대한 지식을 가지고 있는 사람은 그렇지 않은 사람들 보다 접근하기 쉽다.)
"강화학습 첫걸음" 책은 강화학습의 기본 원리부터 심화주제까지 다룬다.
기본 원리를 통해 강화학습의 동작 원리에 대해 파악할 수 있고, 심화 주제를 통해 최근 강화학습의 동향 또한 파악 할 수 있다.
하지만 책을 정독했다고 해서 강화학습을 알았다고는 할 순 없다. 이 책은 책의 양에서도 느낄 수 있듯이 모든 부분이 자세히 나온 것이 아니라, 비기너가 강화학습을 보다 쉽게 접근하기 위한 개념을 잡는 책으로 기초 도서이다. (그렇기에 책의 내용이 쉽게 적혀있다.)
때문에 깊이 있는 공부를 위해서는 논문, 인터넷 강의 등 다양한 자료를 접해야 한다.
많은 사람들이 인공지능에 대해 공부하고 싶지만 어려운 수식과 복잡한 이론에 겁을 먹고 도전하기를 어려워 합니다 (제이야기입니다 ... ㅠ) "강화학습 첫걸음"은 저같은 사람들을 위해 복잡한 수식을 줄이고 최대한 간략하게 이론을 설명하고 실습위주의 진행으로 이루어집니다. 말그대로 강화학습에 대해 "첫걸음"을 하고 싶은 분들에게 추천드립니다.
이 책은 아래 책표지에서 볼 수 있듯이 컴퓨터 학습을 통해 인간의 뇌에 근접하게 만드는 다양한 방법론들을 가볍게 다루고 있다. 전체 책은 200페이지가 안되고 들고 다닐 수 있을 정도의 무게이다.

하지만, 이 책은 다양한 방법론 및 기법에 대해서 소개 및 설명을 하고 있기 때문에 관심이 있는 방법론에 대해서 추가적인 연구 및 자체 프로젝트가 많이 필요하다고 생각이 되었다.
종종 얇은 책의 경우엔 그림이 너무 없어 처음 개념을 잡기 힘든 경우가 많지만, 해당 책의 경우엔 중간중간 그래프 및 도표 등을 활용하여 책이 말하고자 하는 방향성을 잃지 않게 만들어 주어서 맘에 들었다.

하지만, 아쉬운 점은 실제로 어떤 프로젝트에서 활용한 실례를 들어주었으면 하는 조그마한 아쉬움이 남는 책이었다.

책이 가벼워서 들고 다니면서 짬짬이 읽기 좋았으나, 내용 하나하나가 많은 생각과 고민을 하게 만들어준 책이었다.
머신 러닝에 대해 관심이 있고, 어느 정도 머신 러닝에 대해 알고 있으면서 다음 단계를 고민하는 분들에게 추천을 드리고 싶은 책이며, 개인적으로는 기회가 되면 스터디 교재로 사용하고 싶다.

1. 책의 구성 및 내용
강화학습 첫걸음 책은 크게 두 파트로 나뉘어져 있는데 앞 부분에서 주요 알고리즘을 간단하게 소개한 뒤 구현을 하는 루틴을 반복하고 뒷 부분에서는 좀 더 심화 주제를 다룬다. 먼저 아주 간단한 멀티암드 밴딧(손잡이가 여러개인 슬롯머신) 문제를 다룬다. 뒤로 갈수록 콘텍스트가 추가된 슬롯머신, 마르코프 결정 과정을 응용한 에이전트로 발전시켜 나가며 정책 기반의 알고리즘을 소개한다. 5장 부터는 Q 러닝을 다루기 시작하며 간단한 테이블 버전부터 시작해 단일 신경망, 다층 신경망으로 발전시켜나가며 벽돌 깨기 게임에서 볼 수 있던 그 딥 Q 러닝에 대해 다룬다. 앞 부분의 마지막으론 비동기적 어드밴티지 액터-크리틱 모델에 대해 다루는데 최근 경향까진 알지 못했던 차에 좋은 정보를 얻을 수 있었다.
2. 좋았던 점
책에서는 각 챕터마다 간단하게 개념에 대해 설명해주고 실습 코드로 들어가는데 이렇게 흥미를 유지시켜주고 바로 결과를 확인할 수 있게끔 유도하는 구성이 매우 마음에 들었다. 무턱대고 수식부터 보여주는 것이 아닌 개념이 등장한 배경과 필요성을 충분히 말해주며 더불어 알고리즘과 수식에 대해 친절하게 풀어서 설명해주는데 그냥 그렇구나 정도로만 넘어갔던 부분에 대해 잘 정제된 지식을 제공받는 느낌이었다.
제일 마음에 들었던 부분은 책이 점진적인 구성을 가지고 있다는 점이다. 처음부터 고급 부분을 다루는 것이 아니라 독자가 머신러닝은 다뤄봤지만 강화학습은 처음인 개발자를 타겟으로 두었는지 아주 간단한 모델부터 차근차근 진행해 나가는 점이 인상적이었다. 그래서인지 콘텍스트가 왜 필요한지, 지연된 보상이 있고 없고 차이가 뭔지를 보다 직관적으로 확인할 수 있었다.
3. 아쉬웠던 점
이건 개인적인 부분이긴 하고 아직 강화 학습에 대해 많은 것을 알지 못하기에 언급하기 조심스러운 면이 있어 간단하게만 다루려 한다.
개인적으로 밑바닥부터 구현하는 과정을 좋아하는 편인데 이 책에서는 보편적인 독자의 흥미를 고려한 탓인지 그 기반 기술에 대한 설명을 넘어가는 경향이 있다. gym 라이브러리를 사용해 환경을 받아오는 과정도 매우 궁금했고 그게 꼭 필요한건지 없으면 어떻게 구현해야 하는건지 궁금했는데 이 부분보다는 gym 라이브러리를 활용해 어떻게 모델을 구현할 수 있는지에 초점이 맞춰져 있어 아쉬웠다.
더불어 각 장에 나오는 코드의 실행 결과가 시각적으로 충분히 다가오지 않는 점도 아쉬웠다. 이는 물론 원 저자의 코드가 이랬기에 어쩔 수 없다고 생각되지만 에이전트가 작동하는 모습을 좀 더 시각적으로 표현할 수 있는 법을 소개하는 부분이 있었으면 더 좋지 않았을까 싶다. 책에서는 단순히 리워드가 얼마나 쌓였고 점수를 얼마나 획득했는지밖에 보이지 않아서 초반 흥미를 이어나가는데 아쉬웠던 점이 있었다.
4. 어떤 사람에게 추천하는가
강화 학습을 들어만 봤지 뭐부터 시작해야하고 개념도 잘 모르는 분들께 추천한다. 책 자체는 강화학습 입문서로 매우 훌륭하다고 생각한다. 이 책을 통해 각종 개념들에 친숙해지고 이리저리 개조해보면서 내가 해결하고 싶은 문제에 접목시키는 교두보로 삼기 충분한 것 같다.
강화학습 첫걸음 도서 리뷰
한빛미디어의 컴퓨터서적 중 첫걸음 시리즈가 있다.
첫걸음 시리즈는 다른 도서들에 비해 얇아 부담없이 읽을 수 있다.
강화학습 첫걸음 도서를 받아보 마찬가지로 만족스러운 내용이 담겨있었다.
[##_1N|cfile1.uf@998F564F5A8B7A201CC6BB.jpg|width="703" height="936" filename="KakaoTalk_20180220_100751214.jpg" filemime="image/jpeg" style="text-align: left;" original="no"|_##]
목차의 구성은 아래와 같다.
PART I 주요 알고리즘 및 구현
CHAPTER 1 강화학습 소개
CHAPTER 2 밴딧 문제
2.1 정책 경사
2.2 멀티암드 밴딧의 구현
CHAPTER 3 콘텍스트 밴딧
3.1 콘텍스트 밴딧 구현
CHAPTER 4 마르코프 결정 과정
4.1 기본적인 정책 경사 에이전트 구현
CHAPTER 5 Q 러닝
5.1 테이블 환경에 대한 테이블식 접근법
5.2 신경망을 통한 Q 러닝
CHAPTER 6 딥 Q 네트워크
6.1 개선 1: 합성곱 계층
6.2 개선 2: 경험 리플레이
6.3 개선 3: 별도의 타깃 네트워크
6.4 DQN을 넘어서
6.5 더블 DQN
6.6 듀얼링 DQN
6.7 모든 것을 조합하기
6.8 개선된 딥 Q 네트워크 구현
CHAPTER 7 부분관찰성과 순환 신경망
7.1 부분관찰성 문제
7.2 제한되고 변화하는 세계 이해하기
7.3 순환 신경망
7.4 텐서플로 구현을 위한 변경점
7.5 제한된 그리드 세계
7.6 DRQN 구현
CHAPTER 8 비동기적 어드밴티지 액터-크리틱
8.1 A3C의 세 가지 A
8.2 A3C 구현
8.3 <둠> 게임 플레이하기
PART II 심화 주제
CHAPTER 9 에이전트의 생각과 액션 시각화
9.1 컨트롤 센터의 인터페이스
9.2 에이전트의 머릿속 들여다보기
9.3 강화학습 컨트롤 센터 이용
CHAPTER 10 환경 모델 활용하기
10.1 모델 기반의 강화학습 구현
CHAPTER 11 탐험을 위한 액션 선택 전략
11.1 탐험은 왜 하는 것인가요?
11.2 그리디 접근법
11.3 랜덤 접근법
11.4 엡실론-그리디 접근법
11.5 볼츠만 접근법
11.6 베이지언 접근법(드롭아웃)
11.7 각 전략의 성능 비교 및 구현
11.8 고급 기법
CHAPTER 12 정책 학습을 위한 정책 학습
12.1 메타 에이전트 만들기
12.2 메타 실험
12.3 마치며
신경망이 아닌 강화학습 에 맞춰진 책이기 때문에 머신러닝, 딥러닝을 처음 입문하는 사람들에게는 적합하지 않은 책이다.
머신러닝 공부를 생 처음 시작하는 입문자에게는 [신경망 첫걸음, 딥러닝 첫걸음, 밑바닥부터 시작하는 딥러닝] 이 책들을 추천하고 싶다.
딥러닝의 이론과 수식을 이해할 수 있는 배경지식이 있어야 읽기에 수월할 것이다.
위의 조건을 대략 충족하는 사람에겐 python코드가 자세히 나와있다는 점과 cart-pole,Frozen lake,Doom,Grid world 와 같은 openAI GYM의 예제를 풀어보는 코드가 개념을 이해하는데 큰 도움을 준다.
이 책을 읽으면서 김성훈 교수님의 모두를 위한 RL강좌 을 참고하면 부족한 부분을 채워넣기에 충분할 것이다
한빛미디어 기계학습 첫걸음 계보에 또 한권의 책이 추가되었다. 보통 기계학습이라고 하면 비지도학습, 지도학습, 강화학습, 이렇게 세 가지로 구분해서 이 야기한다. 이번책은 "강화학습"에 대한 이야기를 풀어내는 강화학습 첫걸음이다. 그간 첫 걸음 시리즈를 무척 유익하게 봐왔었기 때문에 이번책에 대한 기대 또한 상당했는데 역시 만족스러웠다.
 강화학습 첫걸음 - 아서줄리아나 지음 송교석 옮김
강화학습 첫걸음 - 아서줄리아나 지음 송교석 옮김
위에 책 사진만 보면 상당히 얇기 때문에 거부감이 없겠다. 하지만 이 책은 "강화학습"에 대한 첫걸음이지 기계학습에 대한 첫걸음 책이 아니기 때문에 다양한 사전지식을 필요로 한다. 기본적으로 python, TensorFlow, 기계학습, 약간의 수학적 지식에 대한 부분은 어느정도 감이 있는 상태에서 시작하는 것을 권한다. 아래는 이러한 부분을 채워줄 수 있는 한빛미디어에서 발간된 첫걸음 시리즈다.
 한빛미디어 첫걸음 시리즈
한빛미디어 첫걸음 시리즈
책의 내용을 살펴보면 멀티암드 밴딧(multi-armed bandit) 문제를 시작으로 마르코프 결정 과정(MDP) 문제를 순서대로 다룬다. 이어서 곧바로 강화학습 문제를 푸는 Q 러닝의 기본에 대해서 다루고 더 진보한 딥 Q 네트워크(DQN) 를 설명한다. 끝으로 강화학습 분야에서 가장 뛰어난 성능을 보이는 비동기적 어드밴티지 액터-크리틱(A3C) 기법에 대해서 설명한다.
책의 모든 예제는 GitHub 에 있기 때문에 쉽게 다운로드 받고 필요시 issue 를 제기할 수 있다. 하지만 언제나 강조 하듯이 백문이 불여일타. 웬만하면 직접 예제를 타이핑하며 공부하는 방식을 추천한다. 그래야 오래 기억에 남고 코드가 눈에 들어온다. (아이러니 하지 않나? 손으로 코드를 타이핑하는데 눈에 들어온다니. 사실 실습코드를 제공하는 대부분의 프로그래밍 책이 그러하다)
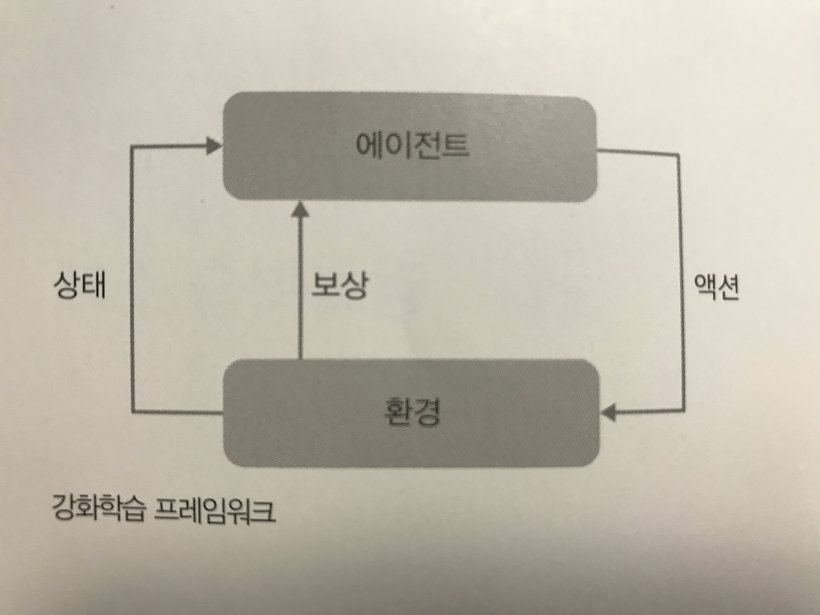 강화학습 프레임워크
강화학습 프레임워크
강화학습의 기본이 되는 프레임워크에 대한 다이어그램이다. 액션(action), 보상(reward), 상태(state), 에이전트(agent), 행위(action) 이 다섯개의 용어는 강화학습 분야에 항상 따라다니는 단어이므로 필수로 익혀두도록 하자. 강화학습 관련된 어떤 자료를 봐도 통일되어 사용 되는 단어다.
책을 읽어내려가다 보면 아래와 같은 수식을 종종 보게 된다. 강화학습을 맛만 보려는 사람은 흘려넘어가도 전체 큰 프레임에는 크게 지장이 없지만 사실 그렇게 해서는 다른 문제를 딥하게 접근하는데 어려움이 따른다. 내 경우에는 그나마 다른 첫걸음 시리즈에서 이미 수학적 이야기를 많이 봤기 때문에 그나마 살짝 이해하며 넘어갈 수 있었다.
 수학적 이해가 필요하다
수학적 이해가 필요하다
책의 후반부에 가면 추억의 게임인 둠을 강화학습 하는 것에 대한 내용도 다루기 때문에 뭔가 어렵게 읽고나면 보상(reward) 받는 기분이 든다. 사실 기계학습을 전공으로 해도 분야가 다르면 강화학습을 건드릴 일이 없을 수도 있다. 하지만 앞으로 많은 분야에 기계학습이 도입될테고 강화학습에 대한 기대치도 계속 높아지고 있기 때문에 미리 이 책으로 맛보는 것은 훌륭한 선택이겠다. 혹시 이 책이 어렵게 느껴진다면 홍콩과기대 김성훈 교수님의 유튜브를 함께 보도록 하자. 이해를 도울 수 있을 것이다.

"이 책은 신경망과 경사하강법 등 머신러닝 기술에 어느 정도 익숙한 독자를 대상으로 쓰였습니다" 라는 본문의 내용처럼 "첫걸음" 시리즈지만 첫걸음처럼 느껴지지 않는 그런 책이다. 강화학습이라는 것 자체가 기계학습의 한 분야라서 지도학습 등 다른 분야에 어느정도 지식이 없으면 읽을 수 없는 것이 마땅한 이치다. 그렇기 때문에 책의 난이도로 서평을 하기는 어려울 것이다. 적어도 이 책은 강화학습에 대한 전반적인 내용을 충실히 다루고 있으며 예제를 통해 실습을 도와주고 있기 때문에 좋은 귀감을 준다. 다만 아쉬운 점이 있다면 첫걸음 시리즈에 맞게 컬라였다면 어땠을까? 송교석님이 앞서 옮기신 신경망 첫걸음을 보면 컬러책이 주는 버프를 포기하는 것이 쉽지 않다는 것을 알 수 있다.
한빛 미디어에서 '텐서플로 첫걸음'으로 첫걸음 시리즈를 공부한 적이 있었는데,
당시 처음 입문자로서 접근하기 쉽게 설명이 되어 있어서 많은 도움을 받은 경험이 있다.
그래서 그런지, '강화학습 첫걸음'에 대한 나의 기대감 또한 컸다.
책은 크게 12 챕터로 구성이 되어있고,
1~8 챕터는 강화학습의 주요 알고리즘, 9~12 챕터는 강화학습의 심화 주제에 대해 다루고 있다.


목차에서 보듯이, 이 책에서 설명하는 강화학습의 주요 알고리즘 부분에서는
콘텍스트 밴딧 / 마로코프 결정 과정 / Q러닝 / 딥 Q 네트워크 / 부분관차성과 순환 신경망 / 비동기적 어드밴티지 액터-크리틱
을 다루고 있다.
심화 파트에서는 agent의 action 시각화 / action 선택 전략 등을 서술하고 있다.
이처럼 책을 따라가면서 강화학습 전반의 개념을 이해하여 입문할 수 있게 도와주는 책이다.
책은 가장 먼저 강화학습의 용어를 정리하고 시작한다.
일반적으로 머신러닝은
- 지도학습 (Supervised learning)
- 비지도학습 (Unsupervised learning)
- 강화학습 (Reinforcement learning)
으로 나뉜다.
이 책에서 다룰 내용은 3가지 중에 강화학습 (Reinforcement learning)이다.
책 시작에 가장먼저 강화학습의 개념이 나온다.
강화학습이란?
agent(행위자)의 action(행위)는 환경에 영향을 준다는 가정 아래,특정 action이 환경의 state(상태)를 변화시키고 이에따라 agent는 reward(보상)를 받게 되는데이러한 행동의 기반이 되는 관계를 상호 관계라고 부른다. 그리고 이러한 상호 관계를 포착하여 포착하여 공식적인 모델로 만든 것이 바로 강화학습이다. (P.17-18)
그리고 주요 알고리즘에 대한 설명이 나오게 되는데,
알고리즘을 설명할때 이론적인 내용에 대해 우선 설명을 하고, 이를 code로 돌려가면서 직접 이해할 수 있게 주석이 달린 code를 책에서 함께 제공한다는 것이 특징이다.
저도 새로운 내용을 습득할 때 code를 직접 돌려가면서 하나하나 따라가며 공부할 경우 더 이해가 빠르게 되는 경우가 많았기에 이러한 점은 매우 만족스러웠다.
(물론, full code는 github에서 따로 제공한다)
https://github.com/awjuliani/DeepRL-Agents
책을 읽으면서 가장 좋았던 점은, 주요 설명이나 용어들에 각주를 달아서 인용한 논문을 직접적으로 찾아볼 수 있게 밑에다가 Reference를 달아주었다는 점이다. 많은 책들이 각주를 달아놓고 뒤로 빼버려서 찾기가 불편했는데 밑에 바로 적혀있어서 필요할때 마다 바로바로 검색해서 찾아볼 수 있다는 점이 편리했다.

하지만 이 책은 기본 신경망 및 머신러닝 이론에 대해 알고 있으며 강화학습을 처음 접근하는 독자를 대상으로 썼기에,
처음 신경망 분야를 접하는 사람에게는 적합하지 않다고 보여진다. 따라서 다른 기초 이론서를 먼저 읽고 접근해보기를 추천한다.

텐서플로 코드로 입문하는 강화학습의 세계
알파고의 기반인 강화학습은 게임 AI나 자율주행 등 업계 활용성이 높아 인공지능의 미래로 단연 주목받고 있다. 이 책은 복잡한 이론을 두루뭉술하게 설명하는 대신, 예제 코드를 직접 돌려보며 강화학습 알고리즘을 익히게 도와준다. 기본적인 텐서플로 사용법은 알지만 강화학습은 처음인 개발자를 대상으로, 주요 강화학습 알고리즘이 어떤 원리이며 어떻게 구현할 수 있는지 알려준다. 오픈AI 짐의 카트-폴, 얼어붙은 강 같은 고전 문제부터 <둠> 같은 3D 게임까지 이르기까지 흥미로운 예제를 통해 Q 러닝, MDP, DQN, A3C 등 주요 강화학습 알고리즘을 알차게 배울 수 있다.
아서 줄리아니
저자 : 아서 줄리아니
저자 : 아서 줄리아니
저자 아서 줄리아니(Arthur Juliani)는 딥러닝 및 인지과학 연구자. 오리건 대학교에서 심리학 석사 학위를 취득하고 현재는 인지뇌과학 박사 과정을 밟고 있다. 강화학습, 공간인지, 비주얼 콘셉트 개발, 지각 행동 교차 등에 관심이 많다.
트위터 @awjuliani
역자 : 송교석
역자 송교석은 고려대학교 졸업 후 카네기 멜런 대학교에서 컴퓨터과학 석사 학위를 받았다. LG전자, 동양시스템즈를 거쳐 안랩에서 10년간 근무했으며, 안랩에서 분사한 노리타운스튜디오의 대표를 역임한 바 있다. 2017년 4월에 메디픽셀(Medipixel)을 설립하여 대표를 맡고 있으며, 인공지능을 이용해 의료 영상을 분석함으로써 폐암을 조기 진단하는 프로젝트를 진행하고 있다. 옮긴 책으로 『신경망 첫걸음』, 『처음 배우는 인공지능』(이상 한빛미디어, 2017)이 있다.
목차
PART I 주요 알고리즘 및 구현
CHAPTER 1 강화학습 소개
CHAPTER 2 밴딧 문제
2.1 정책 경사
2.2 멀티암드 밴딧의 구현
CHAPTER 3 콘텍스트 밴딧
3.1 콘텍스트 밴딧 구현
CHAPTER 4 마르코프 결정 과정
4.1 기본적인 정책 경사 에이전트 구현
CHAPTER 5 Q 러닝
5.1 테이블 환경에 대한 테이블식 접근법
5.2 신경망을 통한 Q 러닝
CHAPTER 6 딥 Q 네트워크
6.1 개선 1: 합성곱 계층
6.2 개선 2: 경험 리플레이
6.3 개선 3: 별도의 타깃 네트워크
6.4 DQN을 넘어서
6.5 더블 DQN
6.6 듀얼링 DQN
6.7 모든 것을 조합하기
6.8 개선된 딥 Q 네트워크 구현
CHAPTER 7 부분관찰성과 순환 신경망
7.1 부분관찰성 문제
7.2 제한되고 변화하는 세계 이해하기
7.3 순환 신경망
7.4 텐서플로 구현을 위한 변경점
7.5 제한된 그리드 세계
7.6 DRQN 구현
CHAPTER 8 비동기적 어드밴티지 액터-크리틱
8.1 A3C의 세 가지 A
8.2 A3C 구현
8.3 [둠] 게임 플레이하기
PART II 심화 주제
CHAPTER 9 에이전트의 생각과 액션 시각화
9.1 컨트롤 센터의 인터페이스
9.2 에이전트의 머릿속 들여다보기
9.3 강화학습 컨트롤 센터 이용
CHAPTER 10 환경 모델 활용하기
10.1 모델 기반의 강화학습 구현
CHAPTER 11 탐험을 위한 액션 선택 전략
11.1 탐험은 왜 하는 것인가요?
11.2 그리디 접근법
11.3 랜덤 접근법
11.4 엡실론-그리디 접근법
11.5 볼츠만 접근법
11.6 베이지언 접근법(드롭아웃)
11.7 각 전략의 성능 비교 및 구현
11.8 고급 기법
CHAPTER 12 정책 학습을 위한 정책 학습
12.1 메타 에이전트 만들기
12.2 메타 실험
12.3 마치며
인공지능의 미래로 주목받는 강화학습 쉽고 빠르게 코드로 익히기
하루가 멀다고 새로운 기법이 나오는 딥러닝 분야에서도 단연 주목받는 기법이 강화학습입니다. 알파고의 기반이기도 한 강화학습은 사람이 자전거 타는 법을 배울 때처럼 시행착오를 겪으며 더 나은 보상을 받는 쪽으로 행동 지침을 바로잡는 학습법입니다. 게임 AI나 자율주행 등 업계 활용성이 높아 인공지능의 미래로 더욱 주목받고 있습니다.
머신러닝, 딥러닝 커리큘럼을 체계적으로 익히는 것도 좋은 학습법이지만, 당면 과제 해결을 위해 강화학습부터 공부하는 수요도 늘고 있습니다. 이 책은 개발자를 위해 텐서플로 코드 중심으로 강화학습을 설명하는 가이드북입니다. 오픈AI 짐의 환경과 [둠] 같은 게임을 예로 들어 밴딧, MDP, Q 러닝, 더블/듀얼링 DQN, DRQN, A3C 등 주요 강화학습 알고리즘을 흥미롭게 배울 수 있습니다.
책 후반부에서는 짧게나마 강화학습과 관련된 몇 가지 심화 주제를 다룹니다. 에이전트 학습 과정을 시각화해보고, 환경 모델을 활용하는 방법을 살펴보며, 엡실론-그리디, 볼츠만, 베이지언 등의 여러 액션 선택 전략을 비교해봅니다. 학습하는 정책 자체를 학습하는 메타 강화학습의 개념도 알아봅니다.
이론을 어설프게 설명하려 들지 않고, 파이썬과 텐서플로 사용법도 다루지 않습니다. 고전적인 문제부터 최근 발표된 연구에 이르기까지, 주요 강화학습 알고리즘의 원리를 이해하고 구현하는 데 집중한 책입니다.
텐서플로우로 배우는 <강화학습 첫걸음> 리뷰입니다.


강화학습은 지도학습과 비지도학습과는 달리 에이전트에게 주어진 환경에 대해 행위를 취하고 보상을 얻으면서 학습을 하기 때문에 조금은 다른 시각으로 바라 볼 필요가 있습니다.
한빛미디어의 <강화학습 첫걸음>의 1장은 주요 알고리즘 및 구현으로 되어있고, 2장은 심화 주제로 나뉘어져 있으며, 각 주요 알고리즘들의 개념들을 소개하고 이에 따른 알고리즘을 소개하고 있습니다. 다른 딥러닝 책들은 개념만 소개하거나, 코드의 일부만 주고 소개를 하는 책들이 있는데 이런 책들과는 달리 통으로 된 코드를 주요 개념에 따라서 나누고, 나누어진 코드 마다 세부적인 설명을 하였고, 또한 글로 풀어내기 어려운 개념은 복잡하지 않은 간단 명료한 그림과 함께 설명하고 있어서 강화학습을 처음 적용하는 필자에게 많은 도움이 되었습니다.
강화학습의 개념과 주요 알고리즘을 수록한 이 책의 구현은 주피터 노트북 환경의 파이썬 코드로 구성 되어있고, 텐서플로 기반으로 예제가 수록되어 있습니다.
강화학습 첫걸음 책은 핸드북으로 들고다니기에 좋은 사이즈여서 강화학습 개념을 간단하게 잡고 싶을 때 훑어보기에 좋은 책입니다. 코드를 실제 문제에 적용하는 것이 아니라 학문적으로 먼저 접근하고 싶은 사람들이 더 깊은 내용을 공부하고자 한다면 각 페이지 하단에 참고문헌들이 잘 정리되어있기 때문에 이를 참고하여 더 깊은 내용을 학습 할 수 있었습니다.
제일 좋았던 점은, 각 내용에 대한 참고할 만한 좋은 사이트 및 최근 발표된 주요 논문들의 링크를 포함하고 있다는 것입니다. 이는 간단하게 살펴보고자 하는 독자들도 고려하고, 세세하고 깊은 내용이 필요한 독자들까지 고려하였습니다.
이 책에서는 텐서플로우 기반의 파이썬 코드로 수록이 되어 있으나 텐서플로우 기본 함수에 대한 자세한 설명은 수록되어있지 않기 때문에 대상 독자를 신경망과 경사하강법 등 머신러닝 기술에 어느 정도 익숙한 독자를 대상으로 한정하였습니다.
그렇기 때문에 딥러닝에 어느정도 익숙한 사람들에게 이 책을 추천합니다.










