IT/모바일
요즘은 한 언어에서 다른 언어로 번역하는 건 그리 어렵지 않습니다. 현재 시점의 번역기는 정확도가 높아서 한국어 ‘배’가 과일 ‘pear’인지, 교통수단 ‘ship’인지 확실히 인지하죠. 인공지능은 어떻게 인간의 언어를 해독할까요?
✅순환 신경망이 텍스트를 해독하는 방법
• 미리 읽으면 좋은 글: 순환 신경망이란?
순환 신경망은 셀의 출력 정보를 입력 정보로 재사용해서 데이터의 순서를 기억합니다. 그래서 텍스트같이 순서가 있는 데이터를 처리하기에 알맞죠.
이러한 장점을 살려, 순환 신경망은 기계 번역machine translation에 활용됩니다. 어떤 언어를 다른 언어로 자동 번역해 주는 프로그램을 기계 번역이라고 합니다.
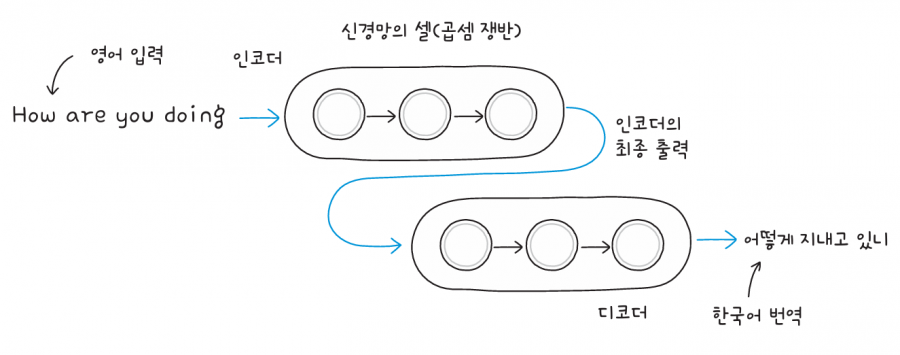
순환 신경망으로 만든 기계 번역 시스템은 일반적으로 인코더encoder와 디코더decoder로 구성됩니다. 그림과 함께 기계 번역에 활용되는 순환 신경망의 구조를 살펴볼게요.
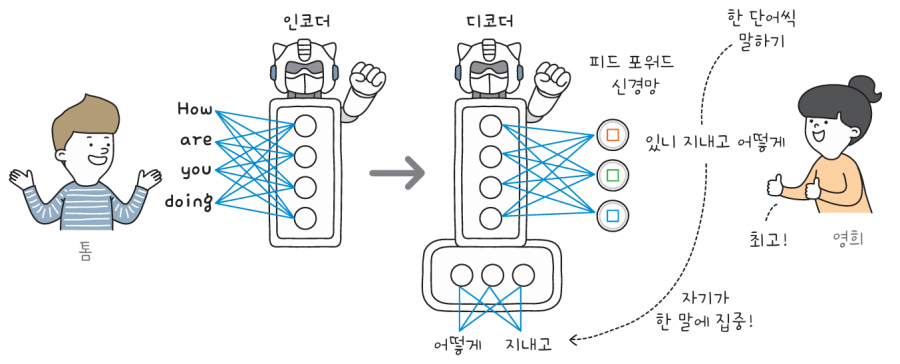
인코더는 입력된 문장을 처리합니다. 영어로 “How are you doing”을 입력하면 인코더 내부 순환 신경망의 각 셀이 문장을 한 단어씩 처리하고, 그 후 인코더의 최종 출력물을 디코더가 받아서 “어떻게 지내고 있니”라는 한국어 문장을 생성합니다.
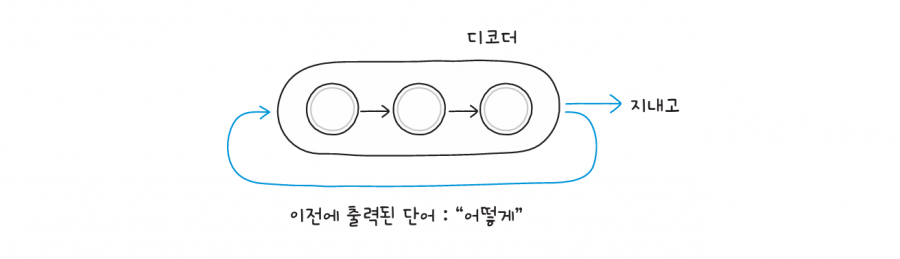
인코더가 입력 문장을 한 단어씩 처리하듯이 디코더도 한 단어씩 출력합니다. 출력된 단어가 순환하여 다시 디코더의 입력으로 사용되기 때문에, 기계 번역 서비스는 맥락에 맞는 자연스러운 문장을 만들 수 있습니다.
이때 단어는 임베딩 벡터로 변환되어 처리된다는 점에 유의하세요. 또 순환 신경망의 각 셀에는 순환되는 고리가 있지만, 여기서는 단순하게 표현하기 위해 나타내지 않았습니다. 이 과정을 상황극을 통해 단계별로 살펴볼게요.
✅인코더와 디코더
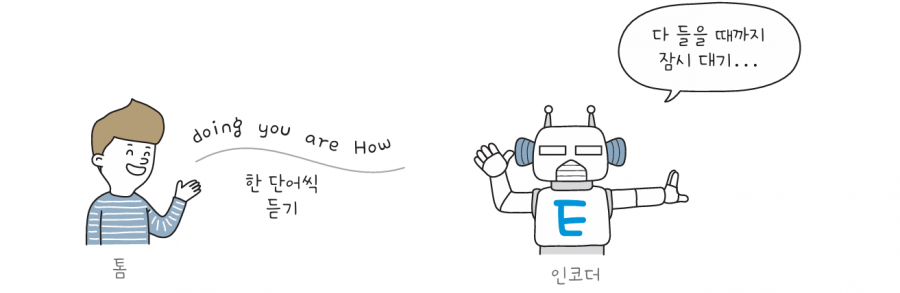
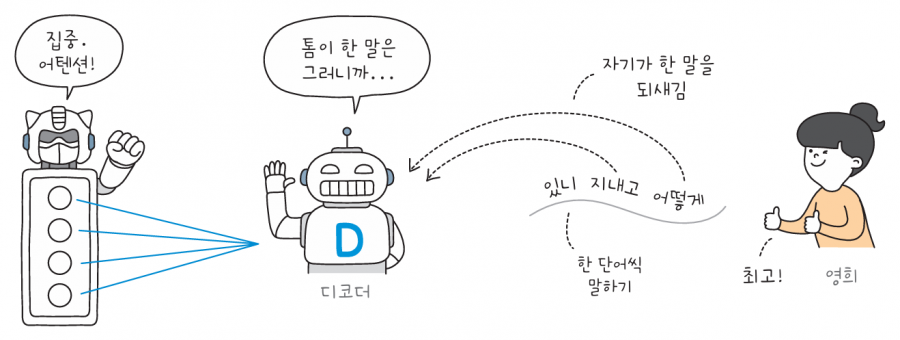
톰과 영희가 대화를 하는데, 서로 사용하는 언어가 달라 말이 통하지 않는 상황을 가정해 보겠습니다. 이때 인코더 로봇과 디코더 로봇이 톰이 한 말을 영희에게 번역해 줍니다. 먼저 톰이 한 단어씩 인코더에게 말합니다. 인코더는 문장이 끝날 때까지 잠자코 듣고만 있습니다.
톰이 말을 끝내면 인코더는 문장을 하나의 결과로 출력하여 디코더에게 전달합니다. 디코더는 톰이 말한 문장의 모든 정보가 종합적으로 담긴 결과를 받죠.
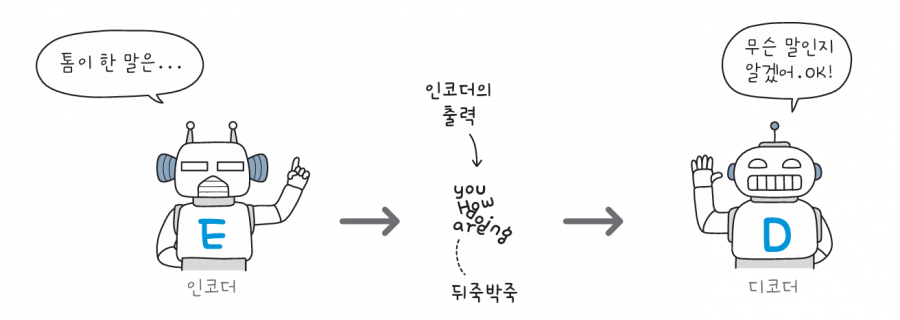
디코더는 인코더에게 받은 정보를 해석해서 한 단어씩 영희에게 전달합니다. 디코더 내부의 순환 신경망은 앞서 출력한 단어를 다시 디코더의 입력으로 재사용합니다. 이렇게 생성한 문장을 정답과 비교하고 오차를 측정하죠. 이 과정을 반복하면 언어의 패턴을 학습할 수 있습니다.
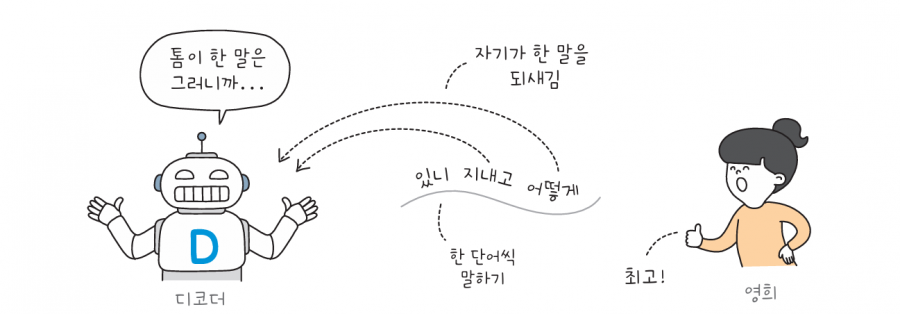
하지만 순환 신경망에는 단점이 있습니다. 순환 신경망은 텍스트를 단어 단위로 처리하므로 텍스트가 길면 그만큼 시간이 오래 걸리죠. 또 텍스트를 순서대로 받아들이기 때문에 멀리 떨어져 있는 단어는 기억하기 어렵습니다.
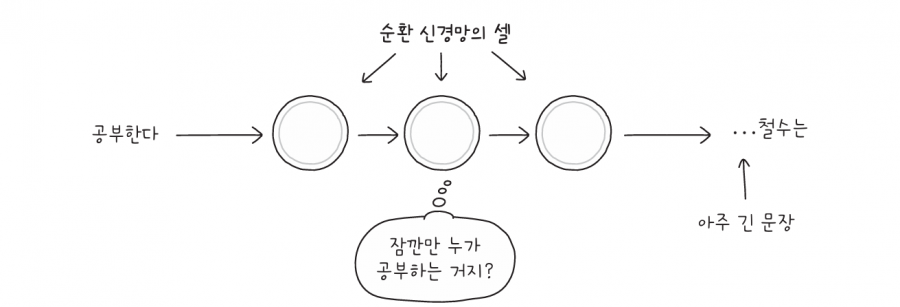
그래서 순환 신경망 기반의 기계 번역 시스템에 매우 긴 문장을 입력하면 인코더가 문장의 시작 부분을 디코더에게 잘 전달하지 못할 수도 있습니다. 이런 문제를 해결하고자 2014년, 어텐션attention이라는 새로운 기술이 개발되었습니다.
✅어텐션
2017년, 구글은 「Attention Is All You Need」라는 제목의 논문을 발표했습니다. 필요한 것은 어텐션뿐이라는 뜻이죠. 영단어 ‘Attention’은 ‘집중’이라는 뜻입니다. 말 그대로 문장 내의 어떤 단어에 얼마나 집중해야 할지를 결정하는 메커니즘입니다. 어텐션은 기계 번역과 인공지능 분야의 거대한 태풍을 불러올 날갯짓의 시작입니다. 어떻게 작동하는지 간단하게 살펴볼게요.
이번에도 톰과 영희가 대화하는 상황입니다. 인코더는 톰의 말을 듣고, 디코더가 영희에게 말을 전해줍니다. 먼저 인코더가 톰의 말을 들으면서 각 단어에 대한 정보를 저장합니다.

그다음 인코더는 어텐션 층에서 각 단어의 상관관계를 나타내는 어텐션을 계산하여 디코더에게 전달합니다. 디코더는 인코더가 계산한 상관관계를 바탕으로 어떤 단어에 집중해야 할지 결정합니다.
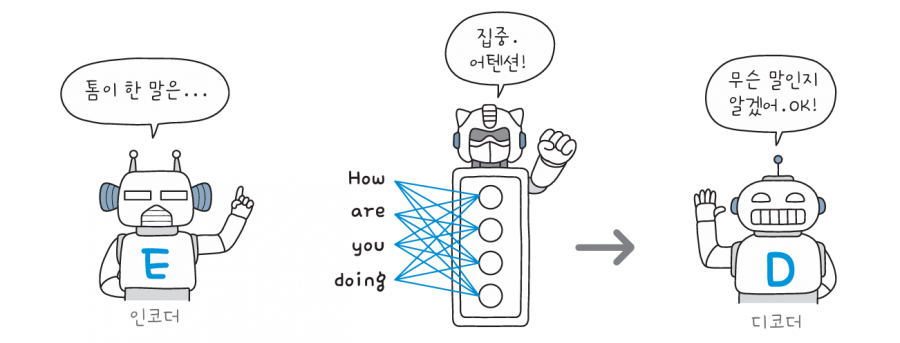
이제 디코더는 영희에게 전할 단어를 생성하면서 매번 이 어텐션을 참고합니다. 어텐션 덕분에 이제는 긴 문장에서도 필요하다면 맨 처음 단어에 주의를 기울일 수 있습니다.
2014년 당시에는 어텐션 메커니즘이 자연어 처리 분야에서 이토록 거대한 태풍을 일으키리라 예상하지 못했습니다. 하지만 2017년, 구글이 인코더-디코더 구조에서 순환 신경망을 완전히 걷어 내고 어텐션 메커니즘을 활용해 구현한 기계 번역 시스템을 제안했습니다. 이 모델이 바로 트랜스포머죠.
✅트랜스포머
트랜스포머transformer는 어텐션 메커니즘과 피드 포워드 신경망으로 구현하여 성능의 혁신을 가져온 모델입니다. 각종 자연어 처리 작업에서 트랜스포머가 기존의 순환 신경망을 대체하기 시작했죠.
트랜스포머 모델의 기본적인 구조는 인코더-디코더 구조와 유사합니다. 다만 트랜스포머의 인코더에는 순환 신경망이 없으므로, 더 이상 입력된 문장을 순서대로 들을 필요가 없습니다. 문장을 한꺼번에 듣고 어텐션을 계산한 뒤, 이를 피드 포워드 신경망에 통과시킵니다.
디코더 역시 순환 신경망 대신 피드 포워드 신경망을 사용하여, 인코더의 출력을 받아 단어를 하나씩 생성합니다. 이때도 마찬가지로 어텐션 메커니즘을 사용하여 디코더가 이미 생성한 단어 중에서 주의를 기울일 단어를 결정합니다. 트랜스포머의 인코더와 디코더에 있는 어텐션 메커니즘은 어떤 단어에 집중할지 스스로 결정하기 때문에 이를 특별히 셀프 어텐션self attention이라고 합니다.
이와 같은 인코더-디코더 구조의 트랜스포머 모델은 기계 번역 시스템이나 챗봇 등을 만드는 데 주로 사용됩니다. 놀라운 점은 트랜스포머 모델에서 인코더와 디코더를 분리할 수 있다는 것입니다.
인코더를 사용한 모델이 문장을 분류하는 데 뛰어난 반면, 디코더를 사용하는 모델은 텍스트 생성에 능합니다. 예를 들어 구글의 BERT*와 페이스북의 RoBERTa**는 트랜스포머의 인코더만을 사용하여 입력된 문장을 분류합니다. 한편, 오픈AI는 트랜스포머의 디코더만을 사용한 모델 개발을 주도하고 있습니다. 그렇게 개발된 것이 GPT 모델 시리즈입니다.
* BERT(Bidirectional Encoder Representations from Transformers): 구글이 공개한 인공지능 언어 모델. 2018년 11월에 공개되었다.
** RoBERTa(Robustly Optimized BERT Approach): 페이스북이 개발한 BERT의 변형 모델. 자연어 처리 작업에서 성능이 개선되었다.
위 콘텐츠는 『인공지능 전문가가 알려 주는 챗GPT로 대화하는 기술』을 재구성하여 작성되었습니다.

관련 콘텐츠
![[2025 수능 국어 지문 출제] 디퓨전 모델(diffusion model) 쉽게 이해하기](/data/cms/CMS6968709109_thumb.png)
![[챗GPT] 그림으로 배우는 인공 신경망의 원리: 경사 하강법, 피드 포워드 신경망, 순환 신경망](/data/cms/CMS6704086139_thumb.jpg)

최신 콘텐츠